 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-variate Probabilistic Time Series Forecasting via Conditioned Normalizing Flows
Feb 14, 2020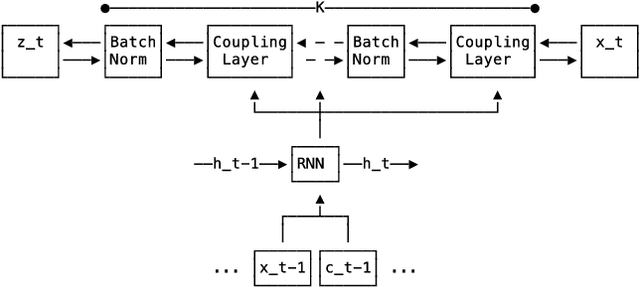

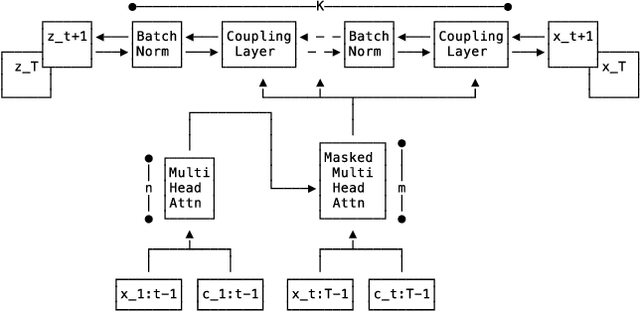
Time series forecasting is often fundamental to scientific and engineering problems and enables decision making. With ever increasing data set sizes, a trivial solution to scale up predictions is to assume independence between interacting time series. However, modeling statistical dependencies can improve accuracy and enable analysis of interaction effects. Deep learning methods are well suited for this problem, but multi-variate models often assume a simple parametric distribution and do not scale to high dimensions. In this work we model the multi-variate temporal dynamics of time series via an autoregressive deep learning model, where the data distribution is represented by a conditioned normalizing flow. This combination retains the power of autoregressive models, such as good performance in extrapolation into the future, with the flexibility of flows as a general purpose high-dimensional distribution model, while remaining computationally tractable. We show that it improves over the state-of-the-art for standard metrics on many real-world data sets with several thousand interacting time-series.
A Hierarchical Bayesian Model for Size Recommendation in Fashion
Aug 02, 2019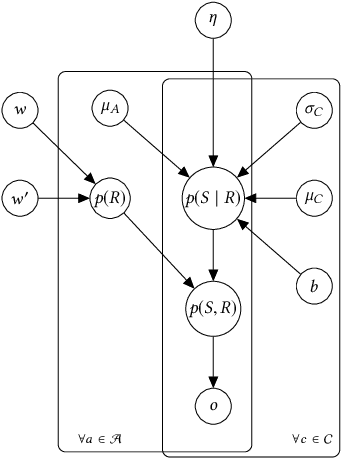

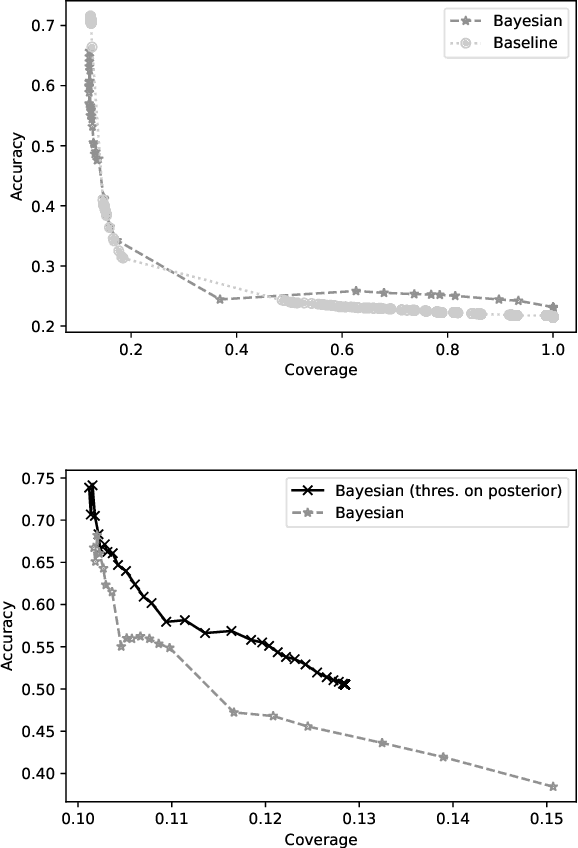
We introduce a hierarchical Bayesian approach to tackle the challenging problem of size recommendation in e-commerce fashion. Our approach jointly models a size purchased by a customer, and its possible return event: 1. no return, 2. returned too small 3. returned too big. Those events are drawn following a multinomial distribution parameterized on the joint probability of each event, built following a hierarchy combining priors. Such a model allows us to incorporate extended domain expertise and article characteristics as prior knowledge, which in turn makes it possible for the underlying parameters to emerge thanks to sufficient data. Experiments are presented on real (anonymized) data from millions of customers along with a detailed discussion on the efficiency of such an approach within a large scale production system.
