 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Wide-Area Image Geolocalization with Aerial Reference Imagery
Oct 13, 2015
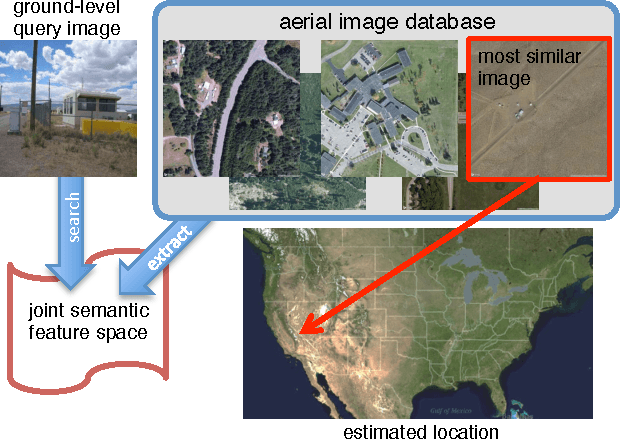
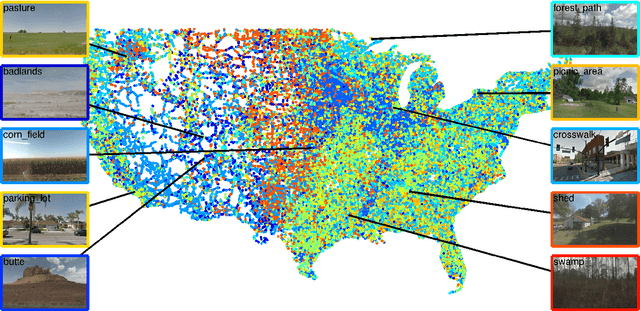
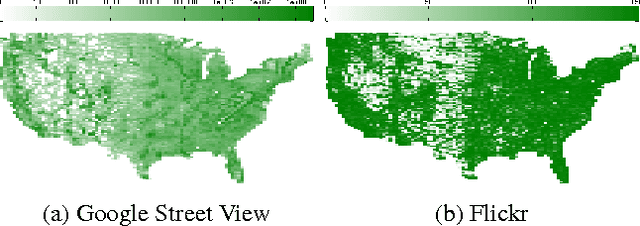

We propose to use deep convolutional neural networks to address the problem of cross-view image geolocalization, in which the geolocation of a ground-level query image is estimated by matching to georeferenced aerial images. We use state-of-the-art feature representations for ground-level images and introduce a cross-view training approach for learning a joint semantic feature representation for aerial images. We also propose a network architecture that fuses features extracted from aerial images at multiple spatial scales. To support training these networks, we introduce a massive database that contains pairs of aerial and ground-level images from across the United States. Our methods significantly out-perform the state of the art on two benchmark datasets. We also show, qualitatively, that the proposed feature representations are discriminative at both local and continental spatial scales.
Computational optimization of convolutional neural networks using separated filters architecture
Feb 18, 2020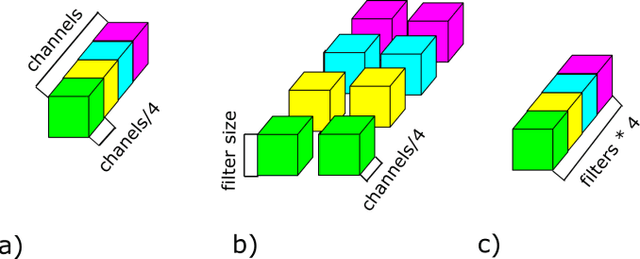
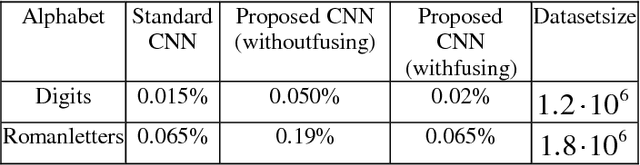
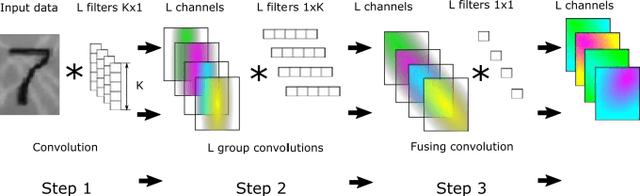
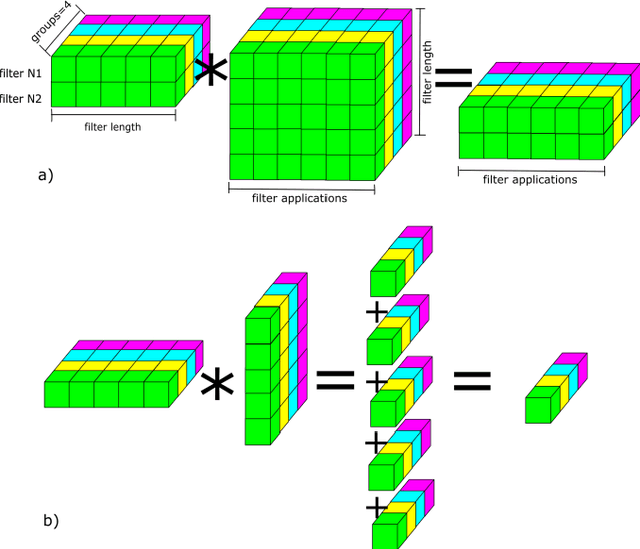
This paper considers a convolutional neural network transformation that reduces computation complexity and thus speedups neural network processing. Usage of convolutional neural networks (CNN) is the standard approach to image recognition despite the fact they can be too computationally demanding, for example for recognition on mobile platforms or in embedded systems. In this paper we propose CNN structure transformation which expresses 2D convolution