 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
Analyzing How Text-to-Image Models Represent Nationalities in Everyday Tasks
Apr 08, 2025The primary objective of this paper is to investigate how a popular Text-to-Image (T2I) model represents people from 208 different nationalities when prompted to generate images of individuals performing typical everyday tasks. Two scenarios were developed, and images were generated based on input prompts that specified nationalities. The results show that in one scenario, the majority of images, and in the other, a substantial portion, depict individuals wearing traditional attire. This suggests that the model emphasizes such characteristics even when they are impractical for the given task. A statistically significant relationship was observed between this representation pattern and the regions associated with the specified countries. This indicates that the issue disproportionately affects certain areas, particularly the Middle East & North Africa and Sub-Saharan Africa. A notable association with income groups was also found. CLIP was used to measure alignment scores between generated images and various prompts and captions. The findings indicate statistically significant higher scores for images featuring individuals in traditional attire in one scenario. The study also examined revised prompts (additional contextual information automatically added to the original input prompts) to assess their potential influence on how individuals are represented in the generated images, finding that the word "traditional" was commonly added to revised prompts. These findings provide valuable insights into how T2I models represent individuals from various countries and highlight potential areas for improvement in future models.
Comparing Open Arabic Named Entity Recognition Tools
May 12, 2022
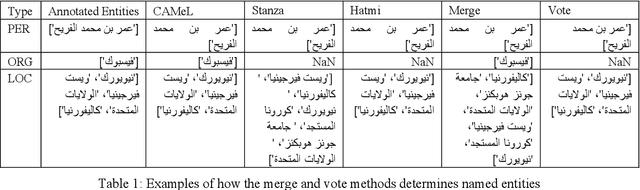
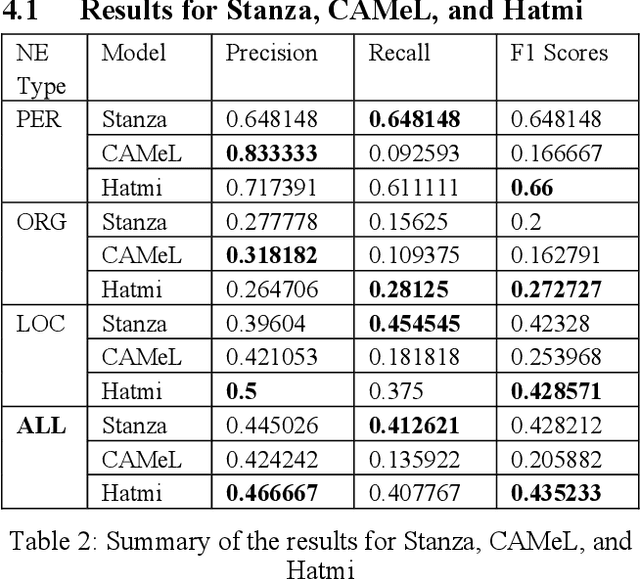
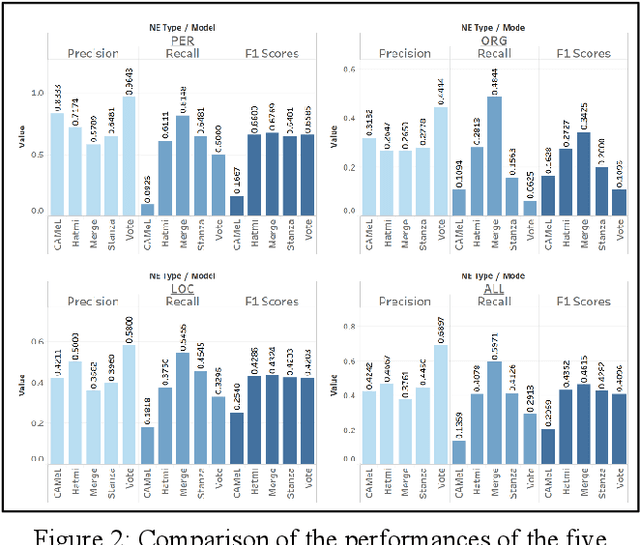
The main objective of this paper is to compare and evaluate the performances of three open Arabic NER tools: CAMeL, Hatmi, and Stanza. We collected a corpus consisting of 30 articles written in MSA and manually annotated all the entities of the person, organization, and location types at the article (document) level. Our results suggest a similarity between Stanza and Hatmi with the latter receiving the highest F1 score for the three entity types. However, CAMeL achieved the highest precision values for names of people and organizations. Following this, we implemented a "merge" method that combined the results from the three tools and a "vote" method that tagged named entities only when two of the three identified them as entities. Our results showed that merging achieved the highest overall F1 scores. Moreover, merging had the highest recall values while voting had the highest precision values for the three entity types. This indicates that merging is more suitable when recall is desired, while voting is optimal when precision is required. Finally, we collected a corpus of 21,635 articles related to COVID-19 and applied the merge and vote methods. Our analysis demonstrates the tradeoff between precision and recall for the two methods.
