 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDolphin: A Challenging and Diverse Benchmark for Arabic NLG
May 24, 2023We present Dolphin, a novel benchmark that addresses the need for an evaluation framework for the wide collection of Arabic languages and varieties. The proposed benchmark encompasses a broad range of 13 different NLG tasks, including text summarization, machine translation, question answering, and dialogue generation, among others. Dolphin comprises a substantial corpus of 40 diverse and representative public datasets across 50 test splits, carefully curated to reflect real-world scenarios and the linguistic richness of Arabic. It sets a new standard for evaluating the performance and generalization capabilities of Arabic and multilingual models, promising to enable researchers to push the boundaries of current methodologies. We provide an extensive analysis of Dolphin, highlighting its diversity and identifying gaps in current Arabic NLG research. We also evaluate several Arabic and multilingual models on our benchmark, allowing us to set strong baselines against which researchers can compare.
UBC-DLNLP at SemEval-2023 Task 12: Impact of Transfer Learning on African Sentiment Analysis
Apr 25, 2023We describe our contribution to the SemEVAl 2023 AfriSenti-SemEval shared task, where we tackle the task of sentiment analysis in 14 different African languages. We develop both monolingual and multilingual models under a full supervised setting (subtasks A and B). We also develop models for the zero-shot setting (subtask C). Our approach involves experimenting with transfer learning using six language models, including further pertaining of some of these models as well as a final finetuning stage. Our best performing models achieve an F1-score of 70.36 on development data and an F1-score of 66.13 on test data. Unsurprisingly, our results demonstrate the effectiveness of transfer learning and fine-tuning techniques for sentiment analysis across multiple languages. Our approach can be applied to other sentiment analysis tasks in different languages and domains.
ORCA: A Challenging Benchmark for Arabic Language Understanding
Dec 21, 2022Due to their crucial role in all NLP, several benchmarks have been proposed to evaluate pretrained language models. In spite of these efforts, no public benchmark of diverse nature currently exists for evaluation of Arabic. This makes it challenging to measure progress for both Arabic and multilingual language models. This challenge is compounded by the fact that any benchmark targeting Arabic needs to take into account the fact that Arabic is not a single language but rather a collection of languages and varieties. In this work, we introduce ORCA, a publicly available benchmark for Arabic language understanding evaluation. ORCA is carefully constructed to cover diverse Arabic varieties and a wide range of challenging Arabic understanding tasks exploiting 60 different datasets across seven NLU task clusters. To measure current progress in Arabic NLU, we use ORCA to offer a comprehensive comparison between 18 multilingual and Arabic language models. We also provide a public leaderboard with a unified single-number evaluation metric (ORCA score) to facilitate future research.
JASMINE: Arabic GPT Models for Few-Shot Learning
Dec 21, 2022Task agnostic generative pretraining (GPT) has recently proved promising for zero- and few-shot learning, gradually diverting attention from the expensive supervised learning paradigm. Although the community is accumulating knowledge as to capabilities of English-language autoregressive models such as GPT-3 adopting this generative approach, scholarship about these models remains acutely Anglocentric. Consequently, the community currently has serious gaps in its understanding of this class of models, their potential, and their societal impacts in diverse settings, linguistic traditions, and cultures. To alleviate this issue for Arabic, a collection of diverse languages and language varieties with more than $400$ million population, we introduce JASMINE, a suite of powerful Arabic autoregressive Transformer language models ranging in size between 300 million-13 billion parameters. We pretrain our new models with large amounts of diverse data (400GB of text) from different Arabic varieties and domains. We evaluate JASMINE extensively in both intrinsic and extrinsic settings, using a comprehensive benchmark for zero- and few-shot learning across a wide range of NLP tasks. We also carefully develop and release a novel benchmark for both automated and human evaluation of Arabic autoregressive models focused at investigating potential social biases, harms, and toxicity in these models. We aim to responsibly release our models with interested researchers, along with code for experimenting with them
SERENGETI: Massively Multilingual Language Models for Africa
Dec 21, 2022Multilingual language models (MLMs) acquire valuable, generalizable linguistic information during pretraining and have advanced the state of the art on task-specific finetuning. So far, only ~ 28 out of ~2,000 African languages are covered in existing language models. We ameliorate this limitation by developing SERENGETI, a set of massively multilingual language model that covers 517 African languages and language varieties. We evaluate our novel models on eight natural language understanding tasks across 20 datasets, comparing to four MLMs that each cover any number of African languages. SERENGETI outperforms other models on 11 datasets across the eights tasks and achieves 82.27 average F-1. We also perform error analysis on our models' performance and show the influence of mutual intelligibility when the models are applied under zero-shot settings. We will publicly release our models for research.