ProSper -- A Python Library for Probabilistic Sparse Coding with Non-Standard Priors and Superpositions
Aug 01, 2019
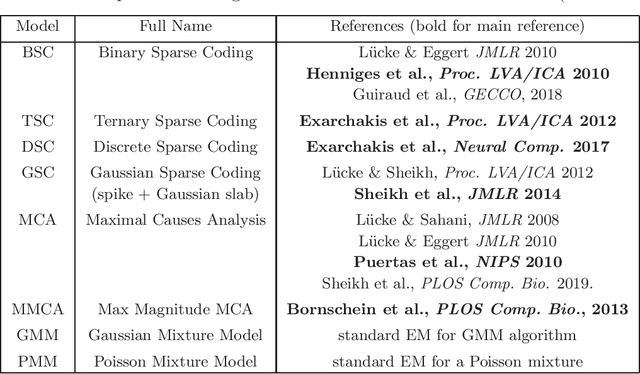
ProSper is a python library containing probabilistic algorithms to learn dictionaries. Given a set of data points, the implemented algorithms seek to learn the elementary components that have generated the data. The library widens the scope of dictionary learning approaches beyond implementations of standard approaches such as ICA, NMF or standard L1 sparse coding. The implemented algorithms are especially well-suited in cases when data consist of components that combine non-linearly and/or for data requiring flexible prior distributions. Furthermore, the implemented algorithms go beyond standard approaches by inferring prior and noise parameters of the data, and they provide rich a-posteriori approximations for inference. The library is designed to be extendable and it currently includes: Binary Sparse Coding (BSC), Ternary Sparse Coding (TSC), Discrete Sparse Coding (DSC), Maximal Causes Analysis (MCA), Maximum Magnitude Causes Analysis (MMCA), and Gaussian Sparse Coding (GSC, a recent spike-and-slab sparse coding approach). The algorithms are scalable due to a combination of variational approximations and parallelization. Implementations of all algorithms allow for parallel execution on multiple CPUs and multiple machines for medium to large-scale applications. Typical large-scale runs of the algorithms can use hundreds of CPUs to learn hundreds of dictionary elements from data with tens of millions of floating-point numbers such that models with several hundred thousand parameters can be optimized. The library is designed to have minimal dependencies and to be easy to use. It targets users of dictionary learning algorithms and Machine Learning researchers.
