 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Fairness: Unveiling LLM's Potential for Fairness-Aware Classification
Feb 28, 2024



Employing Large Language Models (LLM) in various downstream applications such as classification is crucial, especially for smaller companies lacking the expertise and resources required for fine-tuning a model. Fairness in LLMs helps ensure inclusivity, equal representation based on factors such as race, gender and promotes responsible AI deployment. As the use of LLMs has become increasingly prevalent, it is essential to assess whether LLMs can generate fair outcomes when subjected to considerations of fairness. In this study, we introduce a framework outlining fairness regulations aligned with various fairness definitions, with each definition being modulated by varying degrees of abstraction. We explore the configuration for in-context learning and the procedure for selecting in-context demonstrations using RAG, while incorporating fairness rules into the process. Experiments conducted with different LLMs indicate that GPT-4 delivers superior results in terms of both accuracy and fairness compared to other models. This work is one of the early attempts to achieve fairness in prediction tasks by utilizing LLMs through in-context learning.
Towards Fairness in Online Service with k Servers and its Application on Fair Food Delivery
Dec 18, 2023The k-SERVER problem is one of the most prominent problems in online algorithms with several variants and extensions. However, simplifying assumptions like instantaneous server movements and zero service time has hitherto limited its applicability to real-world problems. In this paper, we introduce a realistic generalization of k-SERVER without such assumptions - the k-FOOD problem, where requests with source-destination locations and an associated pickup time window arrive in an online fashion, and each has to be served by exactly one of the available k servers. The k-FOOD problem offers the versatility to model a variety of real-world use cases such as food delivery, ride sharing, and quick commerce. Moreover, motivated by the need for fairness in online platforms, we introduce the FAIR k-FOOD problem with the max-min objective. We establish that both k-FOOD and FAIR k-FOOD problems are strongly NP-hard and develop an optimal offline algorithm that arises naturally from a time-expanded flow network. Subsequently, we propose an online algorithm DOC4FOOD involving virtual movements of servers to the nearest request location. Experiments on a real-world food-delivery dataset, alongside synthetic datasets, establish the efficacy of the proposed algorithm against state-of-the-art fair food delivery algorithms.
Gigs with Guarantees: Achieving Fair Wage for Food Delivery Workers
May 07, 2022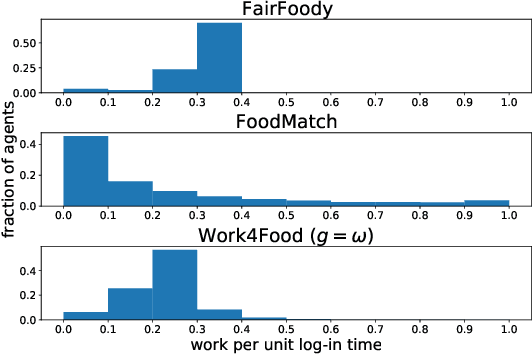

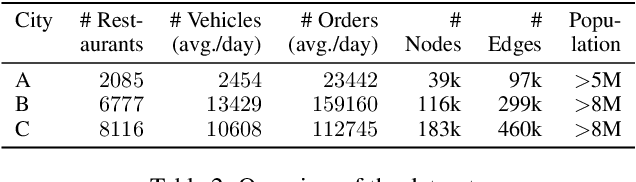
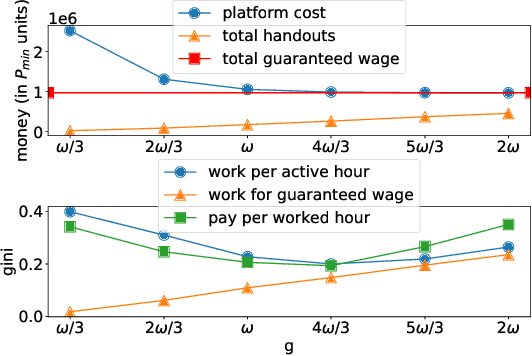
With the increasing popularity of food delivery platforms, it has become pertinent to look into the working conditions of the 'gig' workers in these platforms, especially providing them fair wages, reasonable working hours, and transparency on work availability. However, any solution to these problems must not degrade customer experience and be cost-effective to ensure that platforms are willing to adopt them. We propose WORK4FOOD, which provides income guarantees to delivery agents, while minimizing platform costs and ensuring customer satisfaction. WORK4FOOD ensures that the income guarantees are met in such a way that it does not lead to increased working hours or degrade environmental impact. To incorporate these objectives, WORK4FOOD balances supply and demand by controlling the number of agents in the system and providing dynamic payment guarantees to agents based on factors such as agent location, ratings, etc. We evaluate WORK4FOOD on a real-world dataset from a leading food delivery platform and establish its advantages over the state of the art in terms of the multi-dimensional objectives at hand.
