 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Modeling of the Latent Embedding of Music using Deep Neural Network
May 12, 2017
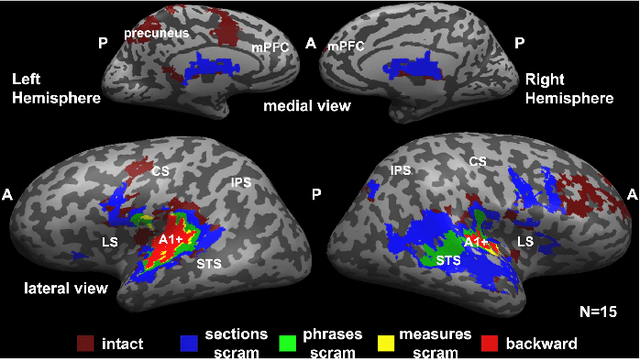
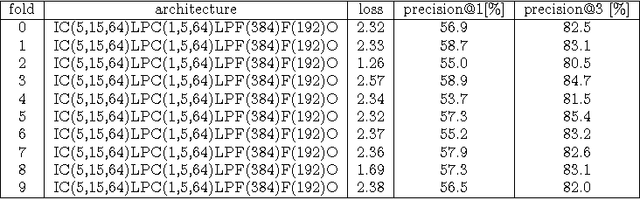
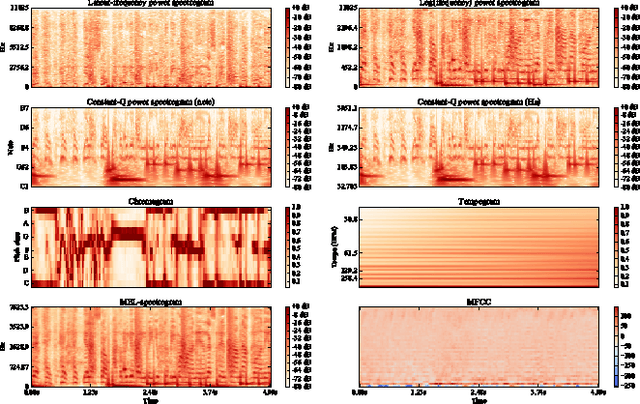
While both the data volume and heterogeneity of the digital music content is huge, it has become increasingly important and convenient to build a recommendation or search system to facilitate surfacing these content to the user or consumer community. Most of the recommendation models fall into two primary species, collaborative filtering based and content based approaches. Variants of instantiations of collaborative filtering approach suffer from the common issues of so called "cold start" and "long tail" problems where there is not much user interaction data to reveal user opinions or affinities on the content and also the distortion towards the popular content. Content-based approaches are sometimes limited by the richness of the available content data resulting in a heavily biased and coarse recommendation result. In recent years, the deep neural network has enjoyed a great success in large-scale image and video recognitions. In this paper, we propose and experiment using deep convolutional neural network to imitate how human brain processes hierarchical structures in the auditory signals, such as music, speech, etc., at various timescales. This approach can be used to discover the latent factor models of the music based upon acoustic hyper-images that are extracted from the raw audio waves of music. These latent embeddings can be used either as features to feed to subsequent models, such as collaborative filtering, or to build similarity metrics between songs, or to classify music based on the labels for training such as genre, mood, sentiment, etc.
