 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TAN: Temporal Affine Network for Real-Time Left Ventricle Anatomical Structure Analysis Based on 2D Ultrasound Videos
Apr 01, 2019
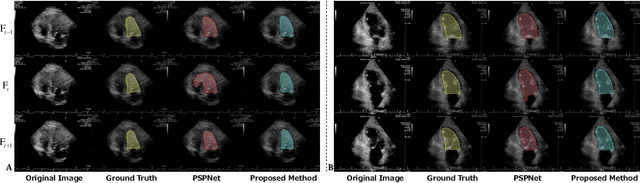
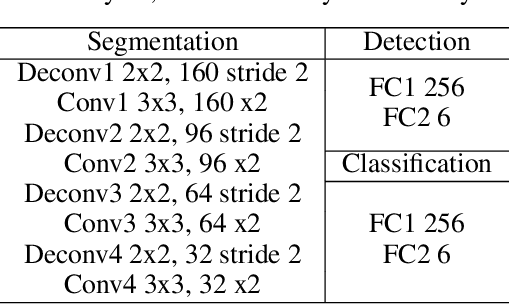
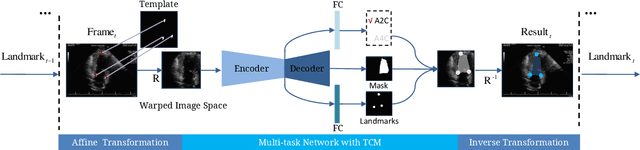
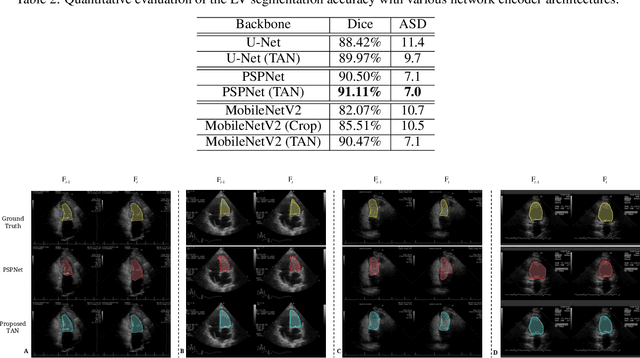
With superiorities on low cost, portability, and free of radiation, echocardiogram is a widely used imaging modality for left ventricle (LV) function quantification. However, automatic LV segmentation and motion tracking is still a challenging task. In addition to fuzzy border definition, low contrast, and abounding artifacts on typical ultrasound images, the shape and size of the LV change significantly in a cardiac cycle. In this work, we propose a temporal affine network (TAN) to perform image analysis in a warped image space, where the shape and size variations due to the cardiac motion as well as other artifacts are largely compensated. Furthermore, we perform three frequent echocardiogram interpretation tasks simultaneously: standard cardiac plane recognition, LV landmark detection, and LV segmentation. Instead of using three networks with one dedicating to each task, we use a multi-task network to perform three tasks simultaneously. Since three tasks share the same encoder, the compact network improves the segmentation accuracy with more supervision. The network is further finetuned with optical flow adjusted annotations to enhance motion coherence in the segmentation result. Experiments on 1,714 2D echocardiographic sequences demonstrate that the proposed method achieves state-of-the-art segmentation accuracy with real-time efficiency.