NADI 2022: The Third Nuanced Arabic Dialect Identification Shared Task
Oct 18, 2022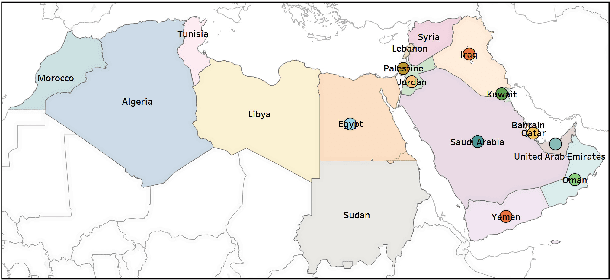
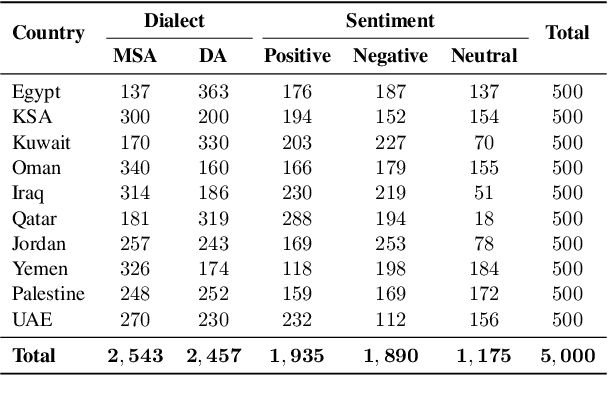
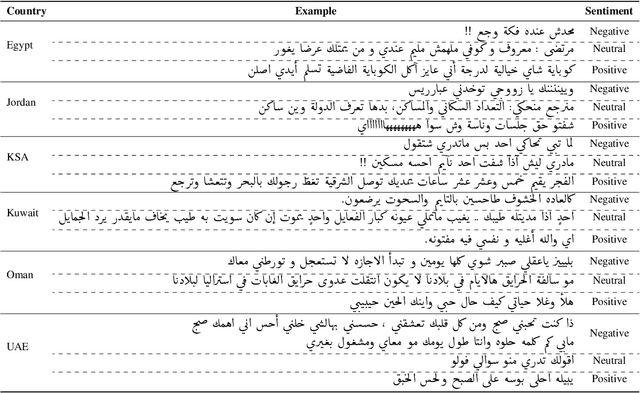
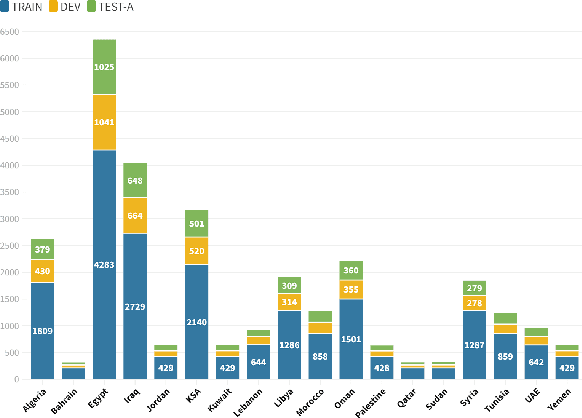
We describe findings of the third Nuanced Arabic Dialect Identification Shared Task (NADI 2022). NADI aims at advancing state of the art Arabic NLP, including on Arabic dialects. It does so by affording diverse datasets and modeling opportunities in a standardized context where meaningful comparisons between models and approaches are possible. NADI 2022 targeted both dialect identification (Subtask 1) and dialectal sentiment analysis (Subtask 2) at the country level. A total of 41 unique teams registered for the shared task, of whom 21 teams have actually participated (with 105 valid submissions). Among these, 19 teams participated in Subtask 1 and 10 participated in Subtask 2. The winning team achieved 27.06 F1 on Subtask 1 and F1=75.16 on Subtask 2, reflecting that the two subtasks remain challenging and motivating future work in this area. We describe methods employed by participating teams and offer an outlook for NADI.
