 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compressed Sensing with Invertible Generative Models and Dependent Noise
Mar 18, 2020

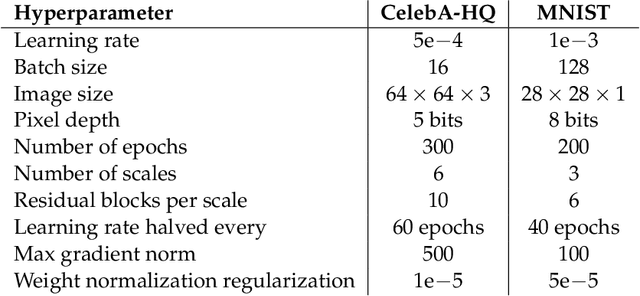
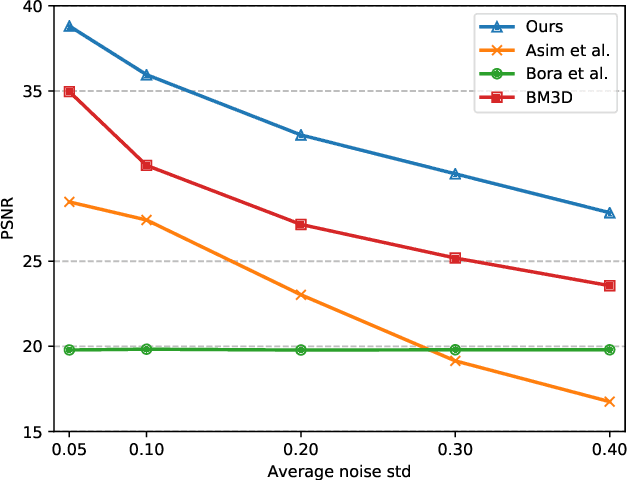
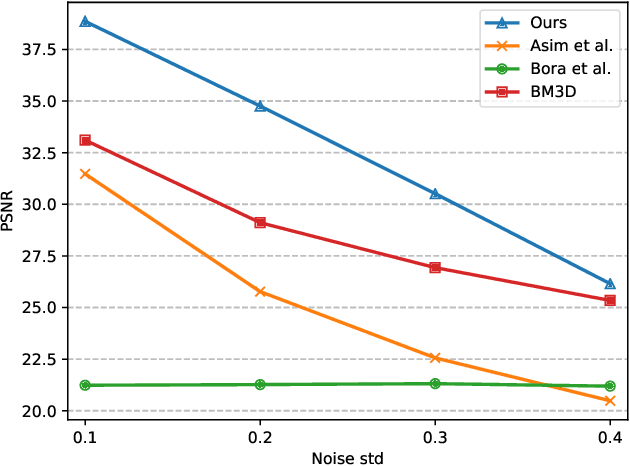
We study image inverse problems with invertible generative priors, specifically normalizing flow models. Our formulation views the solution as the Maximum a Posteriori (MAP) estimate of the image given the measurements. Our general formulation allows for non-linear differentiable forward operators and noise distributions with long-range dependencies. We establish theoretical recovery guarantees for denoising and compressed sensing under our framework. We also empirically validate our method on various inverse problems including compressed sensing with quantized measurements and denoising with dependent noise patterns.
Generating unseen complex scenes: are we there yet?
Dec 07, 2020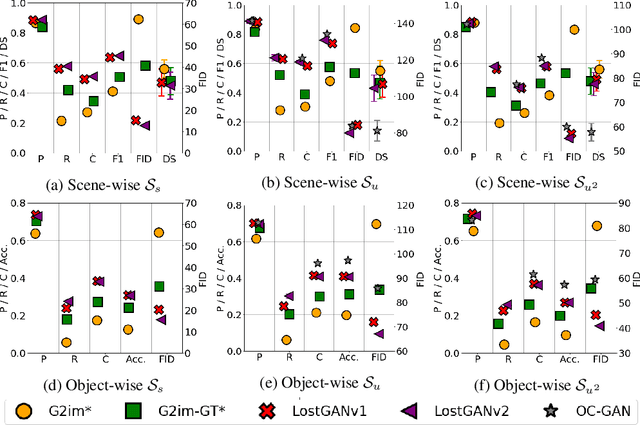
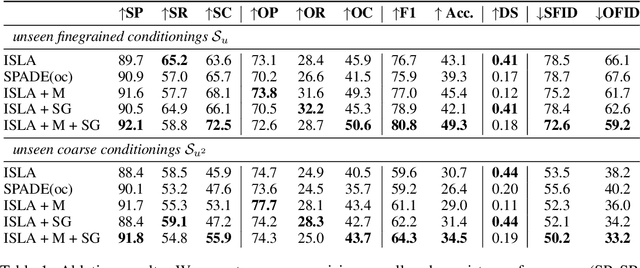
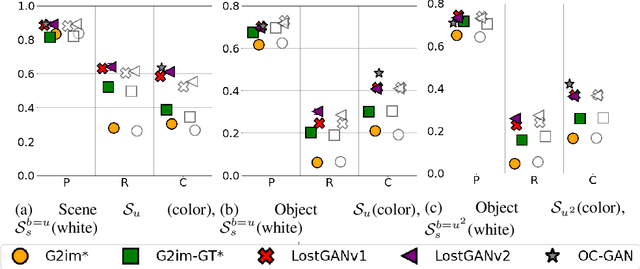
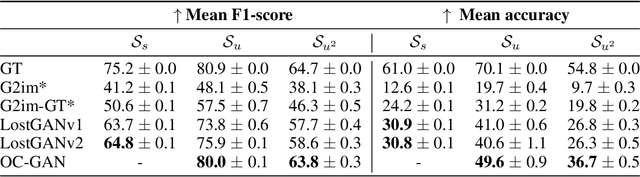
Although recent complex scene conditional generation models generate increasingly appealing scenes, it is very hard to assess which models perform better and why. This is often due to models being trained to fit different data splits, and defining their own experimental setups. In this paper, we propose a methodology to compare complex scene conditional generation models, and provide an in-depth analysis that assesses the ability of each model to (1) fit the training distribution and hence perform well on seen conditionings, (2) to generalize to unseen conditionings composed of seen object combinations, and (3) generalize to unseen conditionings composed of unseen object combinations. As a result, we observe that recent methods are able to generate recognizable scenes given seen conditionings, and exploit compositionality to generalize to unseen conditionings with seen object combinations. However, all methods suffer from noticeable image quality degradation when asked to generate images from conditionings composed of unseen object