Leveraging Patient Similarity and Time Series Data in Healthcare Predictive Models
Apr 30, 2017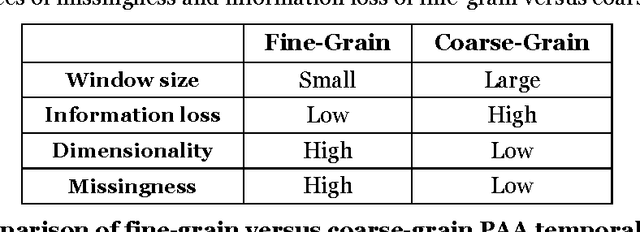
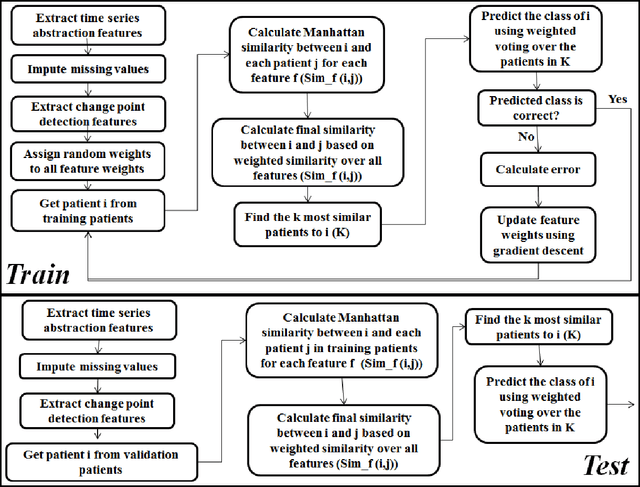
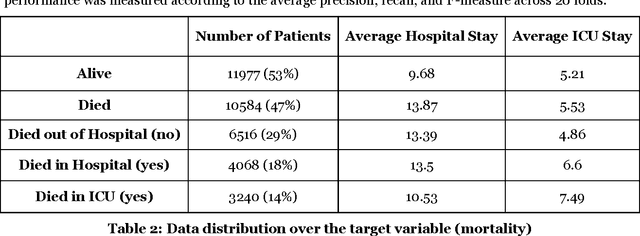
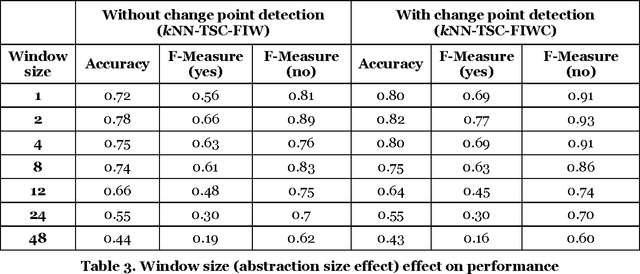
Patient time series classification faces challenges in high degrees of dimensionality and missingness. In light of patient similarity theory, this study explores effective temporal feature engineering and reduction, missing value imputation, and change point detection methods that can afford similarity-based classification models with desirable accuracy enhancement. We select a piecewise aggregation approximation method to extract fine-grain temporal features and propose a minimalist method to impute missing values in temporal features. For dimensionality reduction, we adopt a gradient descent search method for feature weight assignment. We propose new patient status and directional change definitions based on medical knowledge or clinical guidelines about the value ranges for different patient status levels, and develop a method to detect change points indicating positive or negative patient status changes. We evaluate the effectiveness of the proposed methods in the context of early Intensive Care Unit mortality prediction. The evaluation results show that the k-Nearest Neighbor algorithm that incorporates methods we select and propose significantly outperform the relevant benchmarks for early ICU mortality prediction. This study makes contributions to time series classification and early ICU mortality prediction via identifying and enhancing temporal feature engineering and reduction methods for similarity-based time series classification.
Designing a Mobile Social and Vocational Reintegration Assistant for Burn-out Outpatient Treatment
Dec 15, 2020
Using Social Agents as health-care assistants or trainers is one focus area of IVA research. While their use as physical health-care agents is well established, their employment in the field of psychotherapeutic care comes with daunting challenges. This paper presents our mobile Social Agent EmmA in the role of a vocational reintegration assistant for burn-out outpatient treatment. We follow a typical participatory design approach including experts and patients in order to address requirements from both sides. Since the success of such treatments is related to a patients emotion regulation capabilities, we employ a real-time social signal interpretation together with a computational simulation of emotion regulation that influences the agent's social behavior as well as the situational selection of verbal treatment strategies. Overall, our interdisciplinary approach enables a novel integrative concept for Social Agents as assistants for burn-out patients.
