 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Metabolic Syndrome Prediction with Hybrid Data Balancing and Counterfactuals
Apr 09, 2025



Metabolic Syndrome (MetS) is a cluster of interrelated risk factors that significantly increases the risk of cardiovascular diseases and type 2 diabetes. Despite its global prevalence, accurate prediction of MetS remains challenging due to issues such as class imbalance, data scarcity, and methodological inconsistencies in existing studies. In this paper, we address these challenges by systematically evaluating and optimizing machine learning (ML) models for MetS prediction, leveraging advanced data balancing techniques and counterfactual analysis. Multiple ML models, including XGBoost, Random Forest, TabNet, etc., were trained and compared under various data balancing techniques such as random oversampling (ROS), SMOTE, ADASYN, and CTGAN. Additionally, we introduce MetaBoost, a novel hybrid framework that integrates SMOTE, ADASYN, and CTGAN, optimizing synthetic data generation through weighted averaging and iterative weight tuning to enhance the model's performance (achieving a 1.14% accuracy improvement over individual balancing techniques). A comprehensive counterfactual analysis is conducted to quantify feature-level changes required to shift individuals from high-risk to low-risk categories. The results indicate that blood glucose (50.3%) and triglycerides (46.7%) were the most frequently modified features, highlighting their clinical significance in MetS risk reduction. Additionally, probabilistic analysis shows elevated blood glucose (85.5% likelihood) and triglycerides (74.9% posterior probability) as the strongest predictors. This study not only advances the methodological rigor of MetS prediction but also provides actionable insights for clinicians and researchers, highlighting the potential of ML in mitigating the public health burden of metabolic syndrome.
AIMI: Leveraging Future Knowledge and Personalization in Sparse Event Forecasting for Treatment Adherence
Mar 20, 2025



Adherence to prescribed treatments is crucial for individuals with chronic conditions to avoid costly or adverse health outcomes. For certain patient groups, intensive lifestyle interventions are vital for enhancing medication adherence. Accurate forecasting of treatment adherence can open pathways to developing an on-demand intervention tool, enabling timely and personalized support. With the increasing popularity of smartphones and wearables, it is now easier than ever to develop and deploy smart activity monitoring systems. However, effective forecasting systems for treatment adherence based on wearable sensors are still not widely available. We close this gap by proposing Adherence Forecasting and Intervention with Machine Intelligence (AIMI). AIMI is a knowledge-guided adherence forecasting system that leverages smartphone sensors and previous medication history to estimate the likelihood of forgetting to take a prescribed medication. A user study was conducted with 27 participants who took daily medications to manage their cardiovascular diseases. We designed and developed CNN and LSTM-based forecasting models with various combinations of input features and found that LSTM models can forecast medication adherence with an accuracy of 0.932 and an F-1 score of 0.936. Moreover, through a series of ablation studies involving convolutional and recurrent neural network architectures, we demonstrate that leveraging known knowledge about future and personalized training enhances the accuracy of medication adherence forecasting. Code available: https://github.com/ab9mamun/AIMI.
GlucoLens: Explainable Postprandial Blood Glucose Prediction from Diet and Physical Activity
Mar 05, 2025



Postprandial hyperglycemia, marked by the blood glucose level exceeding the normal range after meals, is a critical indicator of progression toward type 2 diabetes in prediabetic and healthy individuals. A key metric for understanding blood glucose dynamics after eating is the postprandial area under the curve (PAUC). Predicting PAUC in advance based on a person's diet and activity level and explaining what affects postprandial blood glucose could allow an individual to adjust their lifestyle accordingly to maintain normal glucose levels. In this paper, we propose GlucoLens, an explainable machine learning approach to predict PAUC and hyperglycemia from diet, activity, and recent glucose patterns. We conducted a five-week user study with 10 full-time working individuals to develop and evaluate the computational model. Our machine learning model takes multimodal data including fasting glucose, recent glucose, recent activity, and macronutrient amounts, and provides an interpretable prediction of the postprandial glucose pattern. Our extensive analyses of the collected data revealed that the trained model achieves a normalized root mean squared error (NRMSE) of 0.123. On average, GlucoLense with a Random Forest backbone provides a 16% better result than the baseline models. Additionally, GlucoLens predicts hyperglycemia with an accuracy of 74% and recommends different options to help avoid hyperglycemia through diverse counterfactual explanations. Code available: https://github.com/ab9mamun/GlucoLens.
Freezing of Gait Detection Using Gramian Angular Fields and Federated Learning from Wearable Sensors
Nov 19, 2024