filters as a linear combination of separable filters. It allows to obtain separated convolutional filters by standard training algorithms. We study the computation efficiency of this structure transformation and suggest fast implementation easily handled by CPU or GPU. We demonstrate that CNNs designed for letter and digit recognition of proposed structure show 15% speedup without accuracy loss in industrial image recognition system. In conclusion, we discuss the question of possible accuracy decrease and the application of proposed transformation to different recognition problems. convolutional neural networks, computational optimization, separable filters, complexity reduction.
* 4 pages, 3 figures
Learning Output Embeddings in Structured Prediction
Jul 30, 2020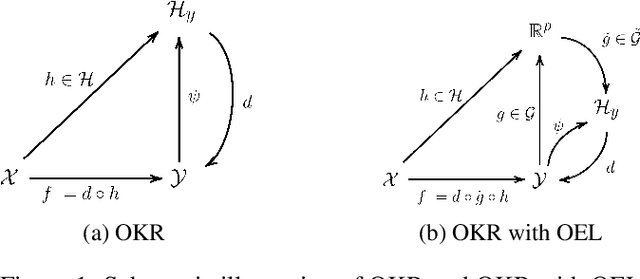


A powerful and flexible approach to structured prediction consists in embedding the structured objects to be predicted into a feature space of possibly infinite dimension, and then, solving a regression problem in this output space. A prediction in the original space is computed by solving a pre-image problem. In such an approach, the embedding, linked to the target loss, is defined prior to the learning phase. In this work, we propose to jointly learn an approximation of the output embedding and the regression function into the new feature space. Output Embedding Learning (OEL) allows to leverage a priori information on the outputs and also unexploited unsupervised output data, which are both often available in structured prediction problems. We give a general learning method that we theoretically study in the linear case, proving consistency and excess-risk bound. OEL is tested on various structured prediction problems, showing its versatility and reveals to be especially useful when the training dataset is small compared to the complexity of the task.
