 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Nov 19, 2019


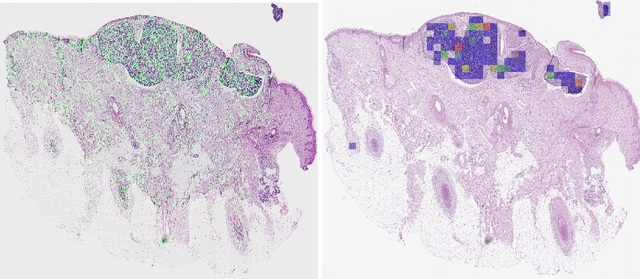
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.95.
A Local Descriptor with Physiological Characteristic for Finger Vein Recognition
Apr 16, 2020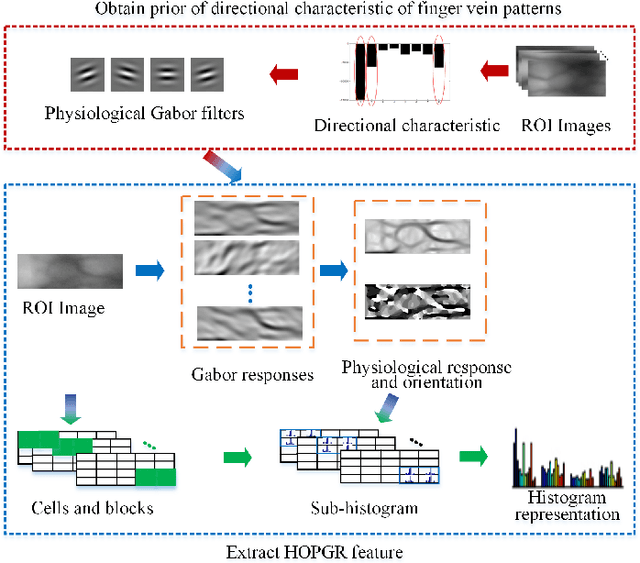

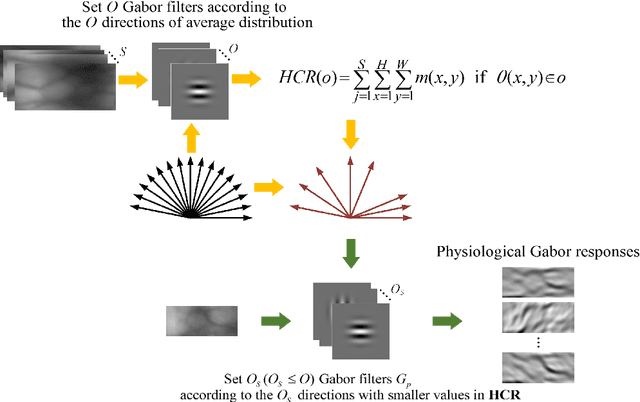
Local feature descriptors exhibit great superiority in finger vein recognition due to their stability and robustness against local changes in images. However, most of these are methods use general-purpose descriptors that do not consider finger vein-specific features. In this work, we propose a finger vein-specific local feature descriptors based physiological characteristic of finger vein patterns, i.e., histogram of oriented physiological Gabor responses (HOPGR), for finger vein recognition. First, prior of directional characteristic of finger vein patterns is obtained in an unsupervised manner. Then the physiological Gabor filter banks are set up based on the prior information to extract the physiological responses and orientation. Finally, to make feature has robustness against local changes in images, histogram is generated as output by dividing the image into non-overlapping cells and overlapping blocks. Extensive experimental results on several databases clearly demonstrate that the proposed method outperforms most current state-of-the-art finger vein recognition methods.