TURJUMAN: A Public Toolkit for Neural Arabic Machine Translation
May 27, 2022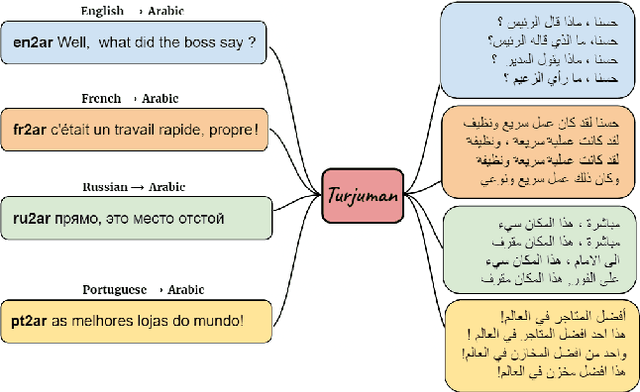
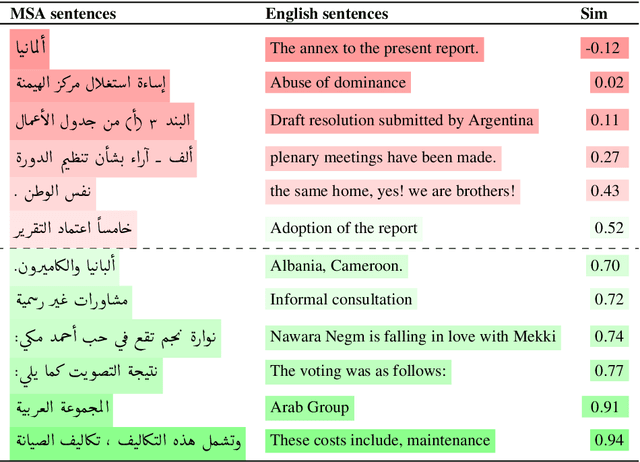
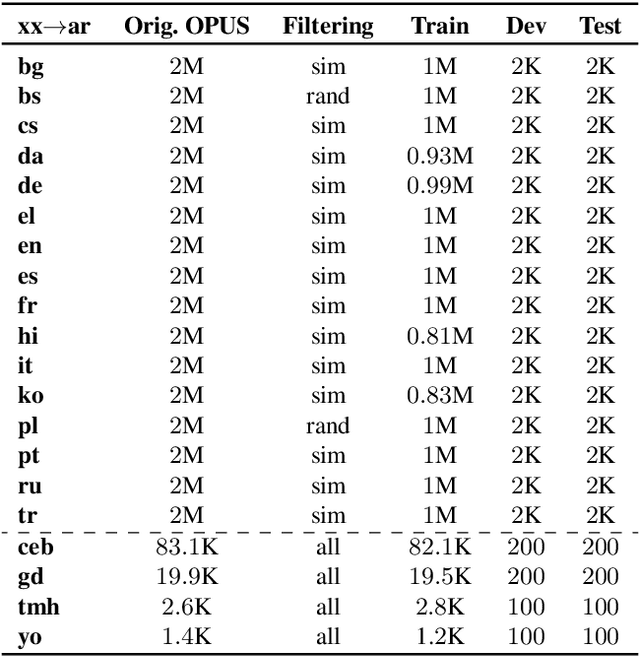
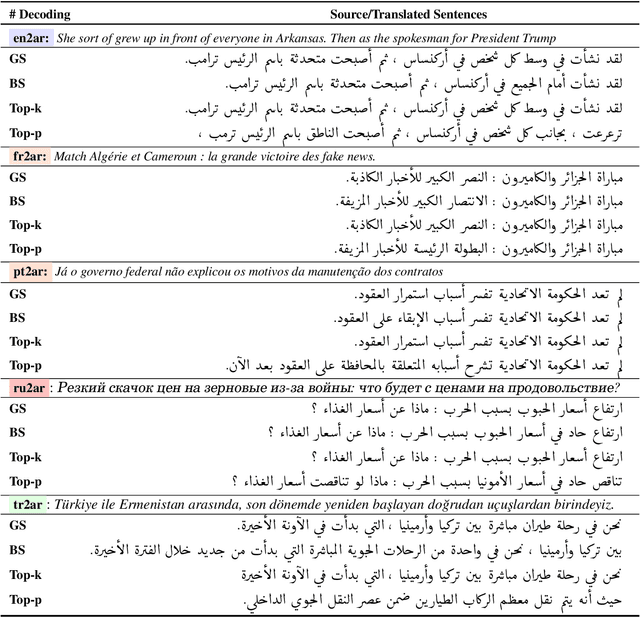
We present TURJUMAN, a neural toolkit for translating from 20 languages into Modern Standard Arabic (MSA). TURJUMAN exploits the recently-introduced text-to-text Transformer AraT5 model, endowing it with a powerful ability to decode into Arabic. The toolkit offers the possibility of employing a number of diverse decoding methods, making it suited for acquiring paraphrases for the MSA translations as an added value. To train TURJUMAN, we sample from publicly available parallel data employing a simple semantic similarity method to ensure data quality. This allows us to prepare and release AraOPUS-20, a new machine translation benchmark. We publicly release our translation toolkit (TURJUMAN) as well as our benchmark dataset (AraOPUS-20).
* All authors contributed equally
Improving Social Meaning Detection with Pragmatic Masking and Surrogate Fine-Tuning