combinations. Moreover, through our analysis, we identify the advantages of different pipeline components, and find that (1) encouraging compositionality through instance-wise spatial conditioning normalizations increases robustness to both types of unseen conditionings, (2) using semantically aware losses such as the scene-graph perceptual similarity helps improve some dimensions of the generation process, and (3) enhancing the quality of generated masks and the quality of the individual objects are crucial steps to improve robustness to both types of unseen conditionings.
Conditional Generative Refinement Adversarial Networks for Unbalanced Medical Image Semantic Segmentation
Oct 09, 2018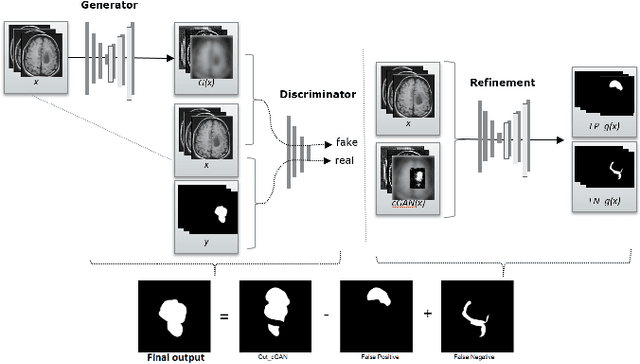
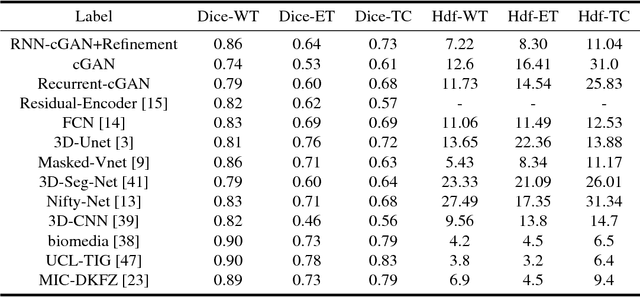

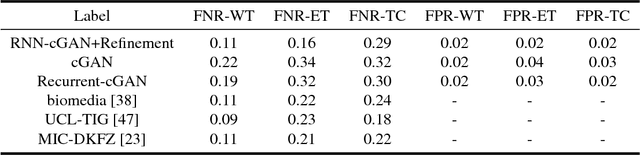
We propose a new generative adversarial architecture to mitigate imbalance data problem in medical image semantic segmentation where the majority of pixels belongs to a healthy region and few belong to lesion or non-health region. A model trained with imbalanced data tends to bias toward healthy data which is not desired in clinical applications and predicted outputs by these networks have high precision and low sensitivity. We propose a new conditional generative refinement network with three components: a generative, a discriminative, and a refinement network to mitigate unbalanced data problem through ensemble learning. The generative network learns to a segment at the pixel level by getting feedback from the discriminative network according to the true positive and true negative maps. On the other hand, the refinement network learns to predict the false positive and the false negative masks produced by the generative network that has significant value, especially in medical application. The final semantic segmentation masks are then composed by the output of the three networks. The proposed architecture shows state-of-the-art results on LiTS-2017 for liver lesion segmentation, and two microscopic cell segmentation datasets MDA231, PhC-HeLa. We have achieved competitive results on BraTS-2017 for brain tumour segmentation.