Freezing of gait (FOG) is a debilitating symptom of Parkinson's disease (PD) that impairs mobility and safety. Traditional detection methods face challenges due to intra and inter-patient variability, and most systems are tested in controlled settings, limiting their real-world applicability. Addressing these gaps, we present FOGSense, a novel FOG detection system designed for uncontrolled, free-living conditions. It uses Gramian Angular Field (GAF) transformations and federated deep learning to capture temporal and spatial gait patterns missed by traditional methods. We evaluated our FOGSense system using a public PD dataset, 'tdcsfog'. FOGSense improves accuracy by 10.4% over a single-axis accelerometer, reduces failure points compared to multi-sensor systems, and demonstrates robustness to missing values. The federated architecture allows personalized model adaptation and efficient smartphone synchronization during off-peak hours, making it effective for long-term monitoring as symptoms evolve. Overall, FOGSense achieves a 22.2% improvement in F1-score compared to state-of-the-art methods, along with enhanced sensitivity for FOG episode detection. Code is available: https://github.com/shovito66/FOGSense.
Use of What-if Scenarios to Help Explain Artificial Intelligence Models for Neonatal Health
Oct 12, 2024



Early detection of intrapartum risk enables interventions to potentially prevent or mitigate adverse labor outcomes such as cerebral palsy. Currently, there is no accurate automated system to predict such events to assist with clinical decision-making. To fill this gap, we propose "Artificial Intelligence (AI) for Modeling and Explaining Neonatal Health" (AIMEN), a deep learning framework that not only predicts adverse labor outcomes from maternal, fetal, obstetrical, and intrapartum risk factors but also provides the model's reasoning behind the predictions made. The latter can provide insights into what modifications in the input variables of the model could have changed the predicted outcome. We address the challenges of imbalance and small datasets by synthesizing additional training data using Adaptive Synthetic Sampling (ADASYN) and Conditional Tabular Generative Adversarial Networks (CTGAN). AIMEN uses an ensemble of fully-connected neural networks as the backbone for its classification with the data augmentation supported by either ADASYN or CTGAN. AIMEN, supported by CTGAN, outperforms AIMEN supported by ADASYN in classification. AIMEN can predict a high risk for adverse labor outcomes with an average F1 score of 0.784. It also provides counterfactual explanations that can be achieved by changing 2 to 3 attributes on average. Resources available: https://github.com/ab9mamun/AIMEN.
Multimodal Physical Activity Forecasting in Free-Living Clinical Settings: Hunting Opportunities for Just-in-Time Interventions
Oct 12, 2024