Aug 01, 2021
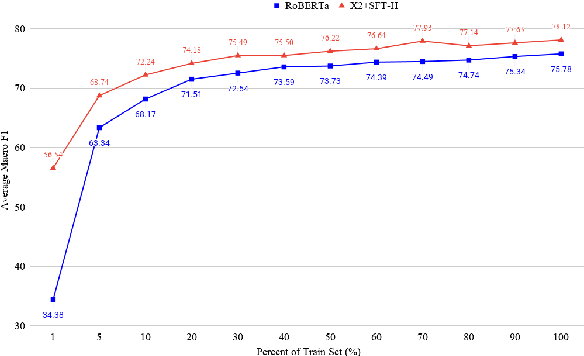
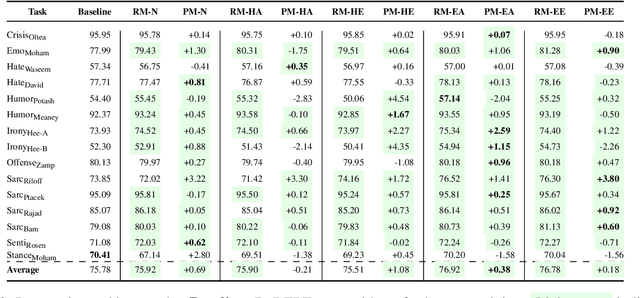
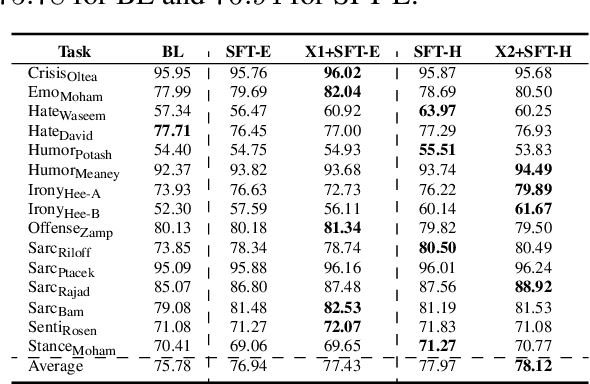
Masked language models (MLMs) are pretrained with a denoising objective that, while useful, is in a mismatch with the objective of downstream fine-tuning. We propose pragmatic masking and surrogate fine-tuning as two strategies that exploit social cues to drive pre-trained representations toward a broad set of concepts useful for a wide class of social meaning tasks. To test our methods, we introduce a new benchmark of 15 different Twitter datasets for social meaning detection. Our methods achieve 2.34% F1 over a competitive baseline, while outperforming other transfer learning methods such as multi-task learning and domain-specific language models pretrained on large datasets. With only 5% of training data (severely few-shot), our methods enable an impressive 68.74% average F1, and we observe promising results in a zero-shot setting involving six datasets from three different languages.