A Contextual Latent Space Model: Subsequence Modulation in Melodic Sequence
Nov 23, 2021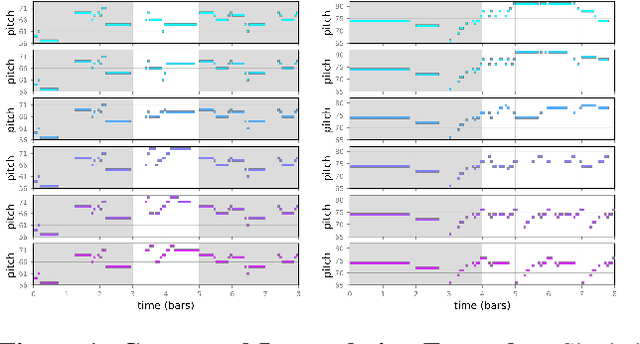
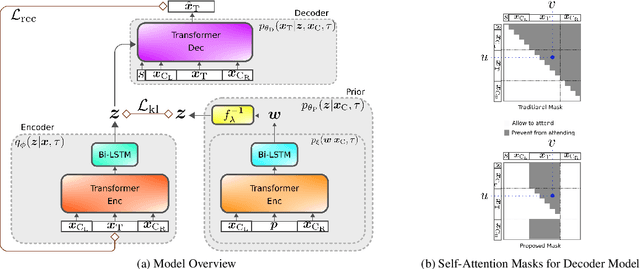
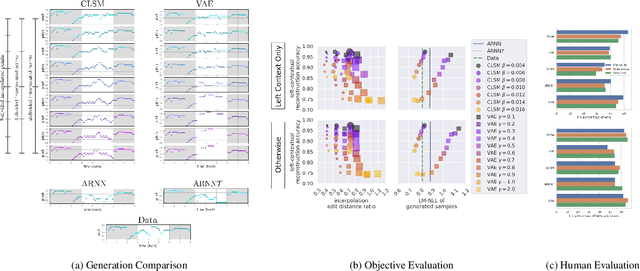
Some generative models for sequences such as music and text allow us to edit only subsequences, given surrounding context sequences, which plays an important part in steering generation interactively. However, editing subsequences mainly involves randomly resampling subsequences from a possible generation space. We propose a contextual latent space model (CLSM) in order for users to be able to explore subsequence generation with a sense of direction in the generation space, e.g., interpolation, as well as exploring variations -- semantically similar possible subsequences. A context-informed prior and decoder constitute the generative model of CLSM, and a context position-informed encoder is the inference model. In experiments, we use a monophonic symbolic music dataset, demonstrating that our contextual latent space is smoother in interpolation than baselines, and the quality of generated samples is superior to baseline models. The generation examples are available online.
Nonasymptotic performance analysis of ESPRIT and spatial-smoothing ESPRIT
Jan 10, 2022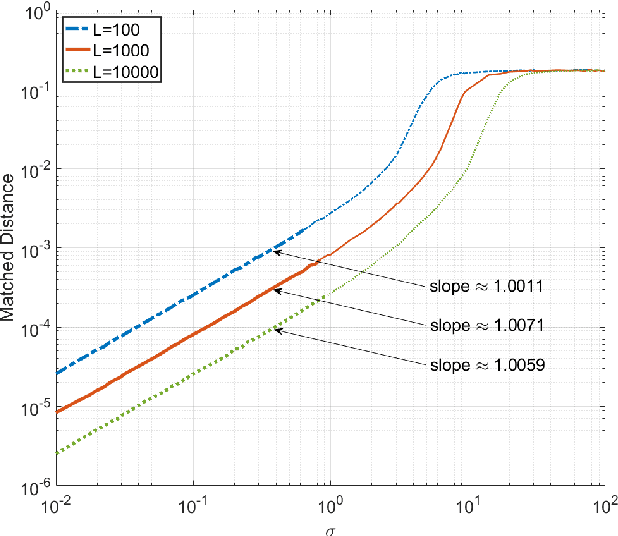
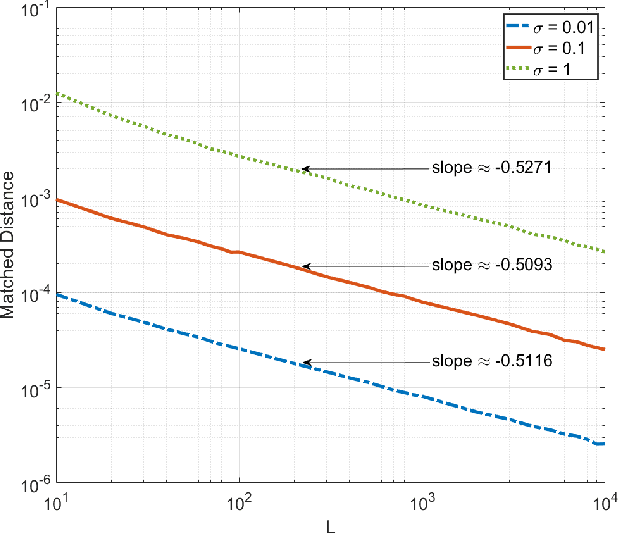
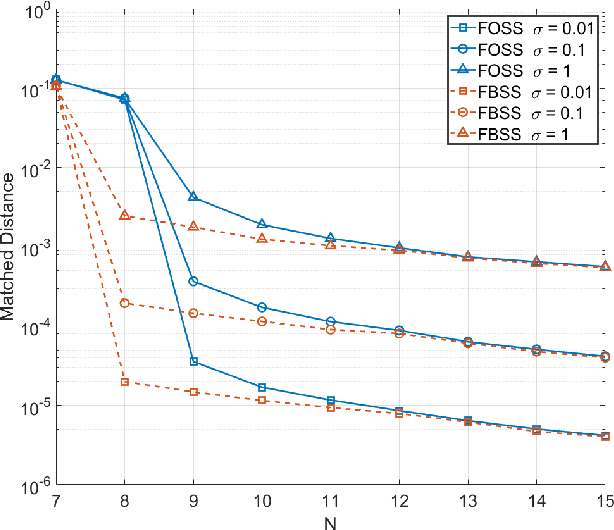
This paper is concerned with the problem of frequency estimation from multiple-snapshot data. It is well-known that ESPRIT (and spatial-smoothing ESPRIT in presence of coherent sources or given limited snapshots) can locate the true frequencies if either the number of snapshots or the signal-to-noise ratio (SNR) approaches infinity. In this paper, we analyze the nonasymptotic performance of ESPRIT and