Rapid Whole-Heart CMR with Single Volume Super-resolution
Dec 22, 2019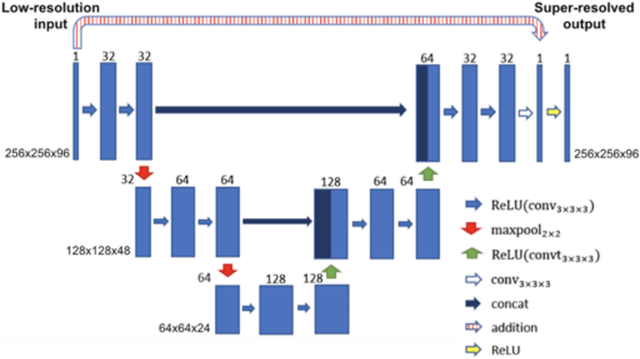
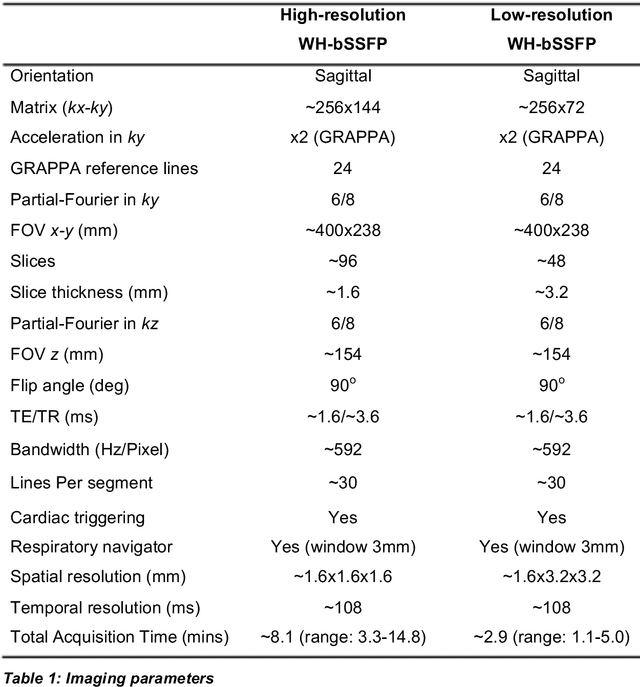
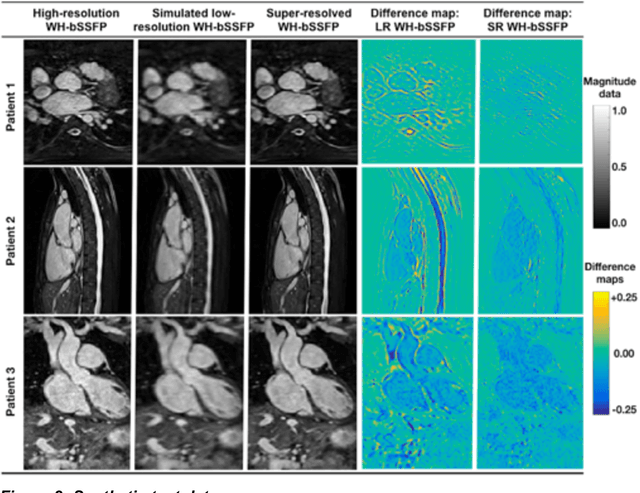
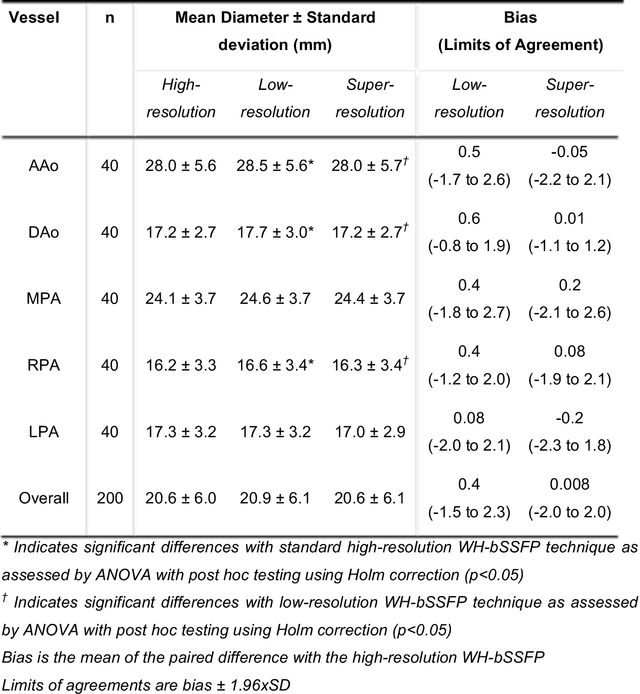
Background: Three-dimensional, whole heart, balanced steady state free precession (WH-bSSFP) sequences provide delineation of intra-cardiac and vascular anatomy. However, they have long acquisition times. Here, we propose significant speed ups using a deep learning single volume super resolution reconstruction, to recover high resolution features from rapidly acquired low resolution WH-bSSFP images. Methods: A 3D residual U-Net was trained using synthetic data, created from a library of high-resolution WH-bSSFP images by simulating 0.5 slice resolution and 0.5 phase resolution. The trained network was validated with synthetic test data, as well as prospective low-resolution data. Results: Synthetic low-resolution data had significantly better image quality after super-resolution reconstruction. Qualitative image scores showed super-resolved images had better edge sharpness, fewer residual artefacts and less image distortion than low-resolution images, with similar scores to high-resolution data. Quantitative image scores showed super-resolved images had significantly better edge sharpness than low-resolution or high-resolution images, with significantly better signal-to-noise ratio than high-resolution data. Vessel diameters measurements showed over-estimation in the low-resolution measurements, compared to the high-resolution data. No significant differences and no bias was found in the super-resolution measurements. Conclusion: This paper demonstrates the potential of using a residual U-Net for super-resolution reconstruction of rapidly acquired low-resolution whole heart bSSFP data within a clinical setting. The resulting network can be applied very quickly, making these techniques particularly appealing within busy clinical workflow. Thus, we believe that this technique may help speed up whole heart CMR in clinical practice.