Investigating Code-Mixed Modern Standard Arabic-Egyptian to English Machine Translation
May 28, 2021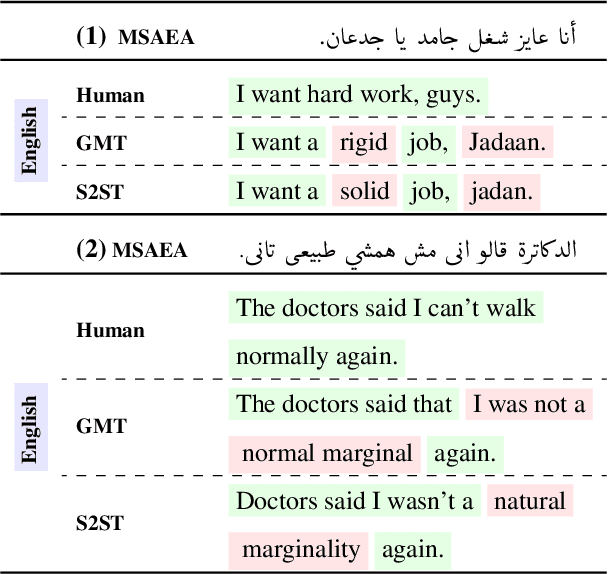
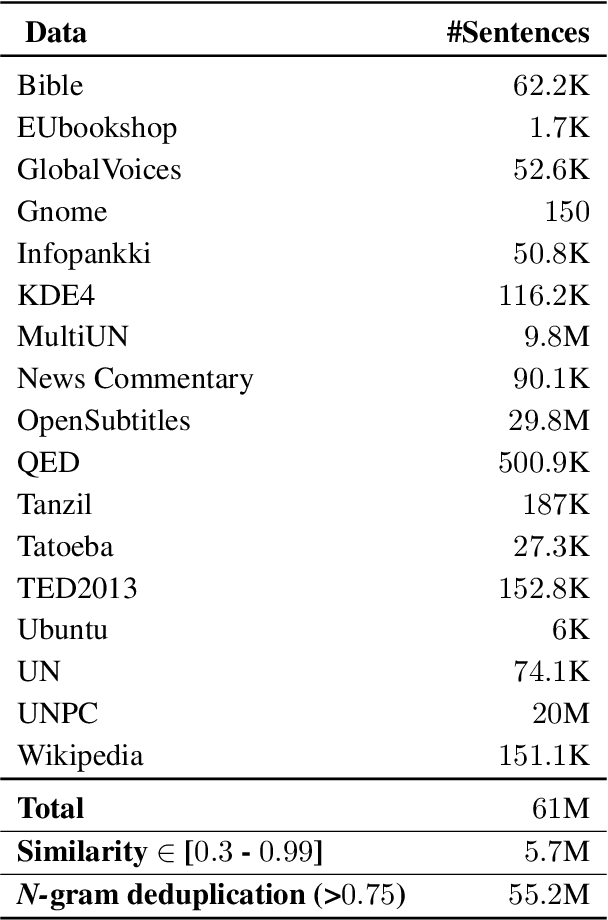
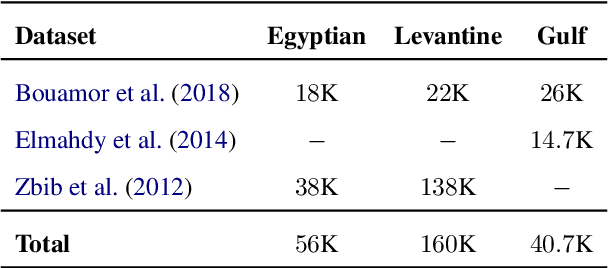
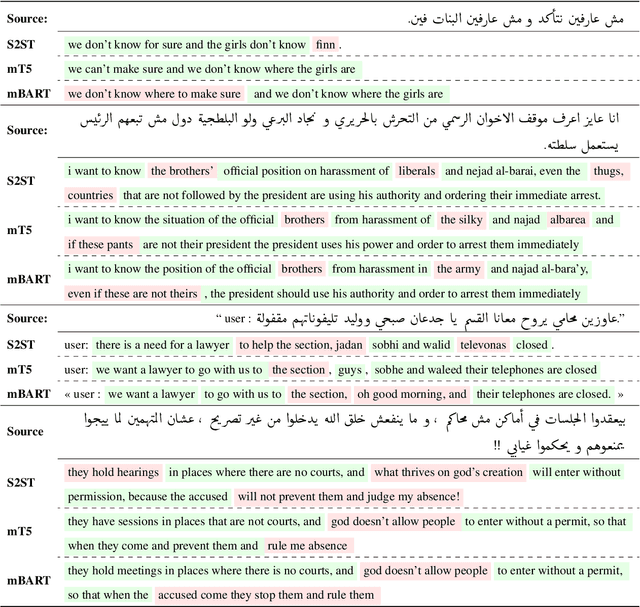
Recent progress in neural machine translation (NMT) has made it possible to translate successfully between monolingual language pairs where large parallel data exist, with pre-trained models improving performance even further. Although there exists work on translating in code-mixed settings (where one of the pairs includes text from two or more languages), it is still unclear what recent success in NMT and language modeling exactly means for translating code-mixed text. We investigate one such context, namely MT from code-mixed Modern Standard Arabic and Egyptian Arabic (MSAEA) into English. We develop models under different conditions, employing both (i) standard end-to-end sequence-to-sequence (S2S) Transformers trained from scratch and (ii) pre-trained S2S language models (LMs). We are able to acquire reasonable performance using only MSA-EN parallel data with S2S models trained from scratch. We also find LMs fine-tuned on data from various Arabic dialects to