ESRGAN+ : Further Improving Enhanced Super-Resolution Generative Adversarial Network
Jan 21, 2020

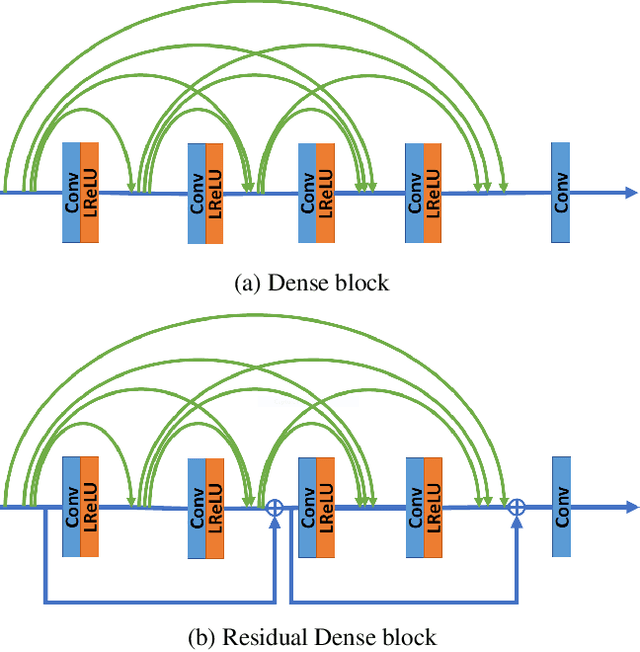
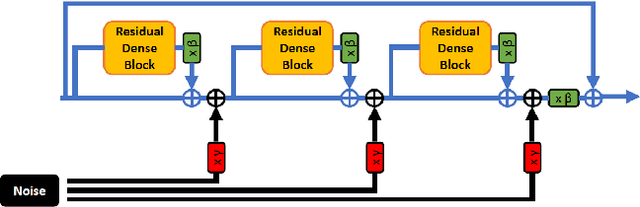
Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) is a perceptual-driven approach for single image super resolution that is able to produce photorealistic images. Despite the visual quality of these generated images, there is still room for improvement. In this fashion, the model is extended to further improve the perceptual quality of the images. We have designed a novel block to replace the one used by the original ESRGAN. Moreover, we introduce noise inputs to the generator network in order to exploit stochastic variation. The resulting images present more realistic textures.
When Differential Privacy Meets Graph Neural Networks
Jun 12, 2020
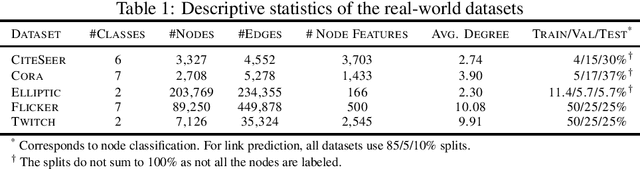
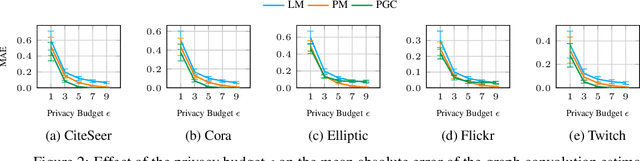
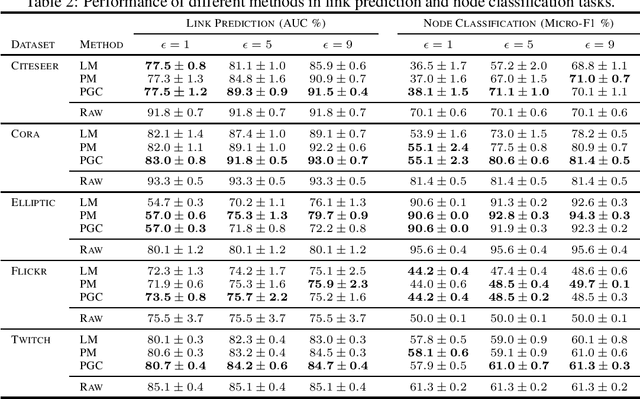
Graph Neural Networks have demonstrated superior performance in learning graph representations for several subsequent downstream inference tasks. However, learning over graph data types can raise privacy concerns when nodes represent people or human-related variables that involve personal information about individuals. Previous works have presented various techniques for privacy-preserving deep learning over non-relational data, such as image, audio, video, and text, but there is less work addressing the privacy issues involved in applying deep learning algorithms on graphs. As a result and for the first time, in this paper, we develop a privacy-preserving learning algorithm with formal privacy guarantees for Graph Convolutional Networks (GCNs) based on Local Differential Privacy (LDP) to tackle the problem of node-level privacy, where graph nodes have potentially sensitive features that need to be kept private, but they could be beneficial for learning rich node representations in a centralized learning setting. Specifically, we propose an LDP algorithm in which a central server can communicate with graph nodes to privately collect their data and estimate the graph convolution layer of a GCN. We then analyze the theoretical characteristics of the method and compare it with state-of-the-art mechanisms. Experimental results over real-world graph datasets demonstrate the effectiveness of the proposed method for both privacy-preserving node classification and link prediction tasks and verify our theoretical findings.