Convolutional Networks for Image Processing by Coupled Oscillator Arrays
Sep 15, 2014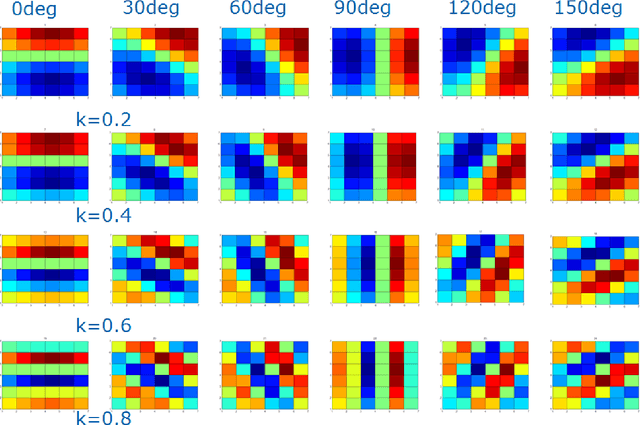
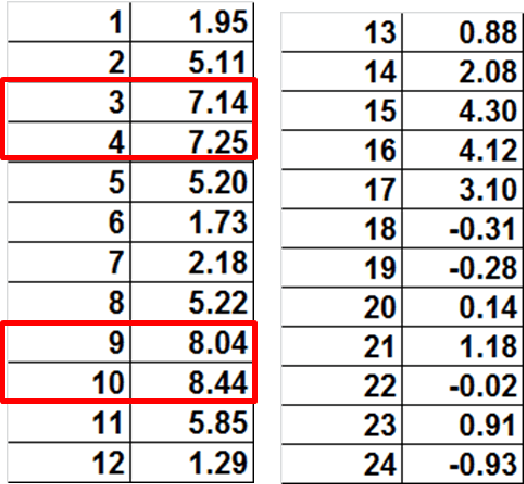
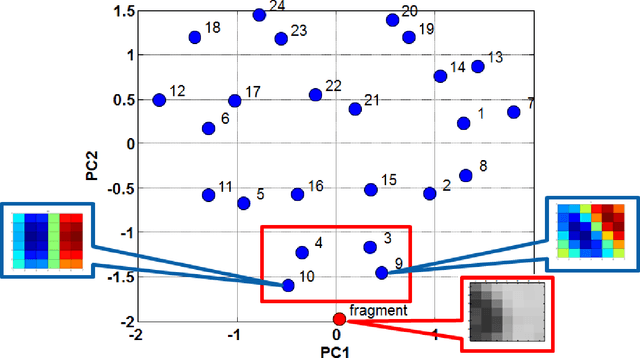
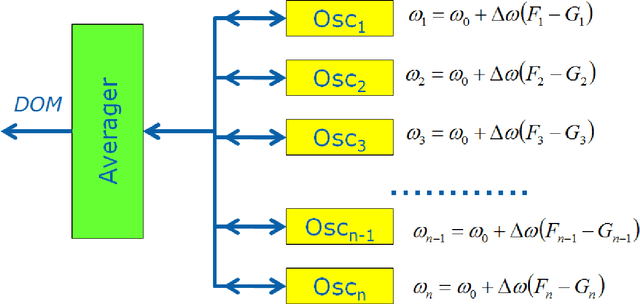
A coupled oscillator array is shown to approximate convolutions with Gabor filters for image processing tasks. Pixelated image fragments and filter functions are converted to voltages, differenced, and input into a corresponding array of weakly coupled Voltage Controlled Oscillators (VCOs). This is referred to as Frequency Shift Keying (FSK). Upon synchronization of the array, the common node amplitude provides a metric for the degree of match between the image fragment and the filter function. The optimal oscillator parameters for synchronization are determined and favor a moderate value of the Q-factor.