spatial-smoothing ESPRIT with finitely many snapshots and finite SNR. We show that the absolute frequency estimation error of ESPRIT (or spatial-smoothing ESPRIT) is bounded from above by $C\frac{\max(\sigma, \sigma^2)}{\sqrt{L}}$ with overwhelming probability, where $\sigma^2$ denotes the Gaussian noise variance, $L$ is the number of snapshots and $C$ is a coefficient independent of $L$ and $\sigma^2$, if and only if the true frequencies can be localized by ESPRIT (or spatial-smoothing ESPRIT) without noise or with infinitely many snapshots. Our results are obtained by deriving new matrix perturbation bounds and generalizing the classical Schur product theorem, which may be of independent interest. Extensions to MUSIC and SS-MUSIC are also made. Numerical results are provided corroborating our analysis.
HyperBox: A Supervised Approach for Hypernym Discovery using Box Embeddings
Apr 05, 2022

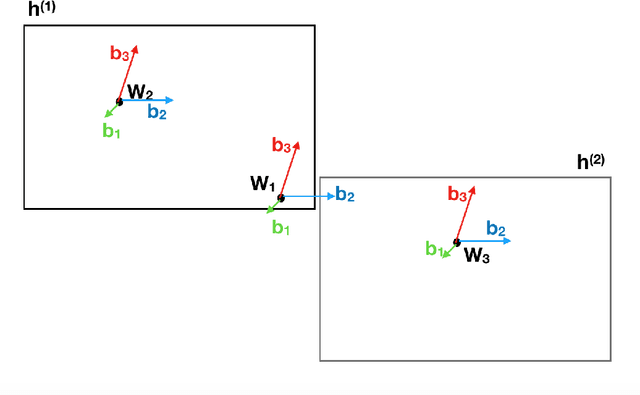
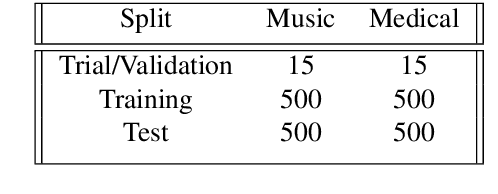
Hypernymy plays a fundamental role in many AI tasks like taxonomy learning, ontology learning, etc. This has motivated the development of many automatic identification methods for extracting this relation, most of which rely on word distribution. We present a novel model HyperBox to learn box embeddings for hypernym discovery. Given an input term, HyperBox retrieves its suitable hypernym from a target corpus. For this task, we use the dataset published for SemEval 2018 Shared Task on Hypernym Discovery. We compare the performance of our model on two specific domains of knowledge: medical and music. Experimentally, we show that our model outperforms existing methods on the majority of the evaluation metrics. Moreover, our model generalize well over unseen hypernymy pairs using only a small set of training data.