Scheduling Virtual Conferences Fairly: Achieving Equitable Participant and Speaker Satisfaction
Apr 26, 2022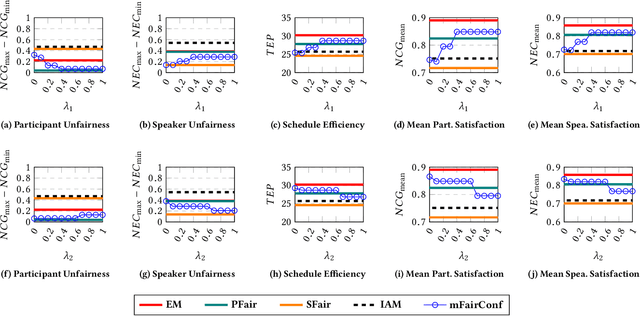
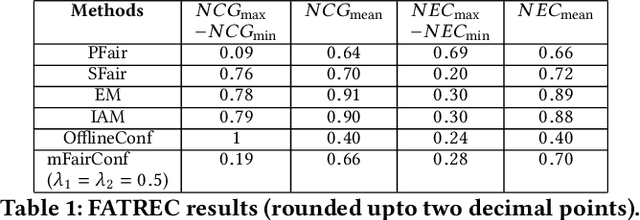
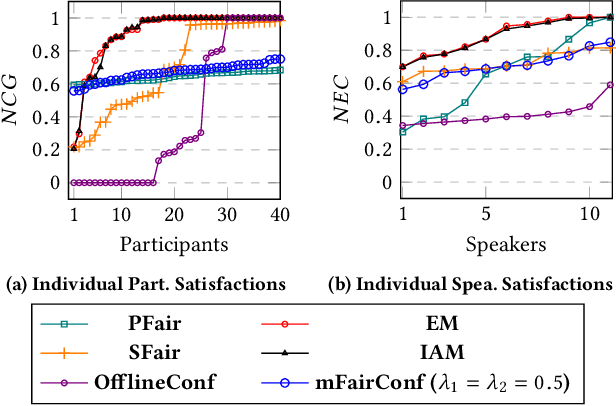
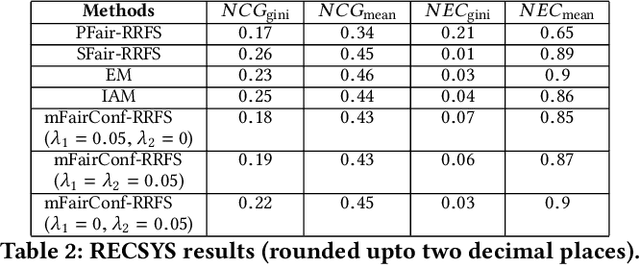
Recently, almost all conferences have moved to virtual mode due to the pandemic-induced restrictions on travel and social gathering. Contrary to in-person conferences, virtual conferences face the challenge of efficiently scheduling talks, accounting for the availability of participants from different timezones and their interests in attending different talks. A natural objective for conference organizers is to maximize efficiency, e.g., total expected audience participation across all talks. However, we show that optimizing for efficiency alone can result in an unfair virtual conference schedule, where individual utilities for participants and speakers can be highly unequal. To address this, we formally define fairness notions for participants and speakers, and derive suitable objectives to account for them. As the efficiency and fairness objectives can be in conflict with each other, we propose a joint optimization framework that allows conference organizers to design schedules that balance (i.e., allow trade-offs) among efficiency, participant fairness and speaker fairness objectives. While the optimization problem can be solved using integer programming to schedule smaller conferences, we provide two scalable techniques to cater to bigger conferences. Extensive evaluations over multiple real-world datasets show the efficacy and flexibility of our proposed approaches.