ACDC: Weight Sharing in Atom-Coefficient Decomposed Convolution
Sep 04, 2020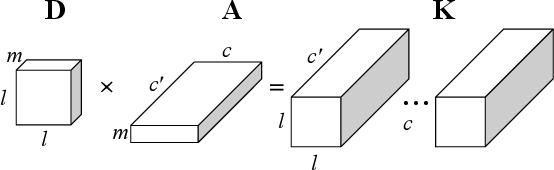
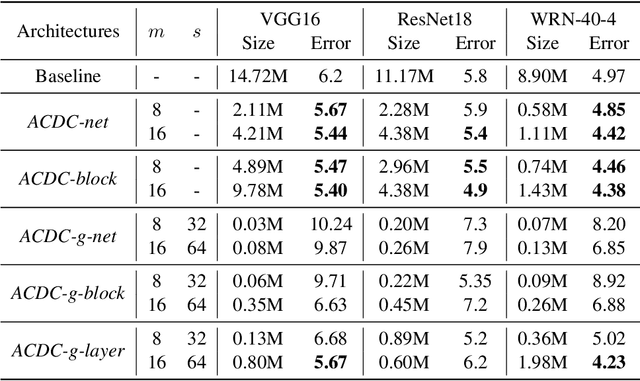
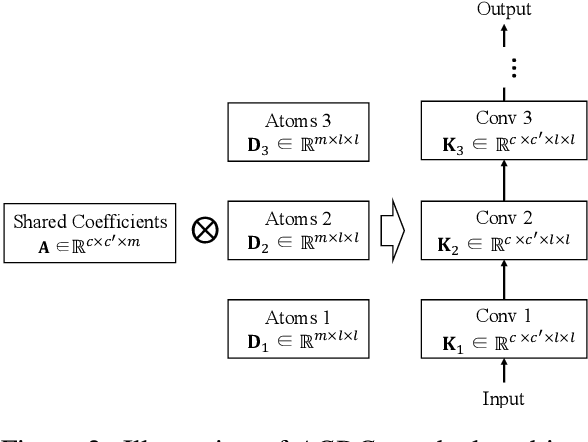
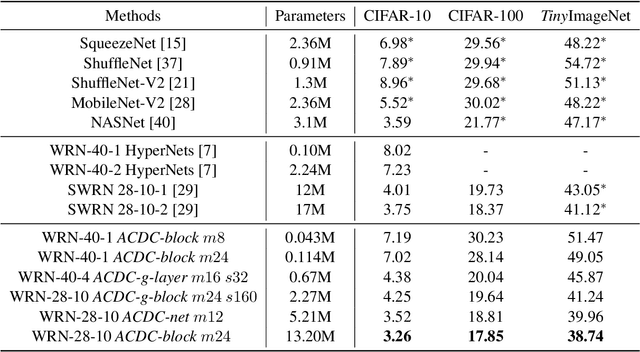
Convolutional Neural Networks (CNNs) are known to be significantly over-parametrized, and difficult to interpret, train and adapt. In this paper, we introduce a structural regularization across convolutional kernels in a CNN. In our approach, each convolution kernel is first decomposed as 2D dictionary atoms linearly combined by coefficients. The widely observed correlation and redundancy in a CNN hint a common low-rank structure among the decomposed coefficients, which is here further supported by our empirical observations. We then explicitly regularize CNN kernels by enforcing decomposed coefficients to be shared across sub-structures, while leaving each sub-structure only its own dictionary atoms, a few hundreds of parameters typically, which leads to dramatic model reductions. We explore models with sharing across different sub-structures to cover a wide range of trade-offs between parameter reduction and expressiveness. Our proposed regularized network structures open the door to better interpreting, training and adapting deep models. We validate the flexibility and compatibility of our method by image classification experiments on multiple datasets and underlying network structures, and show that CNNs now maintain performance with dramatic reduction in parameters and computations, e.g., only 5\% parameters are used in a ResNet-18 to achieve comparable performance. Further experiments on few-shot classification show that faster and more robust task adaptation is obtained in comparison with models with standard convolutions.