Efficient Learning of Harmonic Priors for Pitch Detection in Polyphonic Music
May 19, 2017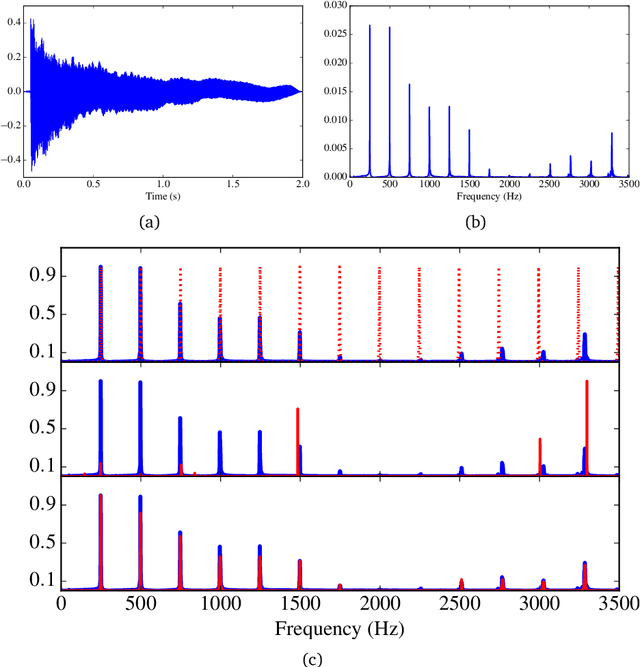
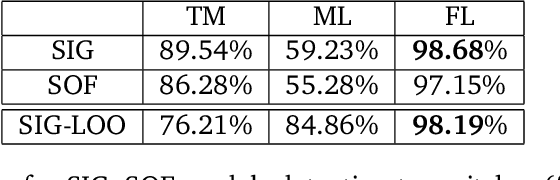
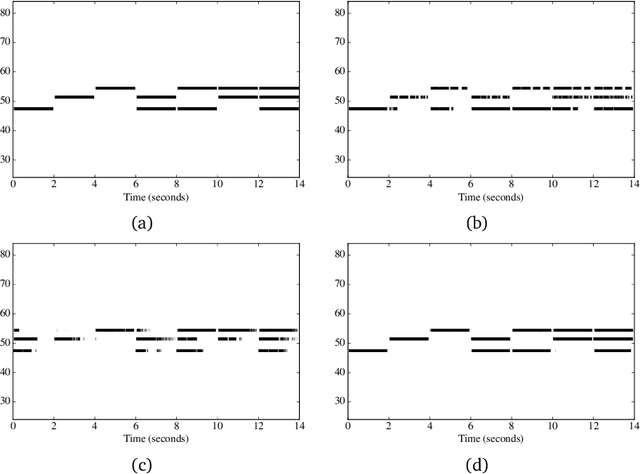
Automatic music transcription (AMT) aims to infer a latent symbolic representation of a piece of music (piano-roll), given a corresponding observed audio recording. Transcribing polyphonic music (when multiple notes are played simultaneously) is a challenging problem, due to highly structured overlapping between harmonics. We study whether the introduction of physically inspired Gaussian process (GP) priors into audio content analysis models improves the extraction of patterns required for AMT. Audio signals are described as a linear combination of sources. Each source is decomposed into the product of an amplitude-envelope, and a quasi-periodic component process. We introduce the Mat\'ern spectral mixture (MSM) kernel for describing frequency content of singles notes. We consider two different regression approaches. In the sigmoid model every pitch-activation is independently non-linear transformed. In the softmax model several activation GPs are jointly non-linearly transformed. This introduce cross-correlation between activations. We use variational Bayes for approximate inference. We empirically evaluate how these models work in practice transcribing polyphonic music. We demonstrate that rather than encourage dependency between activations, what is relevant for improving pitch detection is to learnt priors that fit the frequency content of the sound events to detect.