FaiRIR: Mitigating Exposure Bias from Related Item Recommendations in Two-Sided Platforms
Apr 01, 2022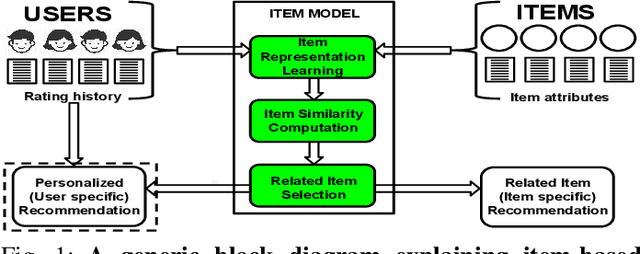
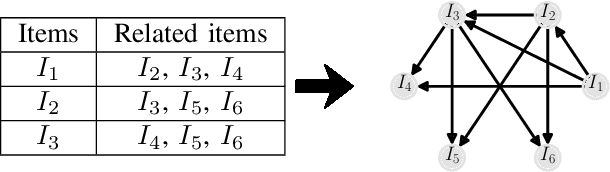
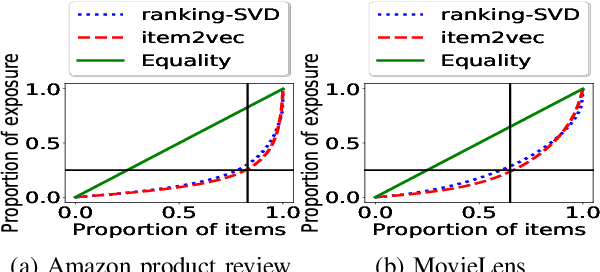
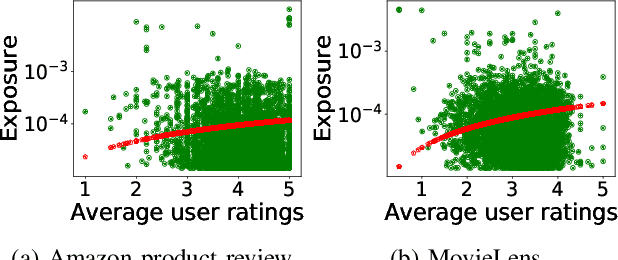
Related Item Recommendations (RIRs) are ubiquitous in most online platforms today, including e-commerce and content streaming sites. These recommendations not only help users compare items related to a given item, but also play a major role in bringing traffic to individual items, thus deciding the exposure that different items receive. With a growing number of people depending on such platforms to earn their livelihood, it is important to understand whether different items are receiving their desired exposure. To this end, our experiments on multiple real-world RIR datasets reveal that the existing RIR algorithms often result in very skewed exposure distribution of items, and the quality of items is not a plausible explanation for such skew in exposure. To mitigate this exposure bias, we introduce multiple flexible interventions (FaiRIR) in the RIR pipeline. We instantiate these mechanisms with two well-known algorithms for constructing related item recommendations -- rating-SVD and item2vec -- and show on real-world data that our mechanisms allow for a fine-grained control on the exposure distribution, often at a small or no cost in terms of recommendation quality, measured in terms of relatedness and user satisfaction.
Alexa, in you, I trust! Fairness and Interpretability Issues in E-commerce Search through Smart Speakers
Feb 09, 2022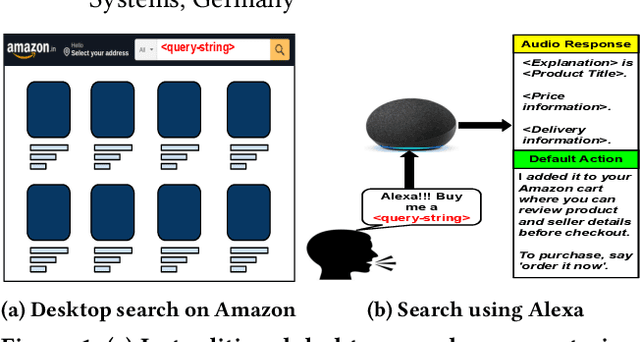
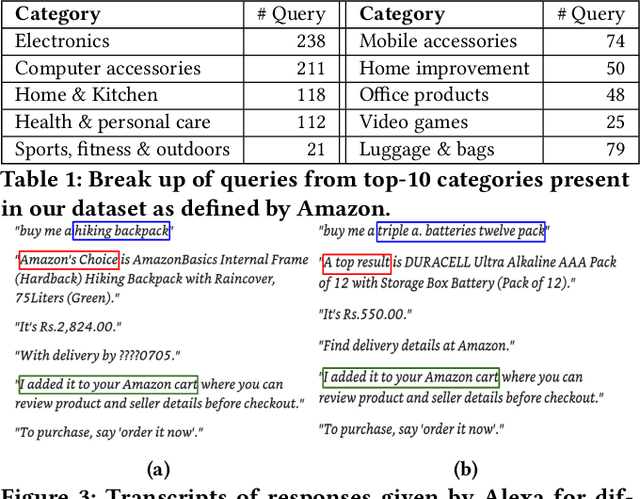
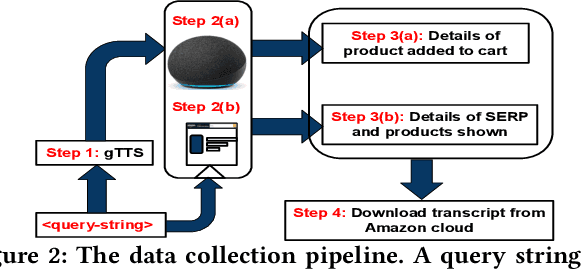