Classification of Chest Diseases using Wavelet Transforms and Transfer Learning
Feb 03, 2020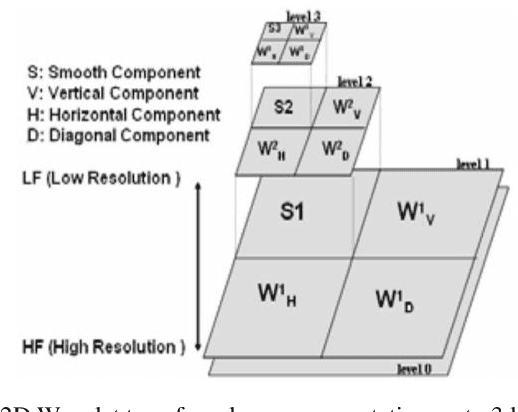

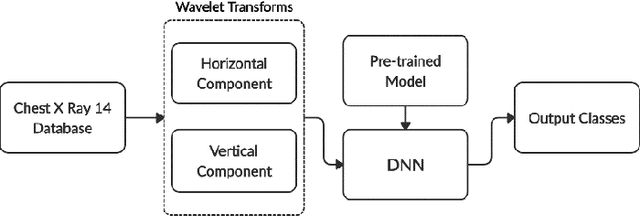
Chest X-ray scan is a most often used modality by radiologists to diagnose many chest related diseases in their initial stages. The proposed system aids the radiologists in making decision about the diseases found in the scans more efficiently. Our system combines the techniques of image processing for feature enhancement and deep learning for classification among diseases. We have used the ChestX-ray14 database in order to train our deep learning model on the 14 different labeled diseases found in it. The proposed research shows the significant improvement in the results by using wavelet transforms as pre-processing technique.
Landslide Segmentation with U-Net: Evaluating Different Sampling Methods and Patch Sizes
Jul 13, 2020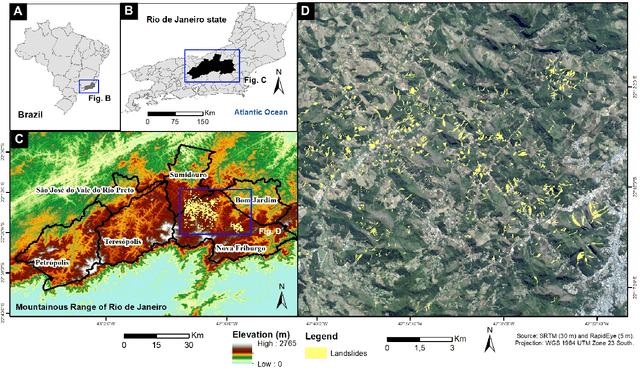


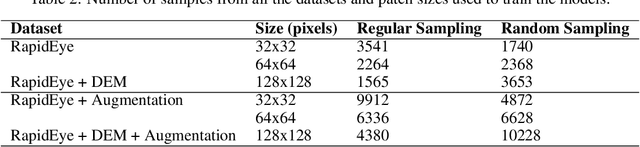
Landslide inventory maps are crucial to validate predictive landslide models; however, since most mapping methods rely on visual interpretation or expert knowledge, detailed inventory maps are still lacking. This study used a fully convolutional deep learning model named U-net to automatically segment landslides in the city of Nova Friburgo, located in the mountainous range of Rio de Janeiro, southeastern Brazil. The objective was to evaluate the impact of patch sizes, sampling methods, and datasets on the overall accuracy of the models. The training data used the optical information from RapidEye satellite, and a digital elevation model (DEM) derived from the L-band sensor of the ALOS satellite. The data was sampled using random and regular grid methods and patched in three sizes (32x32, 64x64, and 128x128 pixels). The models were evaluated on two areas with precision, recall, f1-score, and mean intersect over union (mIoU) metrics. The results show that the models trained with 32x32 tiles tend to have higher recall values due to higher true positive rates; however, they misclassify more background areas as landslides (false positives). Models trained with 128x128 tiles usually achieve higher precision values because they make less false positive errors. In both test areas, DEM and augmentation increased the accuracy of the models. Random sampling helped in model generalization. Models trained with 128x128 random tiles from the data that used the RapidEye image, DEM information, and augmentation achieved the highest f1-score, 0.55 in test area one, and 0.58 in test area two. The results achieved in this study are comparable to other fully convolutional models found in the literature, increasing the knowledge in the area.