Human Evaluation of Interpretability: The Case of AI-Generated Music Knowledge
Apr 15, 2020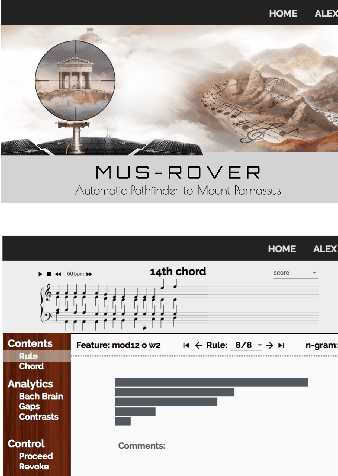
Interpretability of machine learning models has gained more and more attention among researchers in the artificial intelligence (AI) and human-computer interaction (HCI) communities. Most existing work focuses on decision making, whereas we consider knowledge discovery. In particular, we focus on evaluating AI-discovered knowledge/rules in the arts and humanities. From a specific scenario, we present an experimental procedure to collect and assess human-generated verbal interpretations of AI-generated music theory/rules rendered as sophisticated symbolic/numeric objects. Our goal is to reveal both the possibilities and the challenges in such a process of decoding expressive messages from AI sources. We treat this as a first step towards 1) better design of AI representations that are human interpretable and 2) a general methodology to evaluate interpretability of AI-discovered knowledge representations.
Learning to Fuse Music Genres with Generative Adversarial Dual Learning
Dec 05, 2017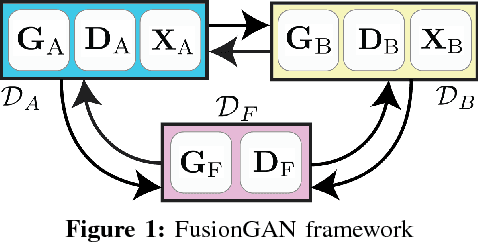
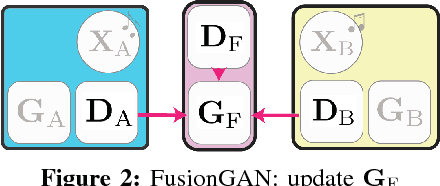
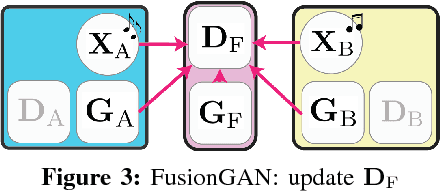
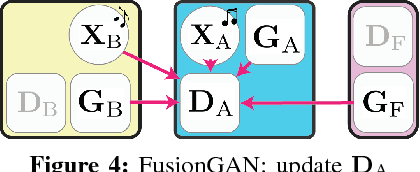
FusionGAN is a novel genre fusion framework for music generation that integrates the strengths of generative adversarial networks and dual learning. In particular, the proposed method offers a dual learning extension that can effectively integrate the styles of the given domains. To efficiently quantify the difference among diverse domains and avoid the vanishing gradient issue, FusionGAN provides a Wasserstein based metric to approximate the distance between the target domain and the existing domains. Adopting the Wasserstein distance, a new domain is created by combining the patterns of the existing domains using adversarial learning. Experimental results on public music datasets demonstrated that our approach could effectively merge two genres.