A Deep Learning System for Predicting Size and Fit in Fashion E-Commerce
Jul 23, 2019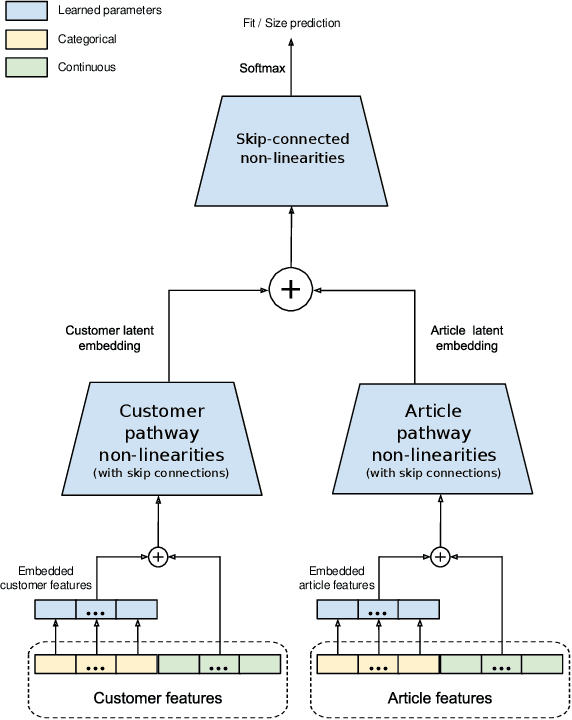
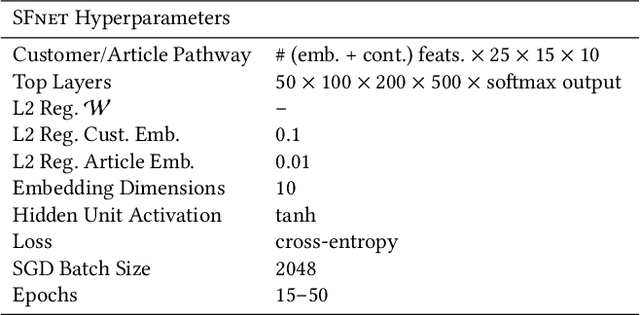
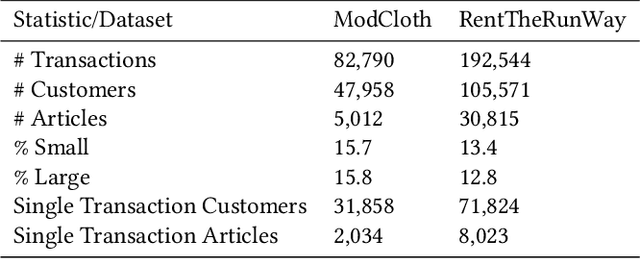
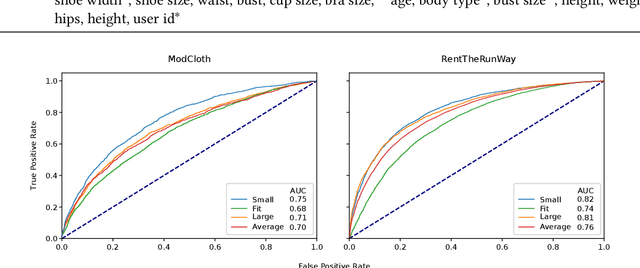
Personalized size and fit recommendations bear crucial significance for any fashion e-commerce platform. Predicting the correct fit drives customer satisfaction and benefits the business by reducing costs incurred due to size-related returns. Traditional collaborative filtering algorithms seek to model customer preferences based on their previous orders. A typical challenge for such methods stems from extreme sparsity of customer-article orders. To alleviate this problem, we propose a deep learning based content-collaborative methodology for personalized size and fit recommendation. Our proposed method can ingest arbitrary customer and article data and can model multiple individuals or intents behind a single account. The method optimizes a global set of parameters to learn population-level abstractions of size and fit relevant information from observed customer-article interactions. It further employs customer and article specific embedding variables to learn their properties. Together with learned entity embeddings, the method maps additional customer and article attributes into a latent space to derive personalized recommendations. Application of our method to two publicly available datasets demonstrate an improvement over the state-of-the-art published results. On two proprietary datasets, one containing fit feedback from fashion experts and the other involving customer purchases, we further outperform comparable methodologies, including a recent Bayesian approach for size recommendation.