Multimodal Remote Sensing Image Registration with Accuracy Estimation at Local and Global Scales
May 25, 2016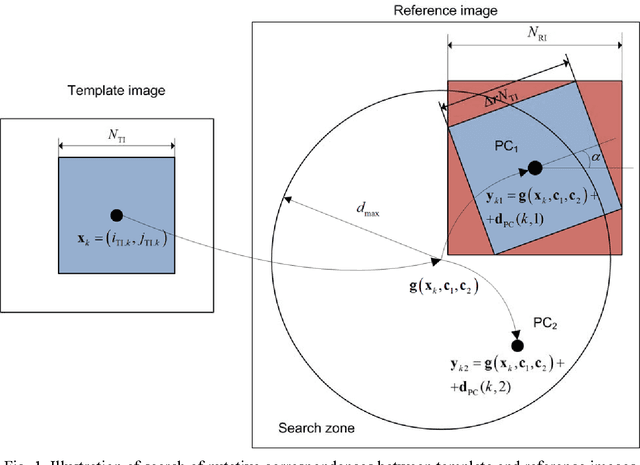
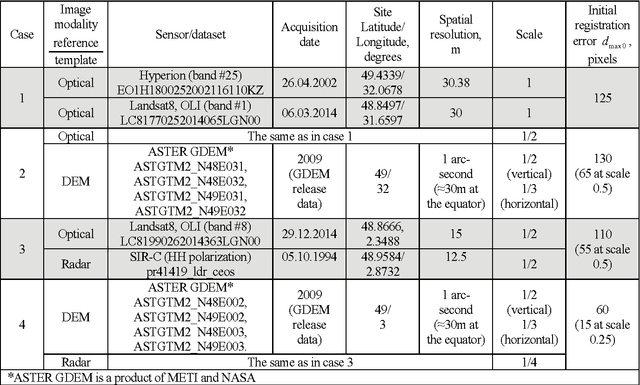
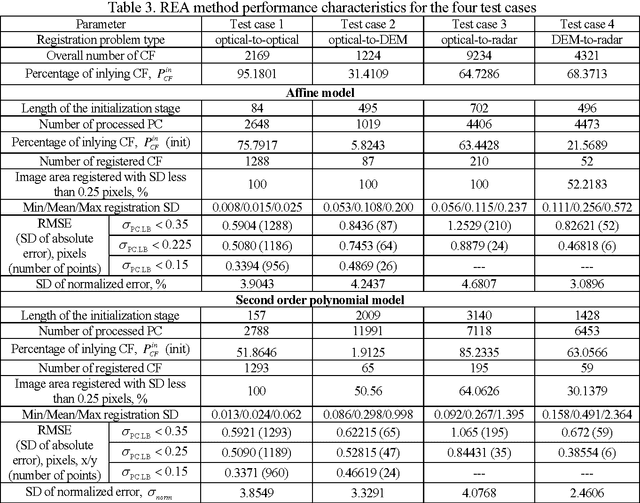

This paper focuses on potential accuracy of remote sensing images registration. We investigate how this accuracy can be estimated without ground truth available and used to improve registration quality of mono- and multi-modal pair of images. At the local scale of image fragments, the Cramer-Rao lower bound (CRLB) on registration error is estimated for each local correspondence between coarsely registered pair of images. This CRLB is defined by local image texture and noise properties. Opposite to the standard approach, where registration accuracy is only evaluated at the output of the registration process, such valuable information is used by us as an additional input knowledge. It greatly helps detecting and discarding outliers and refining the estimation of geometrical transformation model parameters. Based on these ideas, a new area-based registration method called RAE (Registration with Accuracy Estimation) is proposed. In addition to its ability to automatically register very complex multimodal image pairs with high accuracy, the RAE method provides registration accuracy at the global scale as covariance matrix of estimation error of geometrical transformation model parameters or as point-wise registration Standard Deviation. This accuracy does not depend on any ground truth availability and characterizes each pair of registered images individually. Thus, the RAE method can identify image areas for which a predefined registration accuracy is guaranteed. The RAE method is proved successful with reaching subpixel accuracy while registering eight complex mono/multimodal and multitemporal image pairs including optical to optical, optical to radar, optical to Digital Elevation Model (DEM) images and DEM to radar cases. Other methods employed in comparisons fail to provide in a stable manner accurate results on the same test cases.