DoReMi: First glance at a universal OMR dataset
Jul 16, 2021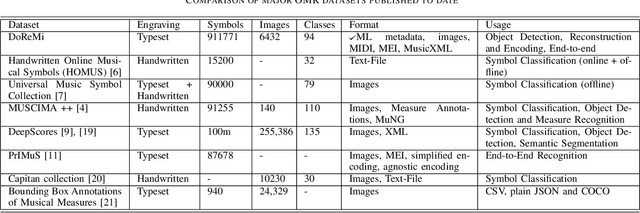
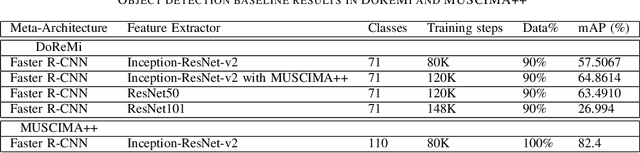
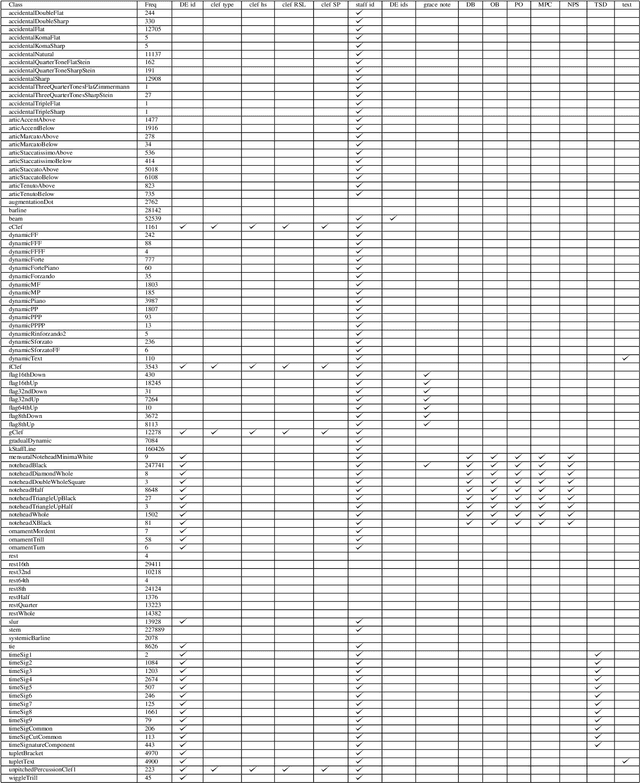
The main challenges of Optical Music Recognition (OMR) come from the nature of written music, its complexity and the difficulty of finding an appropriate data representation. This paper provides a first look at DoReMi, an OMR dataset that addresses these challenges, and a baseline object detection model to assess its utility. Researchers often approach OMR following a set of small stages, given that existing data often do not satisfy broader research. We examine the possibility of changing this tendency by presenting more metadata. Our approach complements existing research; hence DoReMi allows harmonisation with two existing datasets, DeepScores and MUSCIMA++. DoReMi was generated using a music notation software and includes over 6400 printed sheet music images with accompanying metadata useful in OMR research. Our dataset provides OMR metadata, MIDI, MEI, MusicXML and PNG files, each aiding a different stage of OMR. We obtain 64% mean average precision (mAP) in object detection using half of the data. Further work includes re-iterating through the creation process to satisfy custom OMR models. While we do not assume to have solved the main challenges in OMR, this dataset opens a new course of discussions that would ultimately aid that goal.