A Bandit Framework for Optimal Selection of Reinforcement Learning Agents
Feb 10, 2019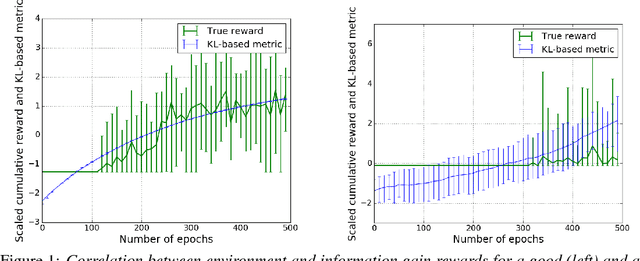
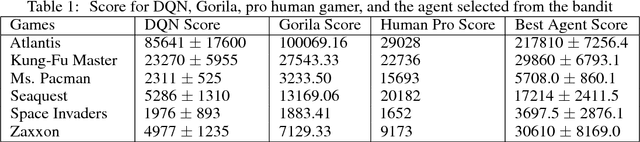
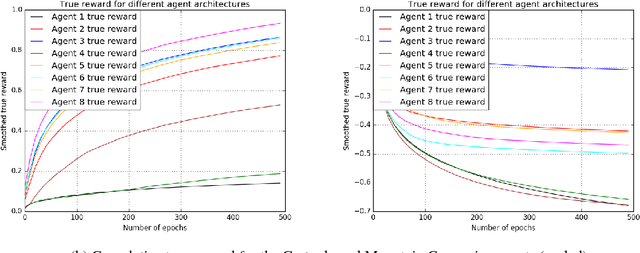
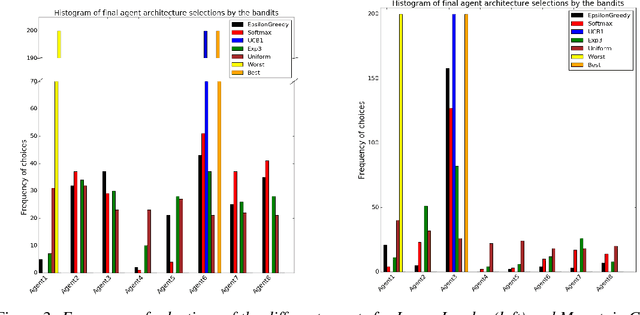
Deep Reinforcement Learning has been shown to be very successful in complex games, e.g. Atari or Go. These games have clearly defined rules, and hence allow simulation. In many practical applications, however, interactions with the environment are costly and a good simulator of the environment is not available. Further, as environments differ by application, the optimal inductive bias (architecture, hyperparameters, etc.) of a reinforcement agent depends on the application. In this work, we propose a multi-arm bandit framework that selects from a set of different reinforcement learning agents to choose the one with the best inductive bias. To alleviate the problem of sparse rewards, the reinforcement learning agents are augmented with surrogate rewards. This helps the bandit framework to select the best agents early, since these rewards are smoother and less sparse than the environment reward. The bandit has the double objective of maximizing the reward while the agents are learning and selecting the best agent after a finite number of learning steps. Our experimental results on standard environments show that the proposed framework is able to consistently select the optimal agent after a finite number of steps, while collecting more cumulative reward compared to selecting a sub-optimal architecture or uniformly alternating between different agents.