Retrieving Similar X-Ray Images from Big Image Data Using Radon Barcodes with Single Projections
Jan 02, 2017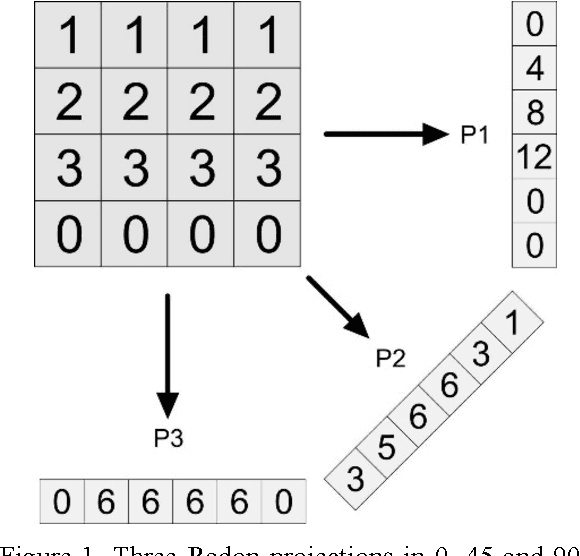
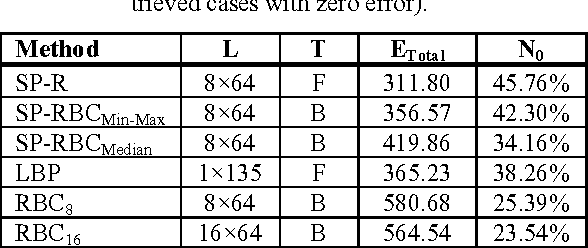
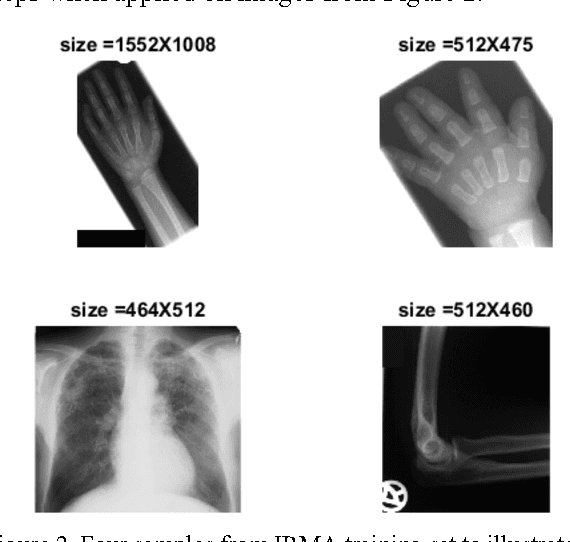

The idea of Radon barcodes (RBC) has been introduced recently. In this paper, we propose a content-based image retrieval approach for big datasets based on Radon barcodes. Our method (Single Projection Radon Barcode, or SP-RBC) uses only a few Radon single projections for each image as global features that can serve as a basis for weak learners. This is our most important contribution in this work, which improves the results of the RBC considerably. As a matter of fact, only one projection of an image, as short as a single SURF feature vector, can already achieve acceptable results. Nevertheless, using multiple projections in a long vector will not deliver anticipated improvements. To exploit the information inherent in each projection, our method uses the outcome of each projection separately and then applies more precise local search on the small subset of retrieved images. We have tested our method using IRMA 2009 dataset a with 14,400 x-ray images as part of imageCLEF initiative. Our approach leads to a substantial decrease in the error rate in comparison with other non-learning methods.