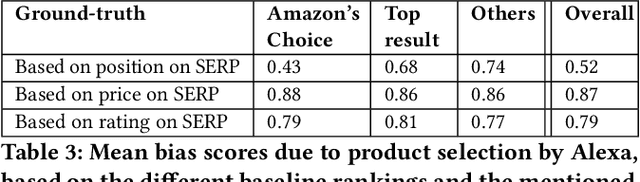
In traditional (desktop) e-commerce search, a customer issues a specific query and the system returns a ranked list of products in order of relevance to the query. An increasingly popular alternative in e-commerce search is to issue a voice-query to a smart speaker (e.g., Amazon Echo) powered by a voice assistant (VA, e.g., Alexa). In this situation, the VA usually spells out the details of only one product, an explanation citing the reason for its selection, and a default action of adding the product to the customer's cart. This reduced autonomy of the customer in the choice of a product during voice-search makes it necessary for a VA to be far more responsible and trustworthy in its explanation and default action. In this paper, we ask whether the explanation presented for a product selection by the Alexa VA installed on an Amazon Echo device is consistent with human understanding as well as with the observations on other traditional mediums (e.g., desktop ecommerce search). Through a user survey, we find that in 81% cases the interpretation of 'a top result' by the users is different from that of Alexa. While investigating for the fairness of the default action, we observe that over a set of as many as 1000 queries, in nearly 68% cases, there exist one or more products which are more relevant (as per Amazon's own desktop search results) than the product chosen by Alexa. Finally, we conducted a survey over 30 queries for which the Alexa-selected product was different from the top desktop search result, and observed that in nearly 73% cases, the participants preferred the top desktop search result as opposed to the product chosen by Alexa. Our results raise several concerns and necessitates more discussions around the related fairness and interpretability issues of VAs for e-commerce search.