Similarities between Arabic Dialects: Investigating Geographical Proximity
May 10, 2021
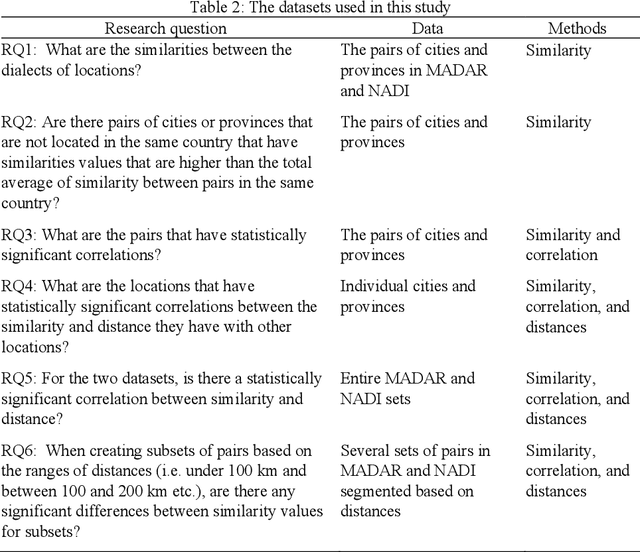
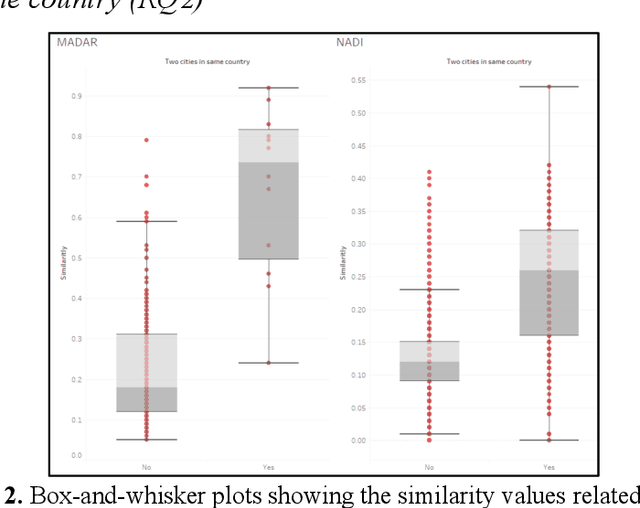

The automatic classification of Arabic dialects is an ongoing research challenge, which has been explored in recent work that defines dialects based on increasingly limited geographic areas like cities and provinces. This paper focuses on a related yet relatively unexplored topic: the effects of the geographical proximity of cities located in Arab countries on their dialectical similarity. Our work is twofold, reliant on: 1) comparing the textual similarities between dialects using cosine similarity and 2) measuring the geographical distance between locations. We study MADAR and NADI, two established datasets with Arabic dialects from many cities and provinces. Our results indicate that cities located in different countries may in fact have more dialectical similarity than cities within the same country, depending on their geographical proximity. The correlation between dialectical similarity and city proximity suggests that cities that are closer together are more likely to share dialectical attributes, regardless of country borders. This nuance provides the potential for important advancements in Arabic dialect research because it indicates that a more granular approach to dialect classification is essential to understanding how to frame the problem of Arabic dialects identification.