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
Jul 30, 2020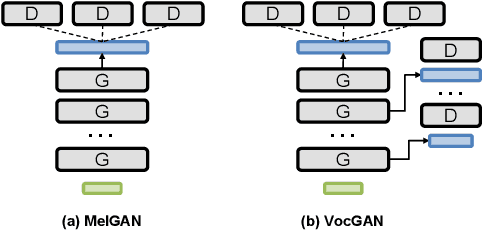
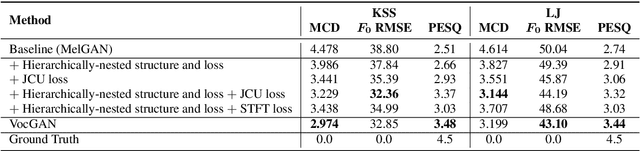
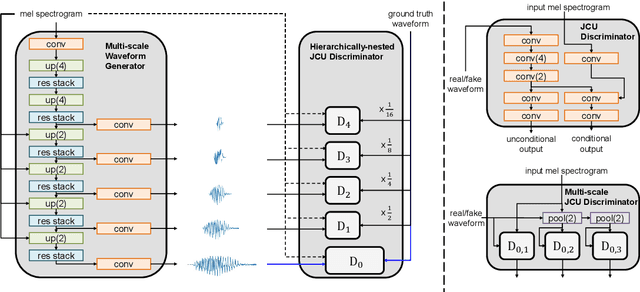
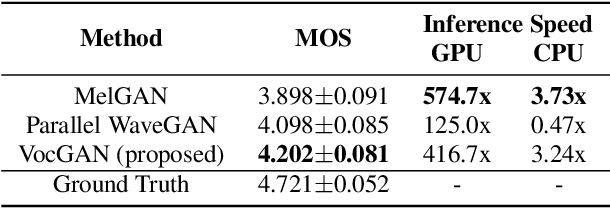
We present a novel high-fidelity real-time neural vocoder called VocGAN. A recently developed GAN-based vocoder, MelGAN, produces speech waveforms in real-time. However, it often produces a waveform that is insufficient in quality or inconsistent with acoustic characteristics of the input mel spectrogram. VocGAN is nearly as fast as MelGAN, but it significantly improves the quality and consistency of the output waveform. VocGAN applies a multi-scale waveform generator and a hierarchically-nested discriminator to learn multiple levels of acoustic properties in a balanced way. It also applies the joint conditional and unconditional objective, which has shown successful results in high-resolution image synthesis. In experiments, VocGAN synthesizes speech waveforms 416.7x faster on a GTX 1080Ti GPU and 3.24x faster on a CPU than real-time. Compared with MelGAN, it also exhibits significantly improved quality in multiple evaluation metrics including mean opinion score (MOS) with minimal additional overhead. Additionally, compared with Parallel WaveGAN, another recently developed high-fidelity vocoder, VocGAN is 6.98x faster on a CPU and exhibits higher MOS.
Deep Convolutional Neural Network for 6-DOF Image Localization
Nov 08, 2016

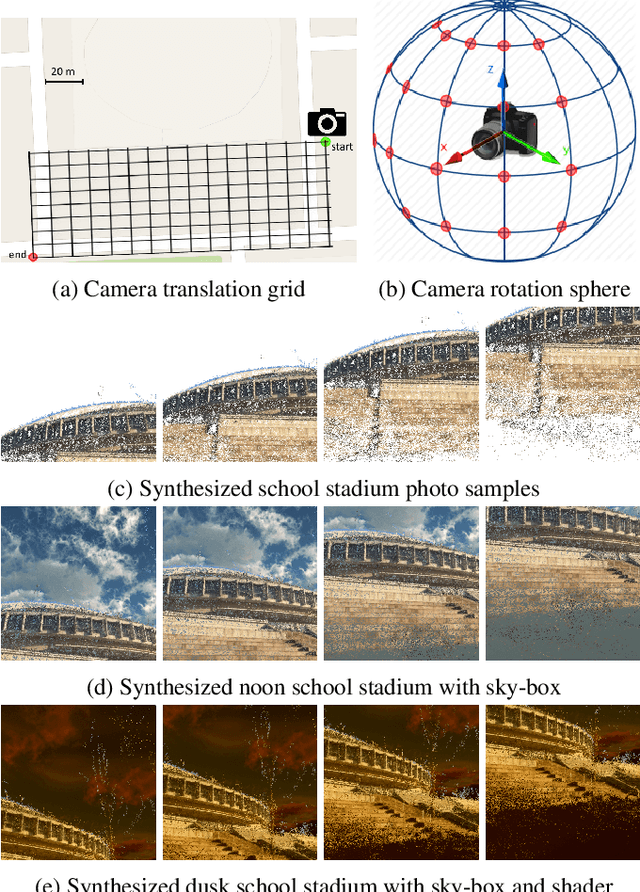

We present an accurate and robust method for six degree of freedom image localization. There are two key-points of our method, 1. automatic immense photo synthesis and labeling from point cloud model and, 2. pose estimation with deep convolutional neural networks regression. Our model can directly regresses 6-DOF camera poses from images, accurately describing where and how it was captured. We achieved an accuracy within 1 meters and 1 degree on our out-door dataset, which covers about 2 acres on our school campus.