An Indoor Environment Sensing and Localization System via mmWave Phased Array
Jun 07, 2022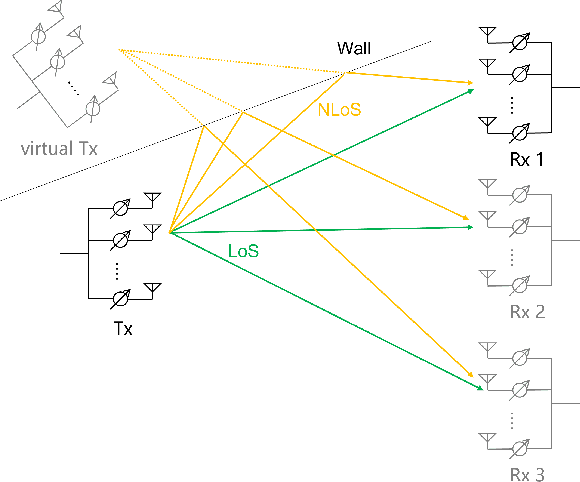
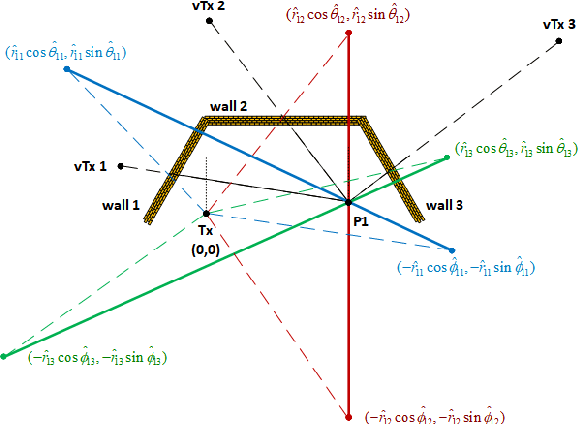
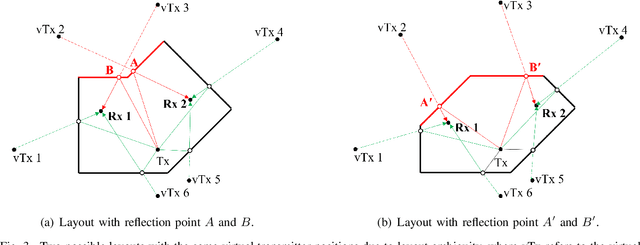
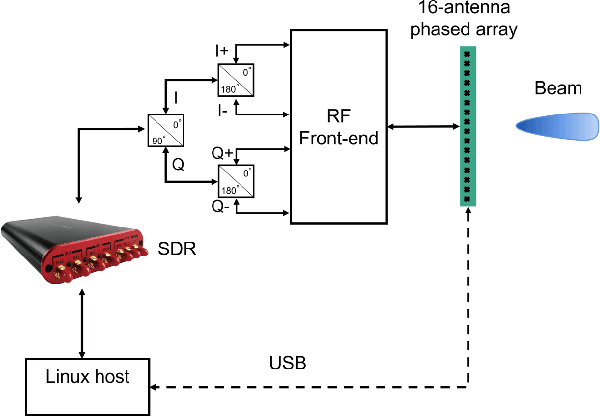
An indoor layout sensing and localization system in 60GHz millimeter wave (mmWave) band, named mmReality, is elaborated in this paper. The mmReality system consists of one transmitter and one mobile receiver, each with a phased array and a single radio frequency (RF) chain. To reconstruct the room layout, the pilot signal is delivered from the transmitter to the receiver via different pairs of transmission and receiving beams, so that the signals at all antenna elements can be resolved. Then, the spatial smoothing and two-dimensional multiple signal classification (MUSIC) algorithm is applied to detect the angle-of-arrival (AoAs) and angle-of-departure (AoDs) of the rays from the transmitter to the receiver. Moreover, the technique of multi-carrier ranging is adopted to measure the distance of each propagation path. Synthesizing the above geometrical parameters, the location of receiver relative to the transmitter can be pinpointed, both line-of-sight (LoS) and non-line-of-sight (NLoS) paths can also be determined. Therefore, the room layout can be reconstructed by moving the receiver and repeating the above measurement in different locations of the room. At the end, we show that the reconstructed room layout can be utilized to locate a mobile device according to its AoA spectrum, even with single access point.