Deep Spectral CNN for Laser Induced Breakdown Spectroscopy
Dec 03, 2020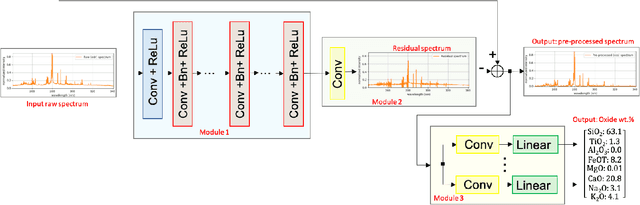
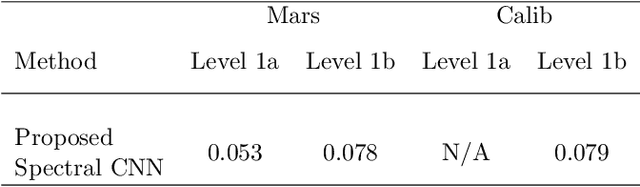
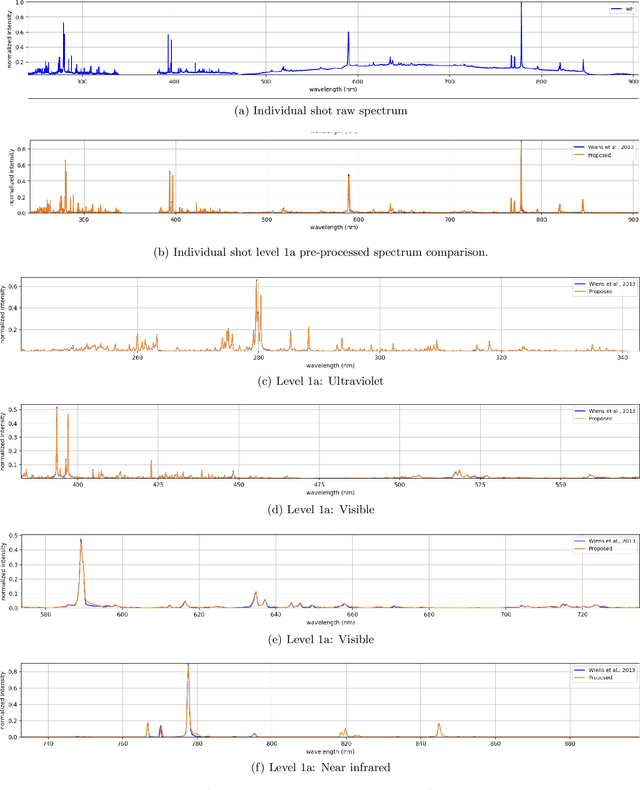
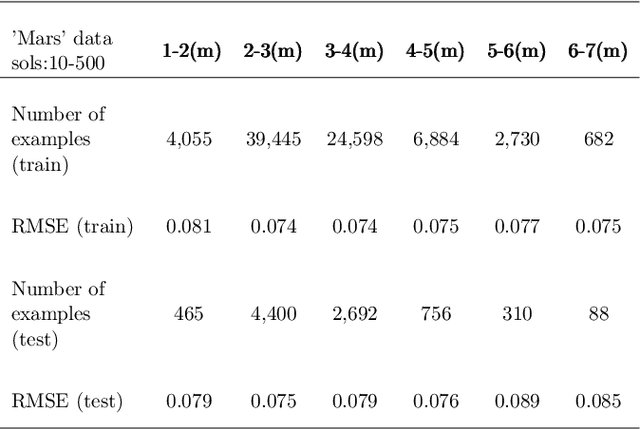
This work proposes a spectral convolutional neural network (CNN) operating on laser induced breakdown spectroscopy (LIBS) signals to learn to (1) disentangle spectral signals from the sources of sensor uncertainty (i.e., pre-process) and (2) get qualitative and quantitative measures of chemical content of a sample given a spectral signal (i.e., calibrate). Once the spectral CNN is trained, it can accomplish either task through a single feed-forward pass, with real-time benefits and without any additional side information requirements including dark current, system response, temperature and detector-to-target range. Our experiments demonstrate that the proposed method outperforms the existing approaches used by the Mars Science Lab for pre-processing and calibration for remote sensing observations from the Mars rover, 'Curiosity'.