Stochastic Maximum Likelihood Optimization via Hypernetworks
Jan 12, 2018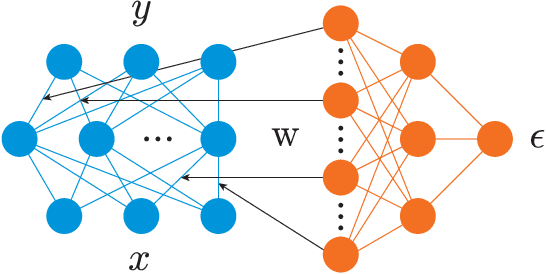
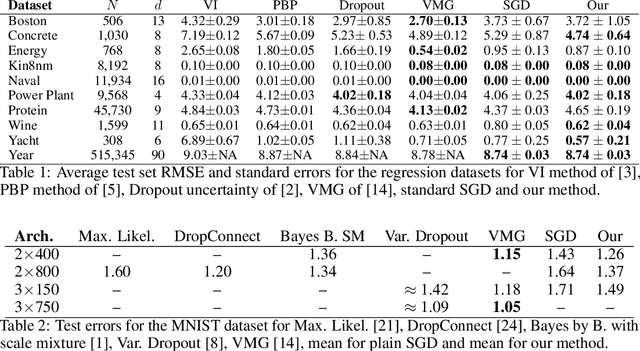
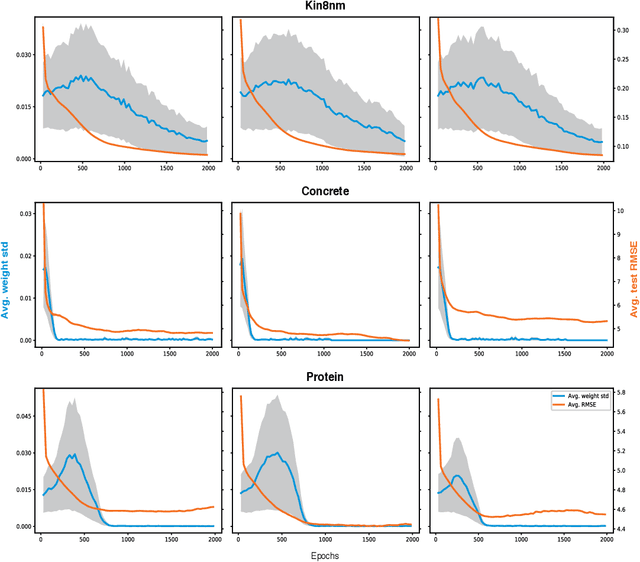
This work explores maximum likelihood optimization of neural networks through hypernetworks. A hypernetwork initializes the weights of another network, which in turn can be employed for typical functional tasks such as regression and classification. We optimize hypernetworks to directly maximize the conditional likelihood of target variables given input. Using this approach we obtain competitive empirical results on regression and classification benchmarks.
Neural Simpletrons - Minimalistic Directed Generative Networks for Learning with Few Labels
Nov 18, 2016
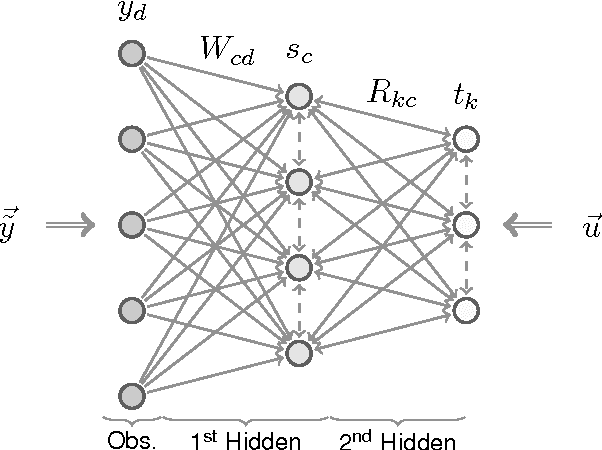

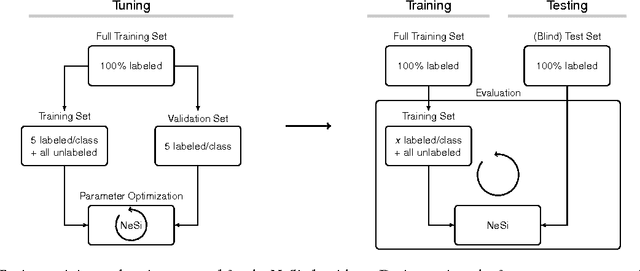
Classifiers for the semi-supervised setting often combine strong supervised models with additional learning objectives to make use of unlabeled data. This results in powerful though very complex models that are hard to train and that demand additional labels for optimal parameter tuning, which are often not given when labeled data is very sparse. We here study a minimalistic multi-layer generative neural network for semi-supervised learning in a form and setting as similar to standard discriminative networks as possible. Based on normalized Poisson mixtures, we derive compact and local learning and neural activation rules. Learning and inference in the network can be scaled using standard deep learning tools for parallelized GPU implementation. With the single objective of likelihood optimization, both labeled and unlabeled data are naturally incorporated into learning. Empirical evaluations on standard benchmarks show, that