help the MSAEA-EN task. Our work is in the context of the Shared Task on Machine Translation in Code-Switching. Our best model achieves $\bf25.72$ BLEU, placing us first on the official shared task evaluation for MSAEA-EN.
NADI 2021: The Second Nuanced Arabic Dialect Identification Shared Task
Mar 04, 2021

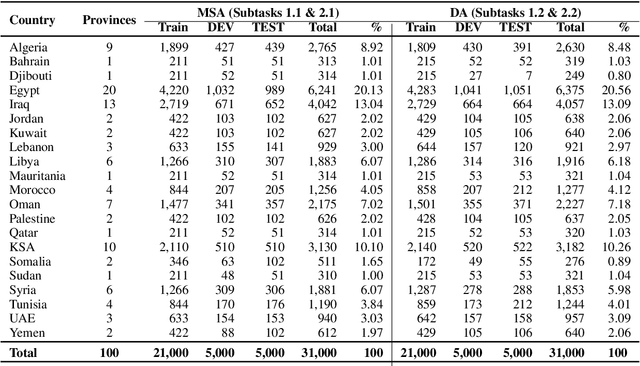
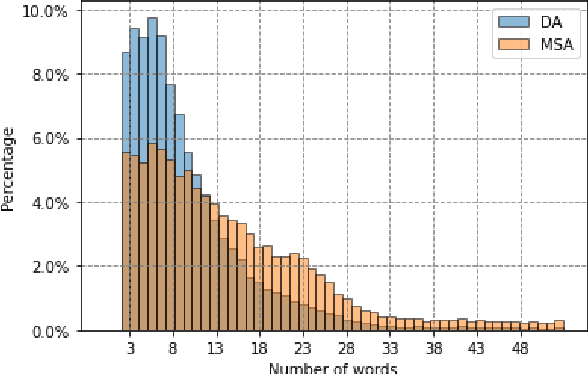
We present the findings and results of the Second Nuanced Arabic Dialect Identification Shared Task (NADI 2021). This Shared Task includes four subtasks: country-level Modern Standard Arabic (MSA) identification (Subtask 1.1), country-level dialect identification (Subtask 1.2), province-level MSA identification (Subtask 2.1), and province-level sub-dialect identification (Subtask 2.2). The shared task dataset covers a total of 100 provinces from 21 Arab countries, collected from the Twitter domain. A total of 53 teams from 23 countries registered to participate in the tasks, thus reflecting the interest of the community in this area. We received 16 submissions for Subtask 1.1 from five teams, 27 submissions for Subtask 1.2 from eight teams, 12 submissions for Subtask 2.1 from four teams, and 13 Submissions for subtask 2.2 from four teams.