On Uncensored Mean First-Passage-Time Performance Experiments with Multiwalk in $\mathbb{R}^p$: a New Stochastic Optimization Algorithm
Dec 06, 2018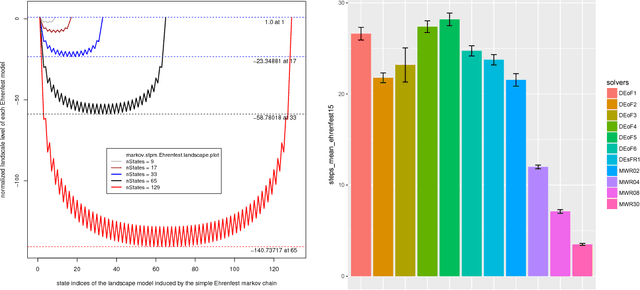
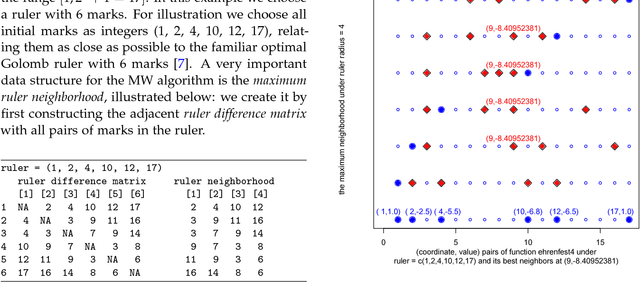

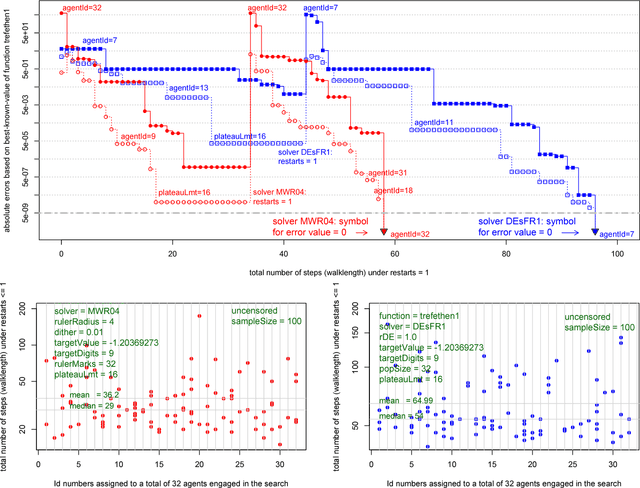
A rigorous empirical comparison of two stochastic solvers is important when one of the solvers is a prototype of a new algorithm such as multiwalk (MWA). When searching for global minima in $\mathbb{R}^p$, the key data structures of MWA include: $p$ rulers with each ruler assigned $m$ marks and a set of $p$ neighborhood matrices of size up to $m(m-2)$, where each entry represents absolute values of pairwise differences between $m$ marks. Before taking the next step, a controller links the tableau of neighborhood matrices and computes new and improved positions for each of the $m$ marks. The number of columns in each neighborhood matrix is denoted as the neighborhood radius $r_n \le m-2$. Any variant of the DEA (differential evolution algorithm) has an effective population neighborhood of radius not larger than 1. Uncensored first-passage-time performance experiments that vary the neighborhood radius of a MW-solver can thus be readily compared to existing variants of DE-solvers. The paper considers seven test cases of increasing complexity and demonstrates, under uncensored first-passage-time performance experiments: (1) significant variability in convergence rate for seven DE-based solver configurations, and (2) consistent, monotonic, and significantly faster rate of convergence for the MW-solver prototype as we increase the neighborhood radius from 4 to its maximum value.