for datasets with few labels the derived minimalistic network improves on all classical deep learning approaches and is competitive with their recent variants without the need of additional labels for parameter tuning. Furthermore, we find that the studied network is the best performing monolithic (`non-hybrid') system for few labels, and that it can be applied in the limit of very few labels, where no other system has been reported to operate so far.
A Truncated EM Approach for Spike-and-Slab Sparse Coding
Sep 03, 2014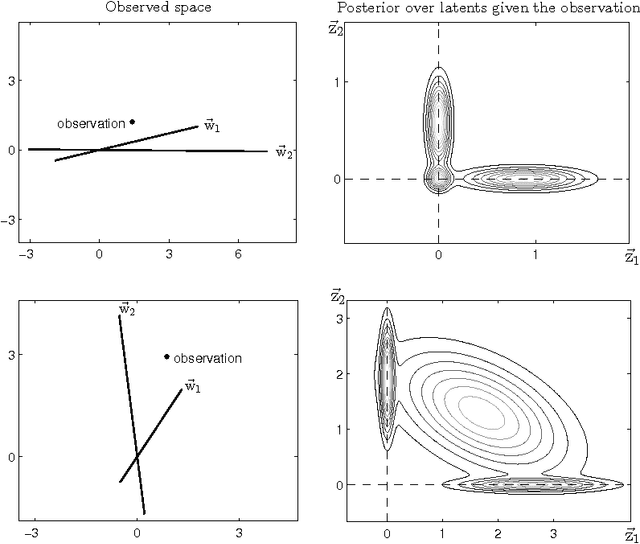
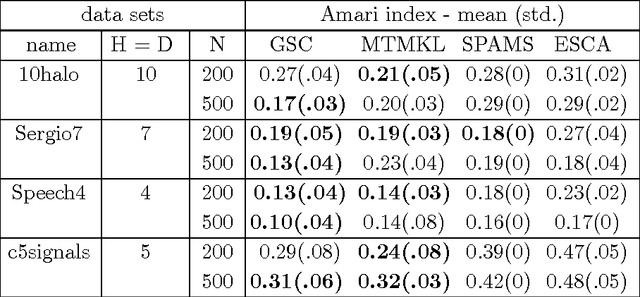
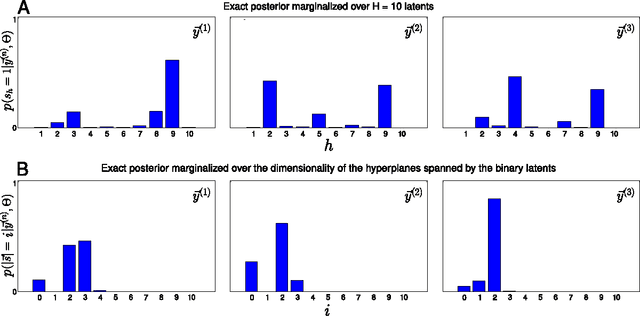

We study inference and learning based on a sparse coding model with `spike-and-slab' prior. As in standard sparse coding, the model used assumes independent latent sources that linearly combine to generate data points. However, instead of using a standard sparse prior such as a Laplace distribution, we study the application of a more flexible `spike-and-slab' distribution which models the absence or presence of a source's contribution independently of its strength if it contributes. We investigate two approaches to optimize the parameters of spike-and-slab sparse coding: a novel truncated EM approach and, for comparison, an approach based on standard factored variational distributions. The truncated approach can be regarded as a variational approach with truncated posteriors as variational distributions. In applications to source separation we find that both approaches improve the state-of-the-art in a number of standard benchmarks, which argues for the use of `spike-and-slab' priors for the corresponding data domains. Furthermore, we find that the truncated EM approach improves on the standard factored approach in