Objective: This research aims to develop a lifestyle intervention system, called MoveSense, that forecasts a patient's activity behavior to allow for early and personalized interventions in real-world clinical environments. Methods: We conducted two clinical studies involving 58 prediabetic veterans and 60 patients with obstructive sleep apnea to gather multimodal behavioral data using wearable devices. We develop multimodal long short-term memory (LSTM) network models, which are capable of forecasting the number of step counts of a patient up to 24 hours in advance by examining data from activity and engagement modalities. Furthermore, we design goal-based forecasting models to predict whether a person's next-day steps will be over a certain threshold. Results: Multimodal LSTM with early fusion achieves 33% and 37% lower mean absolute errors than linear regression and ARIMA respectively on the prediabetes dataset. LSTM also outperforms linear regression and ARIMA with a margin of 13% and 32% on the sleep dataset. Multimodal forecasting models also perform with 72% and 79% accuracy on the prediabetes dataset and sleep dataset respectively on goal-based forecasting. Conclusion: Our experiments conclude that multimodal LSTM models with early fusion are better than multimodal LSTM with late fusion and unimodal LSTM models and also than ARIMA and linear regression models. Significance: We address an important and challenging task of time-series forecasting in uncontrolled environments. Effective forecasting of a person's physical activity can aid in designing adaptive behavioral interventions to keep the user engaged and adherent to a prescribed routine.
ActSafe: Predicting Violations of Medical Temporal Constraints for Medication Adherence
Jan 17, 2023Prescription medications often impose temporal constraints on regular health behaviors (RHBs) of patients, e.g., eating before taking medication. Violations of such medical temporal constraints (MTCs) can result in adverse effects. Detecting and predicting such violations before they occur can help alert the patient. We formulate the problem of modeling MTCs and develop a proof-of-concept solution, ActSafe, to predict violations of MTCs well ahead of time. ActSafe utilizes a context-free grammar based approach for extracting and mapping MTCs from patient education materials. It also addresses the challenges of accurately predicting RHBs central to MTCs (e.g., medication intake). Our novel behavior prediction model, HERBERT , utilizes a basis vectorization of time series that is generalizable across temporal scale and duration of behaviors, explicitly capturing the dependency between temporally collocated behaviors. Based on evaluation using a real-world RHB dataset collected from 28 patients in uncontrolled environments, HERBERT outperforms baseline models with an average of 51% reduction in root mean square error. Based on an evaluation involving patients with chronic conditions, ActSafe can predict MTC violations a day ahead of time with an average F1 score of 0.86.
DBATES: DataBase of Audio features, Text, and visual Expressions in competitive debate Speeches
Mar 26, 2021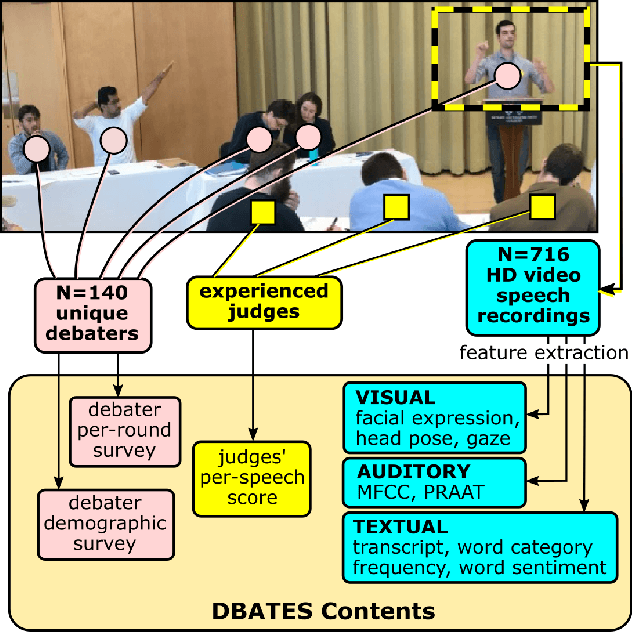
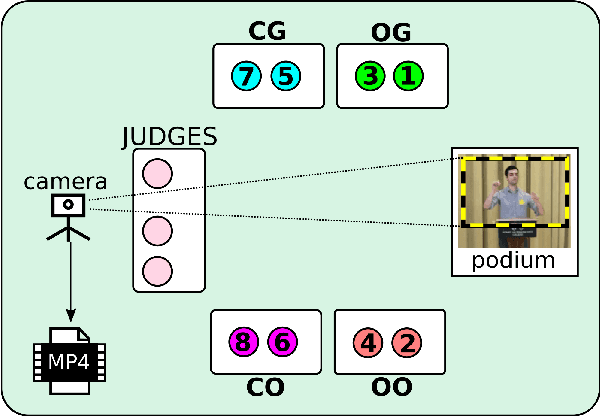
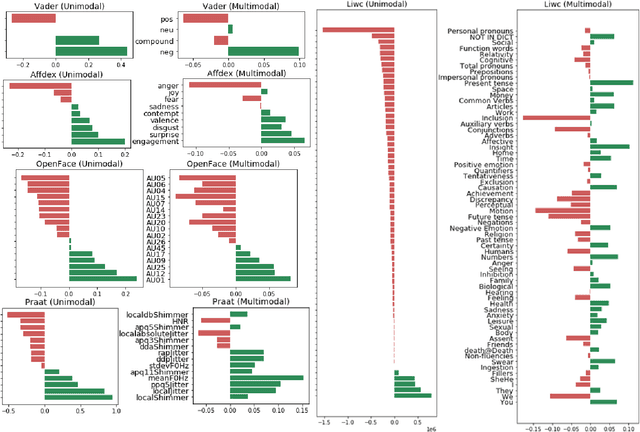

In this work, we present a database of multimodal communication features extracted from debate speeches in the 2019 North American Universities Debate Championships (NAUDC). Feature sets were extracted from the visual (facial expression, gaze, and head pose), audio (PRAAT), and textual (word sentiment and linguistic category) modalities of raw video recordings of competitive collegiate debaters (N=717 6-minute recordings from 140 unique debaters). Each speech has an associated competition debate score (range: 67-96) from expert judges as well as competitor demographic and per-round reflection surveys. We observe the fully multimodal model performs best in comparison to models trained on various compositions of modalities. We also find that the weights of some features (such as the expression of joy and the use of the word we) change in direction between the aforementioned models. We use these results to highlight the value of a multimodal dataset for studying competitive, collegiate debate.