Evaluating Noisy Optimisation Algorithms: First Hitting Time is Problematic
Jul 12, 2017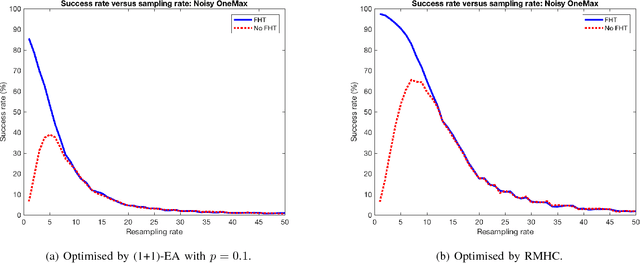
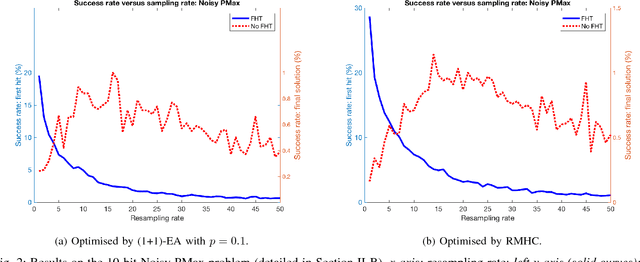

A key part of any evolutionary algorithm is fitness evaluation. When fitness evaluations are corrupted by noise, as happens in many real-world problems as a consequence of various types of uncertainty, a strategy is needed in order to cope with this. Resampling is one of the most common strategies, whereby each solution is evaluated many times in order to reduce the variance of the fitness estimates. When evaluating the performance of a noisy optimisation algorithm, a key consideration is the stopping condition for the algorithm. A frequently used stopping condition in runtime analysis, known as "First Hitting Time", is to stop the algorithm as soon as it encounters the optimal solution. However, this is unrealistic for real-world problems, as if the optimal solution were already known, there would be no need to search for it. This paper argues that the use of First Hitting Time, despite being a commonly used approach, is significantly flawed and overestimates the quality of many algorithms in real-world cases, where the optimum is not known in advance and has to be genuinely searched for. A better alternative is to measure the quality of the solution an algorithm returns after a fixed evaluation budget, i.e., to focus on final solution quality. This paper argues that focussing on final solution quality is more realistic and demonstrates cases where the results produced by each algorithm evaluation method lead to very different conclusions regarding the quality of each noisy optimisation algorithm.