Image Segmentation by Size-Dependent Single Linkage Clustering of a Watershed Basin Graph
May 01, 2015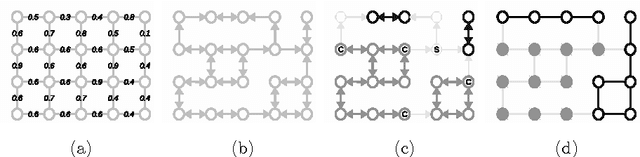
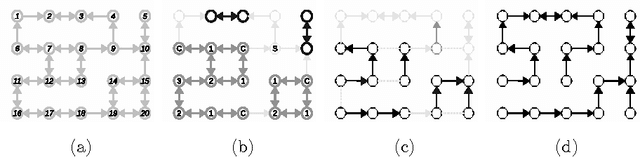

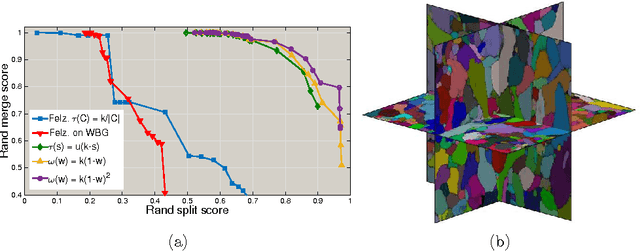
We present a method for hierarchical image segmentation that defines a disaffinity graph on the image, over-segments it into watershed basins, defines a new graph on the basins, and then merges basins with a modified, size-dependent version of single linkage clustering. The quasilinear runtime of the method makes it suitable for segmenting large images. We illustrate the method on the challenging problem of segmenting 3D electron microscopic brain images.
Two-stage Geometric Information Guided Image Reconstruction
Sep 26, 2014
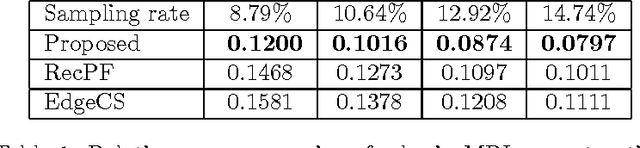
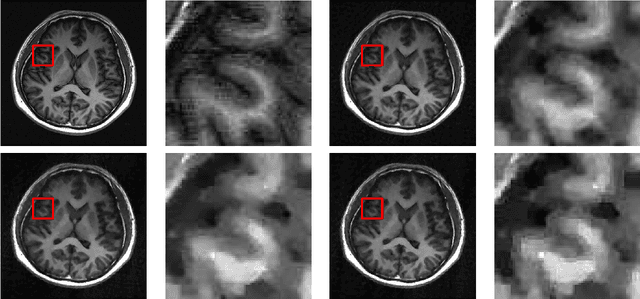
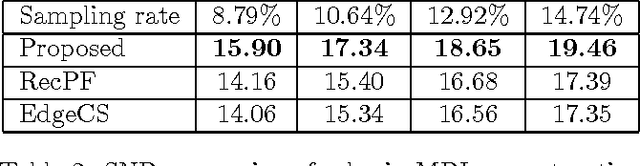
In compressive sensing, it is challenging to reconstruct image of high quality from very few noisy linear projections. Existing methods mostly work well on piecewise constant images but not so well on piecewise smooth images such as natural images, medical images that contain a lot of details. We propose a two-stage method called GeoCS to recover images with rich geometric information from very limited amount of noisy measurements. The method adopts the shearlet transform that is mathematically proven to be optimal in sparsely representing images containing anisotropic features such as edges, corners, spikes etc. It also uses the weighted total variation (TV) sparsity with spatially variant weights to preserve sharp edges but to reduce the staircase effects of TV. Geometric information extracted from the results of stage I serves as an initial prior for stage II which alternates image reconstruction and geometric information update in a mutually beneficial way. GeoCS has been tested on incomplete spectral Fourier samples. It is applicable to other types of measurements as well. Experimental results on various complicated images show that GeoCS is efficient and generates high-quality images.