Towards Fair Recommendation in Two-Sided Platforms
Dec 26, 2021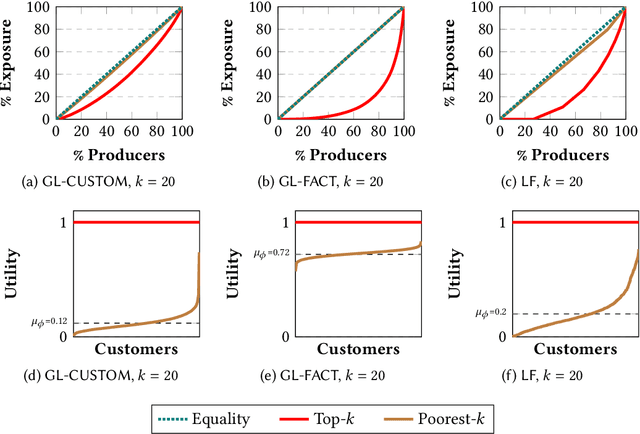
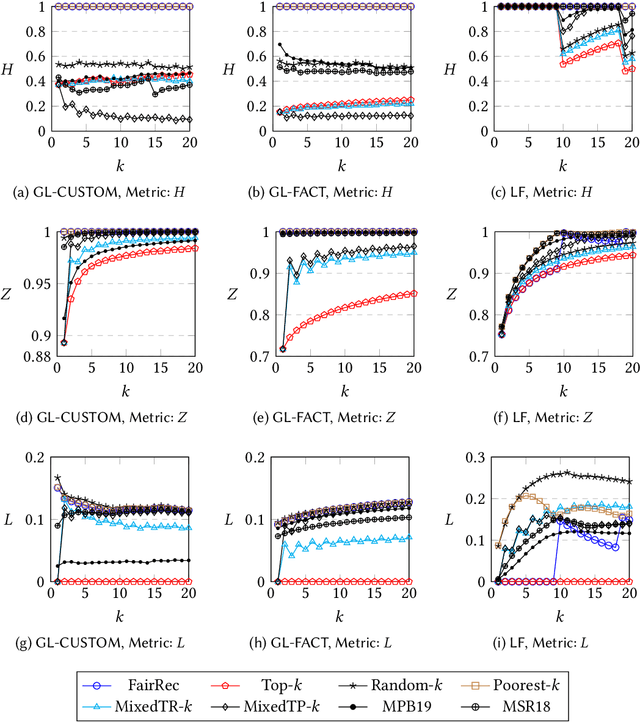
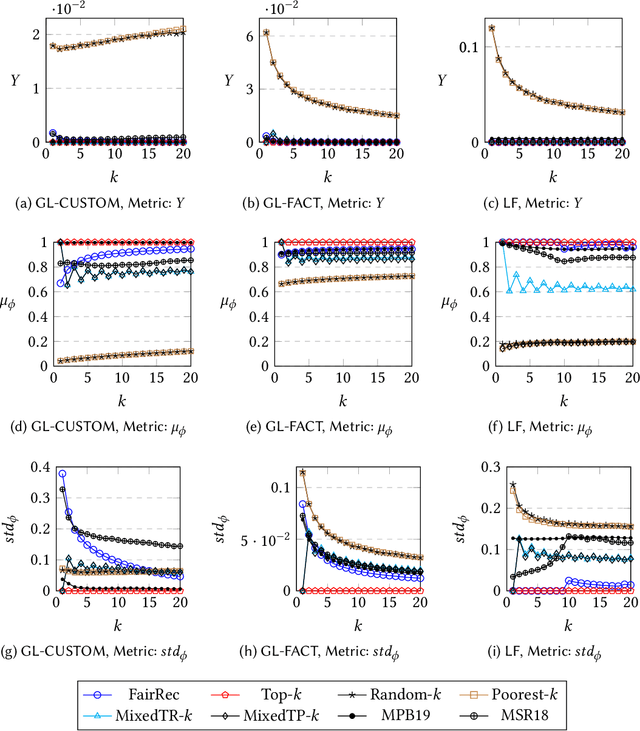
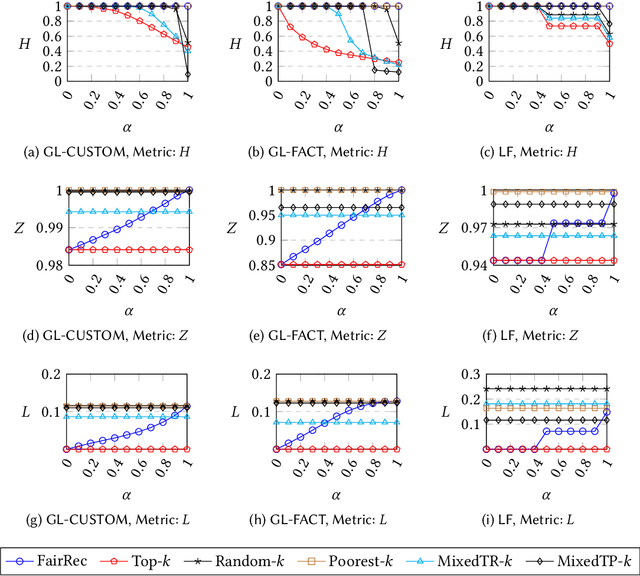
Many online platforms today (such as Amazon, Netflix, Spotify, LinkedIn, and AirBnB) can be thought of as two-sided markets with producers and customers of goods and services. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reinforces the fact that such customer-centric design of these services may lead to unfair distribution of exposure to the producers, which may adversely impact their well-being. On the other hand, a pure producer-centric design might become unfair to the customers. As more and more people are depending on such platforms to earn a living, it is important to ensure fairness to both producers and customers. In this work, by mapping a fair personalized recommendation problem to a constrained version of the problem of fairly allocating indivisible goods, we propose to provide fairness guarantees for both sides. Formally, our proposed {\em FairRec} algorithm guarantees Maxi-Min Share ($\alpha$-MMS) of exposure for the producers, and Envy-Free up to One Item (EF1) fairness for the customers. Extensive evaluations over multiple real-world datasets show the effectiveness of {\em FairRec} in ensuring two-sided fairness while incurring a marginal loss in overall recommendation quality. Finally, we present a modification of FairRec (named as FairRecPlus) that at the cost of additional computation time, improves the recommendation performance for the customers, while maintaining the same fairness guarantees.