Machine Learning for Temporal Data in Finance: Challenges and Opportunities
Sep 11, 2020
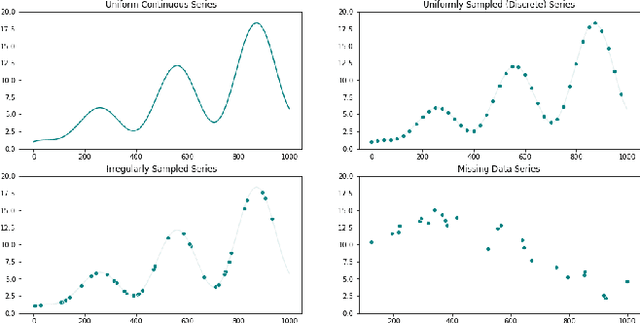
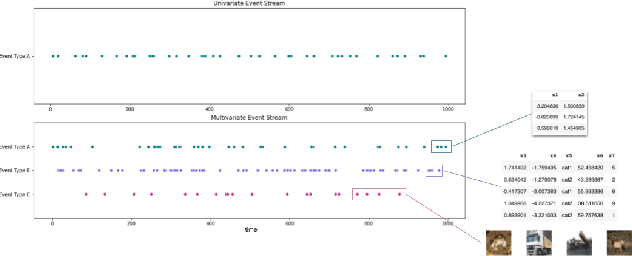
Temporal data are ubiquitous in the financial services (FS) industry -- traditional data like economic indicators, operational data such as bank account transactions, and modern data sources like website clickstreams -- all of these occur as a time-indexed sequence. But machine learning efforts in FS often fail to account for the temporal richness of these data, even in cases where domain knowledge suggests that the precise temporal patterns between events should contain valuable information. At best, such data are often treated as uniform time series, where there is a sequence but no sense of exact timing. At worst, rough aggregate features are computed over a pre-selected window so that static sample-based approaches can be applied (e.g. number of open lines of credit in the previous year or maximum credit utilization over the previous month). Such approaches are at odds with the deep learning paradigm which advocates for building models that act directly on raw or lightly processed data and for leveraging modern optimization techniques to discover optimal feature transformations en route to solving the modeling task at hand. Furthermore, a full picture of the entity being modeled (customer, company, etc.) might only be attainable by examining multiple data streams that unfold across potentially vastly different time scales. In this paper, we examine the different types of temporal data found in common FS use cases, review the current machine learning approaches in this area, and finally assess challenges and opportunities for researchers working at the intersection of machine learning for temporal data and applications in FS.
HiPPO: Recurrent Memory with Optimal Polynomial Projections
Aug 17, 2020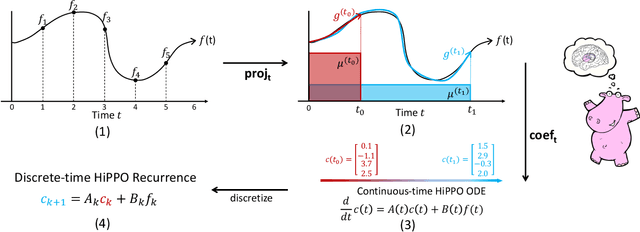

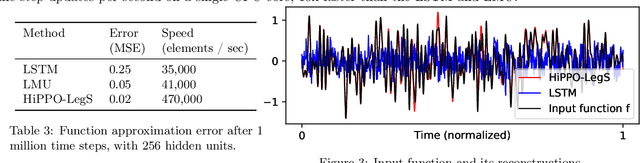
A central problem in learning from sequential data is representing cumulative history in an incremental fashion as more data is processed. We introduce a general framework (HiPPO) for the online compression of continuous signals and discrete time series by projection onto polynomial bases. Given a measure that specifies the importance of each time step in the past, HiPPO produces an optimal solution to a natural online function approximation problem. As special cases, our framework yields a short derivation of the recent Legendre Memory Unit (LMU) from first principles, and generalizes the ubiquitous gating mechanism of recurrent neural networks such as GRUs. This formal framework yields a new memory update mechanism (HiPPO-LegS) that scales through time to remember all history, avoiding priors on the timescale. HiPPO-LegS enjoys the theoretical benefits of timescale robustness, fast updates, and bounded gradients. By incorporating the memory dynamics into recurrent neural networks, HiPPO RNNs can empirically capture complex temporal dependencies. On the benchmark permuted MNIST dataset, HiPPO-LegS sets a new state-of-the-art accuracy of 98.3%. Finally, on a novel trajectory classification task testing robustness to out-of-distribution timescales and missing data, HiPPO-LegS outperforms RNN and neural ODE baselines by 25-40% accuracy.
