 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bandit Framework for Optimal Selection of Reinforcement Learning Agents
Feb 10, 2019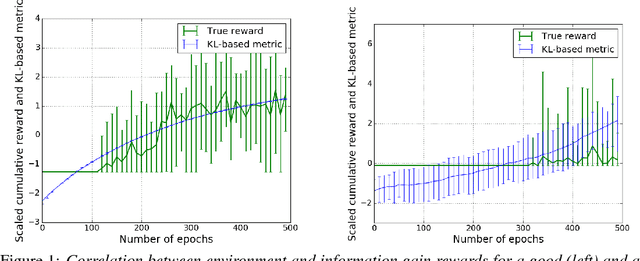
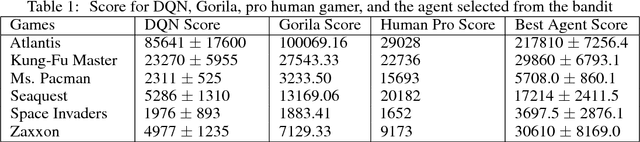
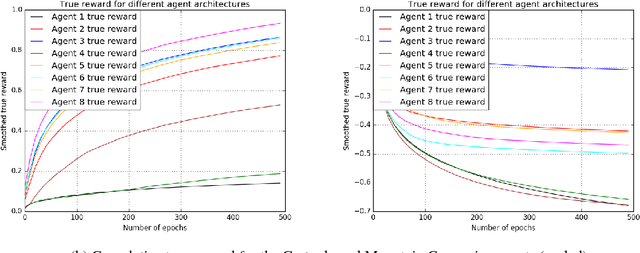
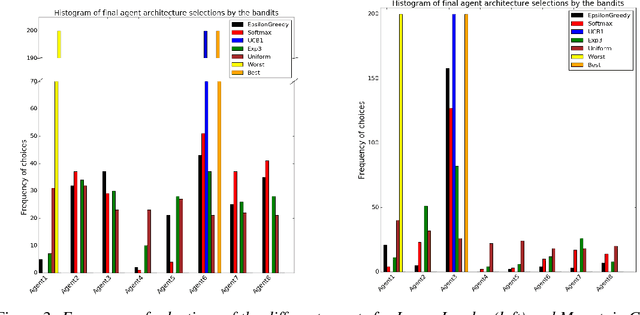
Deep Reinforcement Learning has been shown to be very successful in complex games, e.g. Atari or Go. These games have clearly defined rules, and hence allow simulation. In many practical applications, however, interactions with the environment are costly and a good simulator of the environment is not available. Further, as environments differ by application, the optimal inductive bias (architecture, hyperparameters, etc.) of a reinforcement agent depends on the application. In this work, we propose a multi-arm bandit framework that selects from a set of different reinforcement learning agents to choose the one with the best inductive bias. To alleviate the problem of sparse rewards, the reinforcement learning agents are augmented with surrogate rewards. This helps the bandit framework to select the best agents early, since these rewards are smoother and less sparse than the environment reward. The bandit has the double objective of maximizing the reward while the agents are learning and selecting the best agent after a finite number of learning steps. Our experimental results on standard environments show that the proposed framework is able to consistently select the optimal agent after a finite number of steps, while collecting more cumulative reward compared to selecting a sub-optimal architecture or uniformly alternating between different agents.
Stochastic Maximum Likelihood Optimization via Hypernetworks
Jan 12, 2018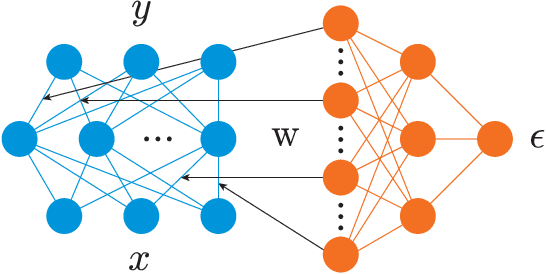
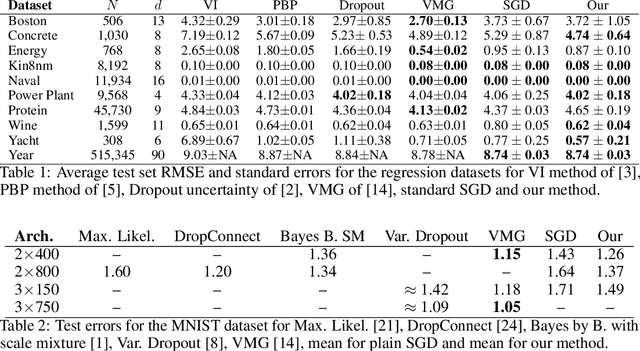
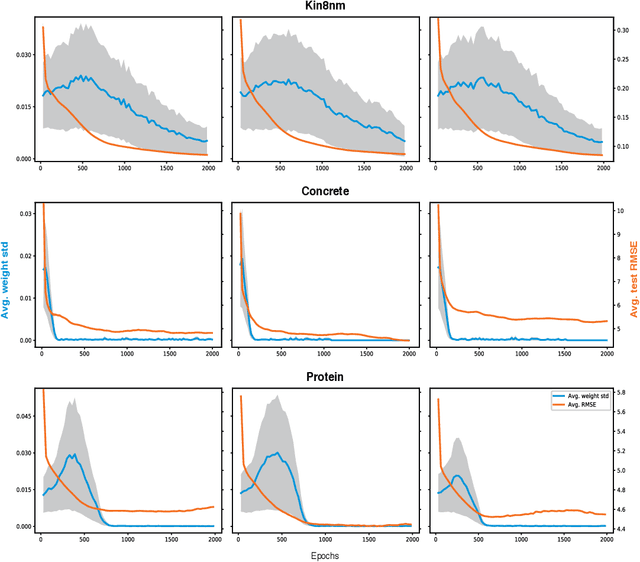
This work explores maximum likelihood optimization of neural networks through hypernetworks. A hypernetwork initializes the weights of another network, which in turn can be employed for typical functional tasks such as regression and classification. We optimize hypernetworks to directly maximize the conditional likelihood of target variables given input. Using this approach we obtain competitive empirical results on regression and classification benchmarks.