Contrastive Learning of Musical Representations
Mar 17, 2021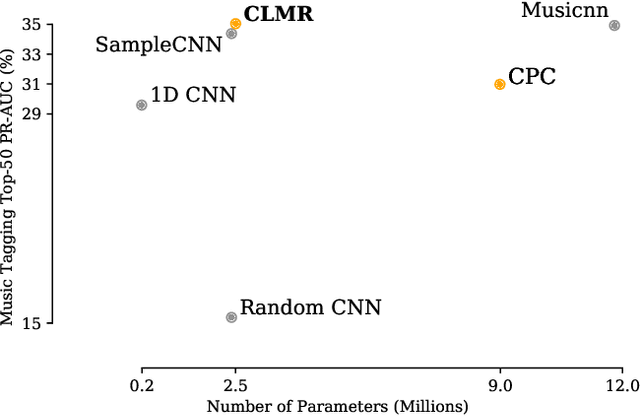
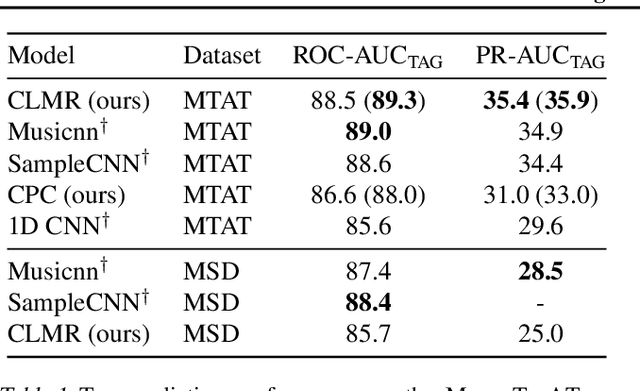
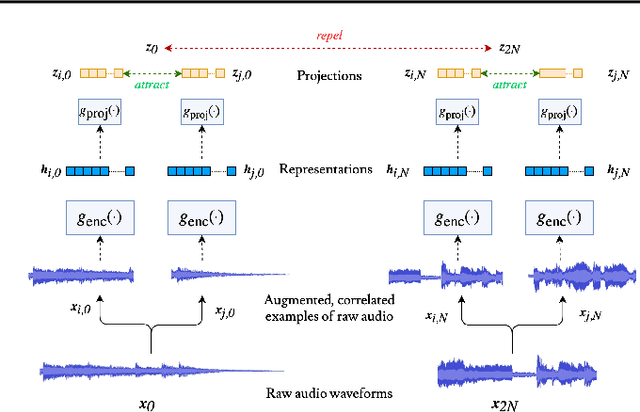
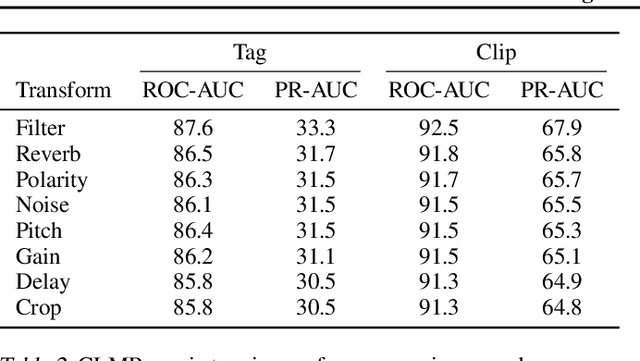
While supervised learning has enabled great advances in many areas of music, labeled music datasets remain especially hard, expensive and time-consuming to create. In this work, we introduce SimCLR to the music domain and contribute a large chain of audio data augmentations, to form a simple framework for self-supervised learning of raw waveforms of music: CLMR. This approach requires no manual labeling and no preprocessing of music to learn useful representations. We evaluate CLMR in the downstream task of music classification on the MagnaTagATune and Million Song datasets. A linear classifier fine-tuned on representations from a pre-trained CLMR model achieves an average precision of 35.4% on the MagnaTagATune dataset, superseding fully supervised models that currently achieve a score of 34.9%. Moreover, we show that CLMR's representations are transferable using out-of-domain datasets, indicating that they capture important musical knowledge. Lastly, we show that self-supervised pre-training allows us to learn efficiently on smaller labeled datasets: we still achieve a score of 33.1% despite using only 259 labeled songs during fine-tuning. To foster reproducibility and future research on self-supervised learning in music, we publicly release the pre-trained models and the source code of all experiments of this paper on GitHub.