On Efficient Low Distortion Ultrametric Embedding
Aug 15, 2020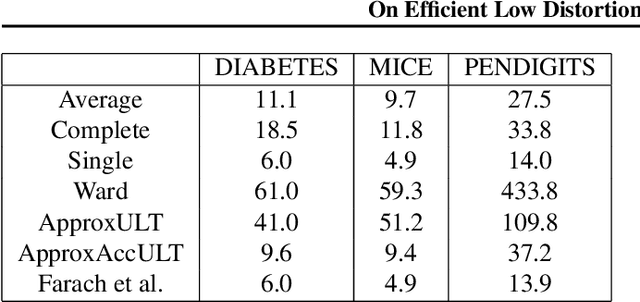
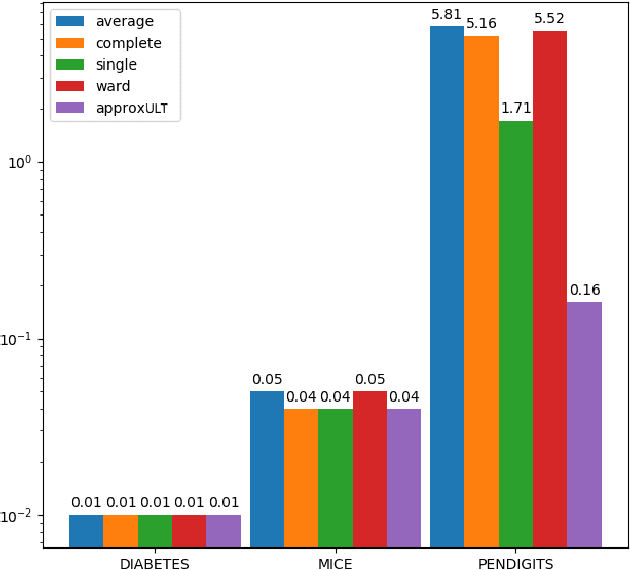
A classic problem in unsupervised learning and data analysis is to find simpler and easy-to-visualize representations of the data that preserve its essential properties. A widely-used method to preserve the underlying hierarchical structure of the data while reducing its complexity is to find an embedding of the data into a tree or an ultrametric. The most popular algorithms for this task are the classic linkage algorithms (single, average, or complete). However, these methods on a data set of $n$ points in $\Omega(\log n)$ dimensions exhibit a quite prohibitive running time of $\Theta(n^2)$. In this paper, we provide a new algorithm which takes as input a set of points $P$ in $\mathbb{R}^d$, and for every $c\ge 1$, runs in time $n^{1+\frac{\rho}{c^2}}$ (for some universal constant $\rho>1$) to output an ultrametric $\Delta$ such that for any two points $u,v$ in $P$, we have $\Delta(u,v)$ is within a multiplicative factor of $5c$ to the distance between $u$ and $v$ in the "best" ultrametric representation of $P$. Here, the best ultrametric is the ultrametric $\tilde\Delta$ that minimizes the maximum distance distortion with respect to the $\ell_2$ distance, namely that minimizes $\underset{u,v \in P}{\max}\ \frac{\tilde\Delta(u,v)}{\|u-v\|_2}$. We complement the above result by showing that under popular complexity theoretic assumptions, for every constant $\varepsilon>0$, no algorithm with running time $n^{2-\varepsilon}$ can distinguish between inputs in $\ell_\infty$-metric that admit isometric embedding and those that incur a distortion of $\frac{3}{2}$. Finally, we present empirical evaluation on classic machine learning datasets and show that the output of our algorithm is comparable to the output of the linkage algorithms while achieving a much faster running time.