Clustering Prominent People and Organizations in Topic-Specific Text Corpora
Jul 27, 2018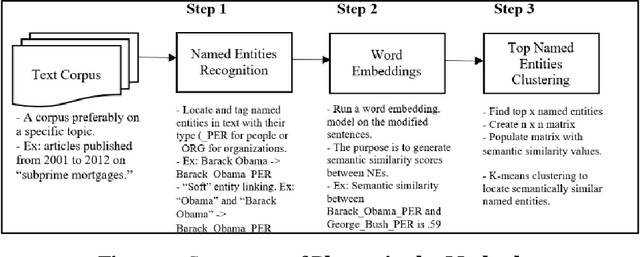
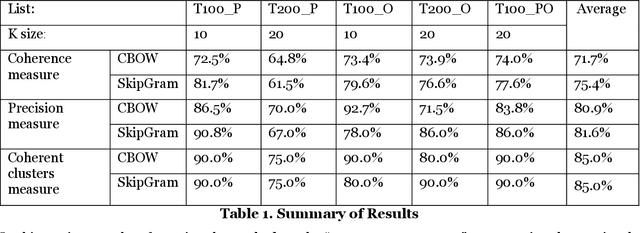
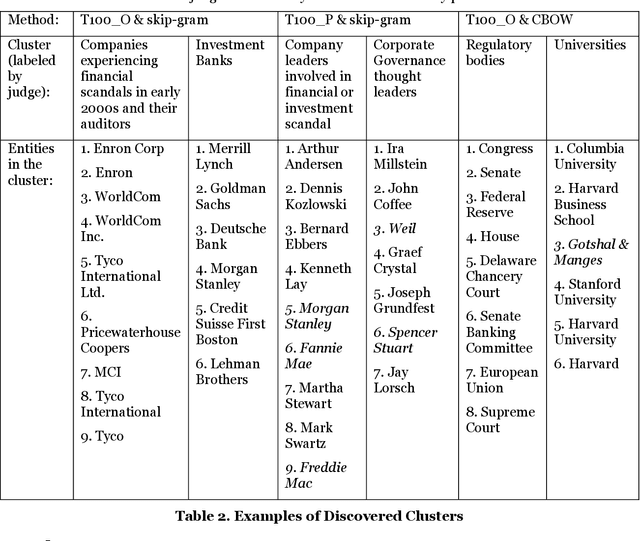
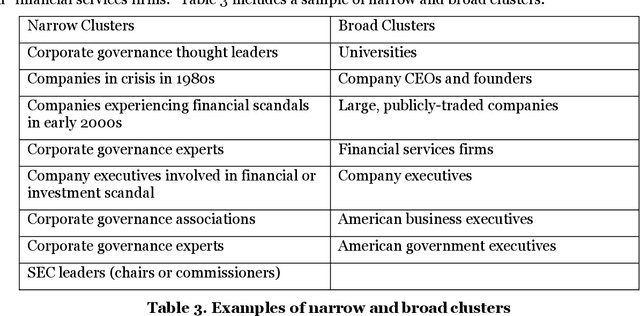
Named entities in text documents are the names of people, organization, location or other types of objects in the documents that exist in the real world. A persisting research challenge is to use computational techniques to identify such entities in text documents. Once identified, several text mining tools and algorithms can be utilized to leverage these discovered named entities and improve NLP applications. In this paper, a method that clusters prominent names of people and organizations based on their semantic similarity in a text corpus is proposed. The method relies on common named entity recognition techniques and on recent word embeddings models. The semantic similarity scores generated using the word embeddings models for the named entities are used to cluster similar entities of the people and organizations types. Two human judges evaluated ten variations of the method after it was run on a corpus that consists of 4,821 articles on a specific topic. The performance of the method was measured using three quantitative measures. The results of these three metrics demonstrate that the method is effective in clustering semantically similar named entities.
Image Classification for Arabic: Assessing the Accuracy of Direct English to Arabic Translations
Jul 13, 2018

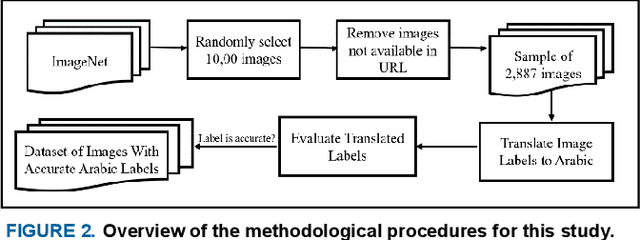
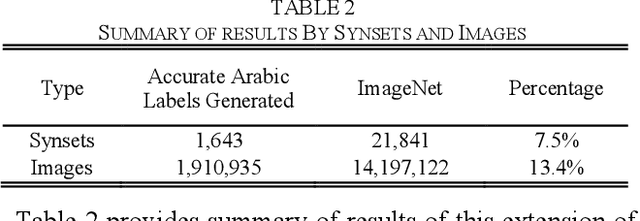
Image classification is an ongoing research challenge. Most of the available research focuses on image classification for the English language, however there is very little research on image classification for the Arabic language. Expanding image classification to Arabic has several applications. The present study investigated a method for generating Arabic labels for images of objects. The method used in this study involved a direct English to Arabic translation of the labels that are currently available on ImageNet, a database commonly used in image classification research. The purpose of this study was to test the accuracy of this method. In this study, 2,887 labeled images were randomly selected from ImageNet. All of the labels were translated from English to Arabic using Google Translate. The accuracy of the translations was evaluated. Results indicated that that 65.6% of the Arabic labels were accurate. This study makes three important contributions to the image classification literature: (1) it determined the baseline level of accuracy for algorithms that provide Arabic labels for images, (2) it provided 1,895 images that are tagged with accurate Arabic labels, and (3) provided the accuracy of translations of image labels from English to Arabic.