Fairness for Whom? Understanding the Reader's Perception of Fairness in Text Summarization
Feb 02, 2021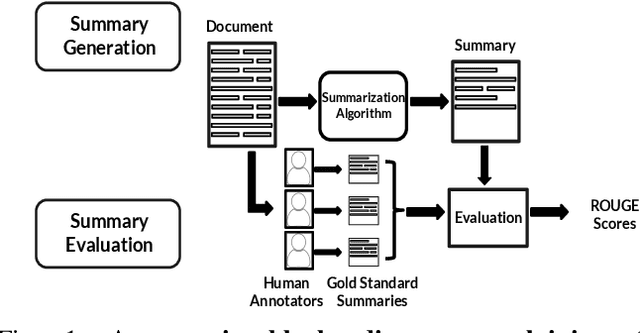

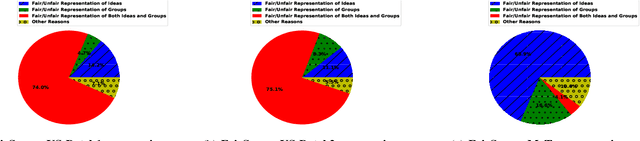

With the surge in user-generated textual information, there has been a recent increase in the use of summarization algorithms for providing an overview of the extensive content. Traditional metrics for evaluation of these algorithms (e.g. ROUGE scores) rely on matching algorithmic summaries to human-generated ones. However, it has been shown that when the textual contents are heterogeneous, e.g., when they come from different socially salient groups, most existing summarization algorithms represent the social groups very differently compared to their distribution in the original data. To mitigate such adverse impacts, some fairness-preserving summarization algorithms have also been proposed. All of these studies have considered normative notions of fairness from the perspective of writers of the contents, neglecting the readers' perceptions of the underlying fairness notions. To bridge this gap, in this work, we study the interplay between the fairness notions and how readers perceive them in textual summaries. Through our experiments, we show that reader's perception of fairness is often context-sensitive. Moreover, standard ROUGE evaluation metrics are unable to quantify the perceived (un)fairness of the summaries. To this end, we propose a human-in-the-loop metric and an automated graph-based methodology to quantify the perceived bias in textual summaries. We demonstrate their utility by quantifying the (un)fairness of several summaries of heterogeneous socio-political microblog datasets.
When the Umpire is also a Player: Bias in Private Label Product Recommendations on E-commerce Marketplaces
Feb 02, 2021
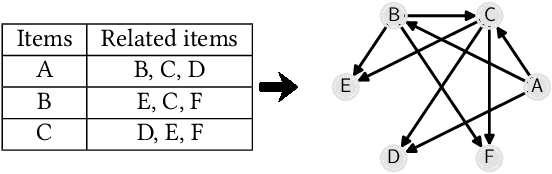
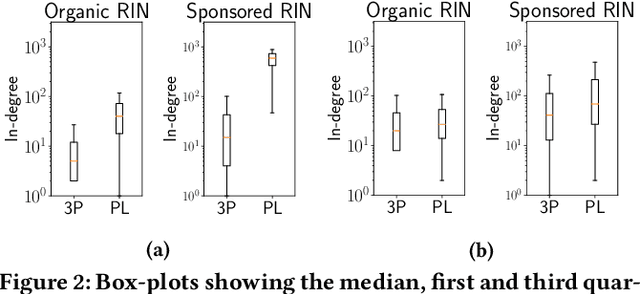
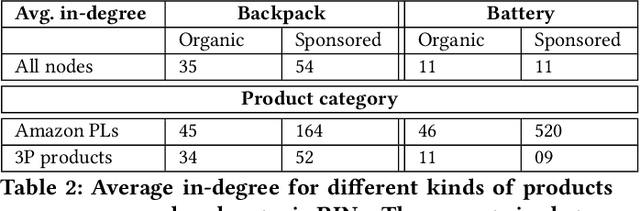
Algorithmic recommendations mediate interactions between millions of customers and products (in turn, their producers and sellers) on large e-commerce marketplaces like Amazon. In recent years, the producers and sellers have raised concerns about the fairness of black-box recommendation algorithms deployed on these marketplaces. Many complaints are centered around marketplaces biasing the algorithms to preferentially favor their own `private label' products over competitors. These concerns are exacerbated as marketplaces increasingly de-emphasize or replace `organic' recommendations with ad-driven `sponsored' recommendations, which include their own private labels. While these concerns have been covered in popular press and have spawned regulatory investigations, to our knowledge, there has not been any public audit of these marketplace algorithms. In this study, we bridge this gap by performing an end-to-end systematic audit of related item recommendations on Amazon. We propose a network-centric framework to quantify and compare the biases across organic and sponsored related item recommendations. Along a number of our proposed bias measures, we find that the sponsored recommendations are significantly more biased toward Amazon private label products compared to organic recommendations. While our findings are primarily interesting to producers and sellers on Amazon, our proposed bias measures are generally useful for measuring link formation bias in any social or content networks.