source separation tasks$-$which hints to biases introduced by assuming posterior independence in the factored variational approach. Likewise, on a standard benchmark for image denoising, we find that the truncated EM approach improves on the factored variational approach. While the performance of the factored approach saturates with increasing numbers of hidden dimensions, the performance of the truncated approach improves the state-of-the-art for higher noise levels.
* To appear in JMLR (2014)
Closed-form EM for Sparse Coding and its Application to Source Separation
Mar 02, 2012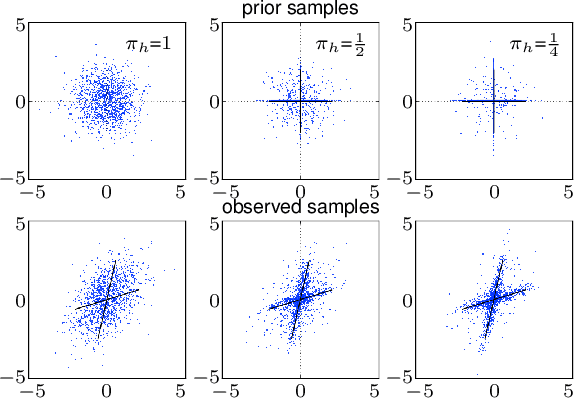
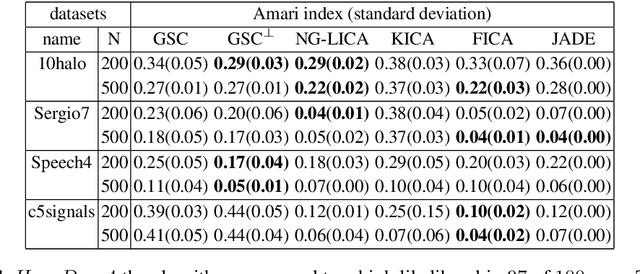
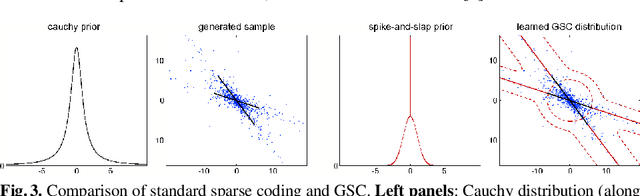
We define and discuss the first sparse coding algorithm based on closed-form EM updates and continuous latent variables. The underlying generative model consists of a standard `spike-and-slab' prior and a Gaussian noise model. Closed-form solutions for E- and M-step equations are derived by generalizing probabilistic PCA. The resulting EM algorithm can take all modes of a potentially multi-modal posterior into account. The computational cost of the algorithm scales exponentially with the number of hidden dimensions. However, with current computational resources, it is still possible to efficiently learn model parameters for medium-scale problems. Thus the model can be applied to the typical range of source separation tasks. In numerical experiments on artificial data we verify likelihood maximization and show that the derived algorithm recovers the sparse directions of standard sparse coding distributions. On source separation benchmarks comprised of realistic data we show that the algorithm is competitive with other recent methods.
* joint first authorship