A New Ratio Image Based CNN Algorithm For SAR Despeckling
Jun 10, 2019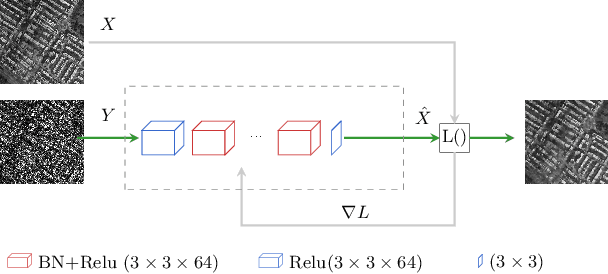
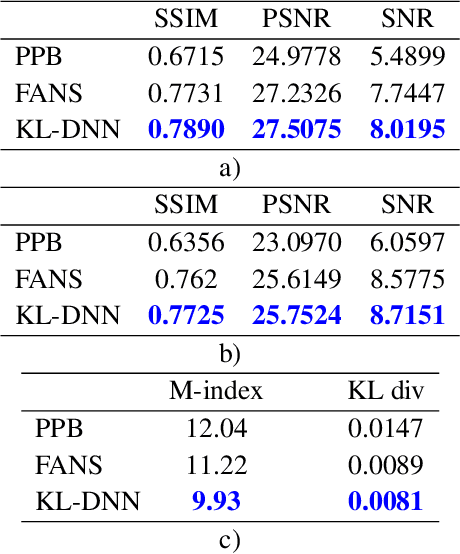


In SAR domain many application like classification, detection and segmentation are impaired by speckle. Hence, despeckling of SAR images is the key for scene understanding. Usually despeckling filters face the trade-off of speckle suppression and information preservation. In the last years deep learning solutions for speckle reduction have been proposed. One the biggest issue for these methods is how to train a network given the lack of a reference. In this work we proposed a convolutional neural network based solution trained on simulated data. We propose the use of a cost function taking into account both spatial and statistical properties. The aim is two fold: overcome the trade-off between speckle suppression and details suppression; find a suitable cost function for despeckling in unsupervised learning. The algorithm is validated on both real and simulated data, showing interesting performances.
Extreme Few-view CT Reconstruction using Deep Inference
Oct 11, 2019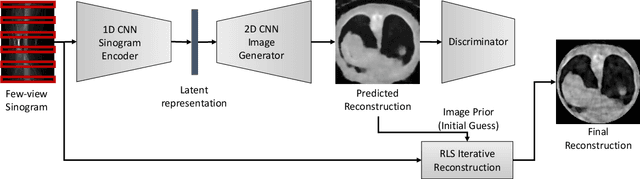
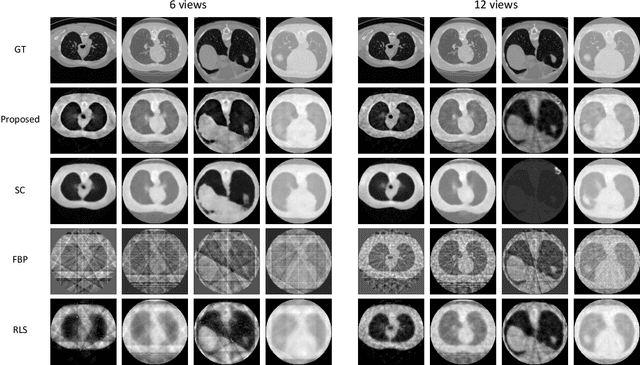
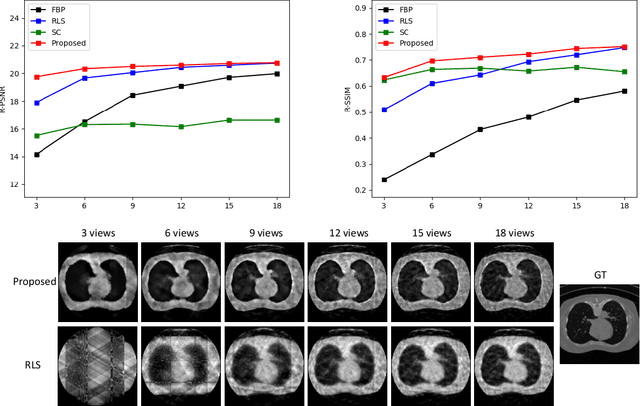
Reconstruction of few-view x-ray Computed Tomography (CT) data is a highly ill-posed problem. It is often used in applications that require low radiation dose in clinical CT, rapid industrial scanning, or fixed-gantry CT. Existing analytic or iterative algorithms generally produce poorly reconstructed images, severely deteriorated by artifacts and noise, especially when the number of x-ray projections is considerably low. This paper presents a deep network-driven approach to address extreme few-view CT by incorporating convolutional neural network-based inference into state-of-the-art iterative reconstruction. The proposed method interprets few-view sinogram data using attention-based deep networks to infer the reconstructed image. The predicted image is then used as prior knowledge in the iterative algorithm for final reconstruction. We demonstrate effectiveness of the proposed approach by performing reconstruction experiments on a chest CT dataset.