On Fair Virtual Conference Scheduling: Achieving Equitable Participant and Speaker Satisfaction
Oct 24, 2020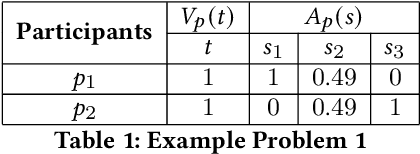
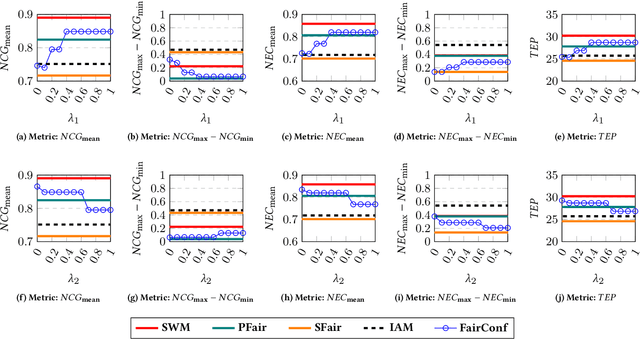
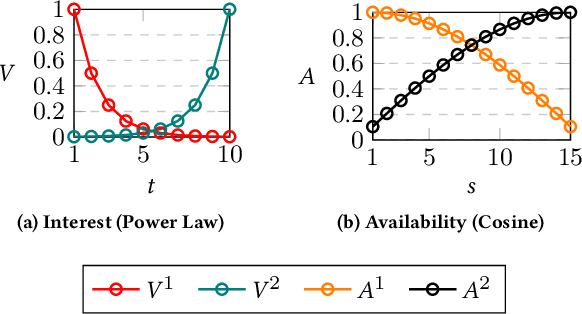
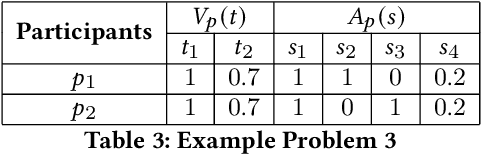
The (COVID-19) pandemic-induced restrictions on travel and social gatherings have prompted most conference organizers to move their events online. However, in contrast to physical conferences, virtual conferences face a challenge in efficiently scheduling talks, accounting for the availability of participants from different time-zones as well as their interests in attending different talks. In such settings, a natural objective for the conference organizers would be to maximize some global welfare measure, such as the total expected audience participation across all talks. However, we show that optimizing for global welfare could result in a schedule that is unfair to the stakeholders, i.e., the individual utilities for participants and speakers can be highly unequal. To address the fairness concerns, we formally define fairness notions for participants and speakers, and subsequently derive suitable fairness objectives for them. We show that the welfare and fairness objectives can be in conflict with each other, and there is a need to maintain a balance between these objective while caring for them simultaneously. Thus, we propose a joint optimization framework that allows conference organizers to design talk schedules that balance (i.e., allow trade-offs) between global welfare, participant fairness and the speaker fairness objectives. We show that the optimization problem can be solved using integer linear programming, and empirically evaluate the necessity and benefits of such joint optimization approach in virtual conference scheduling.