Classification of Periodic Variable Stars with Novel Cyclic-Permutation Invariant Neural Networks
Nov 02, 2020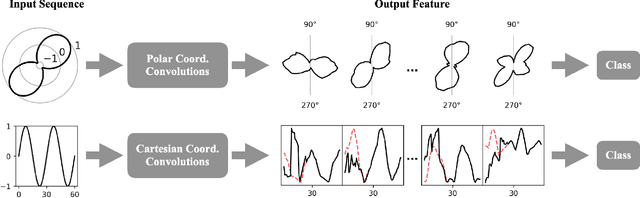
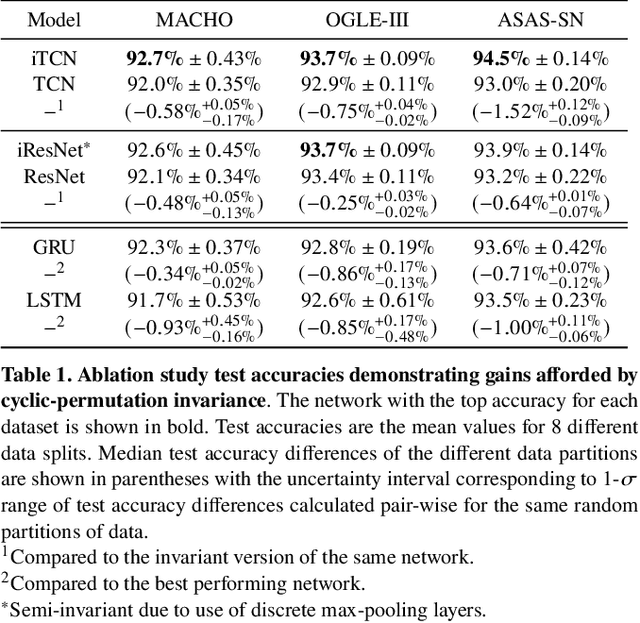
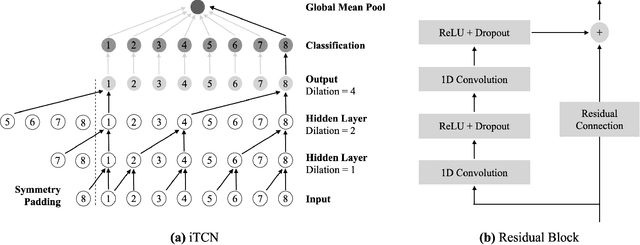
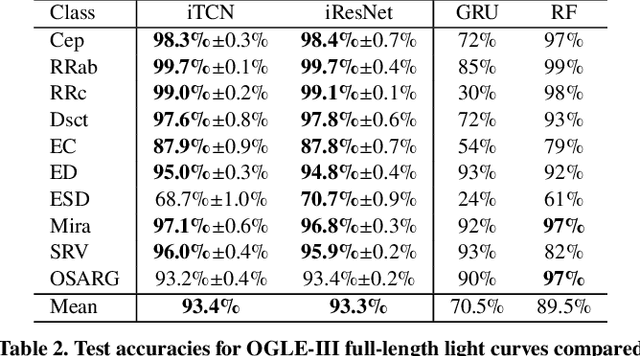
Neural networks (NNs) have been shown to be competitive against state-of-the-art feature engineering and random forest (RF) classification of periodic variable stars. Although previous work utilising NNs has made use of periodicity by period folding multiple-cycle time-series into a single cycle---from time-space to phase-space---no approach to date has taken advantage of the fact that network predictions should be invariant to the initial phase of the period-folded sequence. Initial phase is exogenous to the physical origin of the variability and should thus be factored out. Here, we present cyclic-permutation invariant networks, a novel class of NNs for which invariance to phase shifts is guaranteed through polar coordinate convolutions, which we implement by means of "Symmetry Padding." Across three different datasets of variable star light curves, we show that two implementations of the cyclic-permutation invariant network: the iTCN and the iResNet, consistently outperform non-invariant baselines and reduce overall error rates by between 4% to 22%. Over a 10-class OGLE-III sample, the iTCN/iResNet achieves an average per-class accuracy of 93.4%/93.3%, compared to RNN/RF accuracies of 70.5%/89.5% in a recent study using the same data. Finding improvement on a non-astronomy benchmark, we suggest that the methodology introduced here should also be applicable to a wide range of science domains where periodic data abounds due to physical symmetries.