Bone Structures Extraction and Enhancement in Chest Radiographs via CNN Trained on Synthetic Data
Mar 20, 2020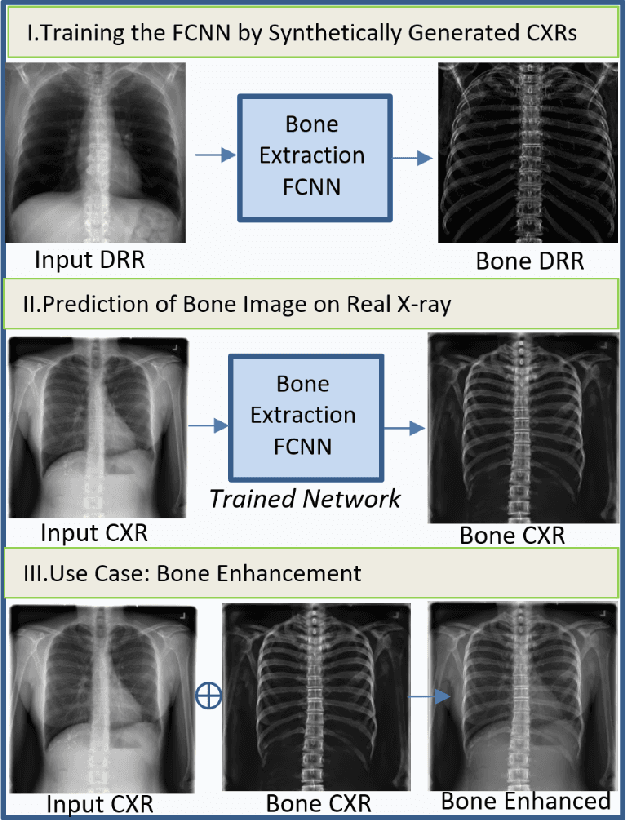

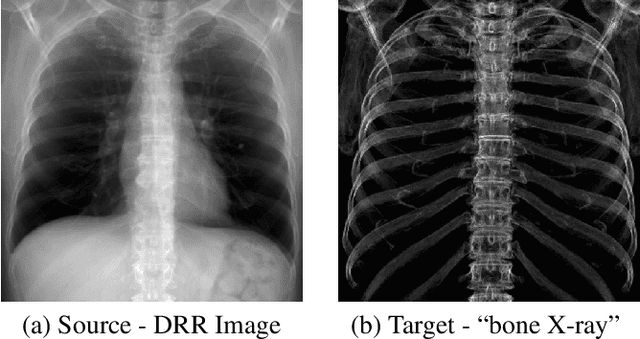
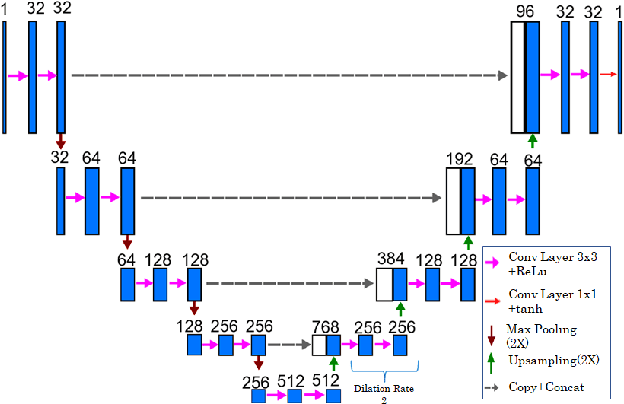
In this paper, we present a deep learning-based image processing technique for extraction of bone structures in chest radiographs using a U-Net FCNN. The U-Net was trained to accomplish the task in a fully supervised setting. To create the training image pairs, we employed simulated X-Ray or Digitally Reconstructed Radiographs (DRR), derived from 664 CT scans belonging to the LIDC-IDRI dataset. Using HU based segmentation of bone structures in the CT domain, a synthetic 2D "Bone x-ray" DRR is produced and used for training the network. For the reconstruction loss, we utilize two loss functions- L1 Loss and perceptual loss. Once the bone structures are extracted, the original image can be enhanced by fusing the original input x-ray and the synthesized "Bone X-ray". We show that our enhancement technique is applicable to real x-ray data, and display our results on the NIH Chest X-Ray-14 dataset.
Immigration Document Classification and Automated Response Generation
Sep 29, 2020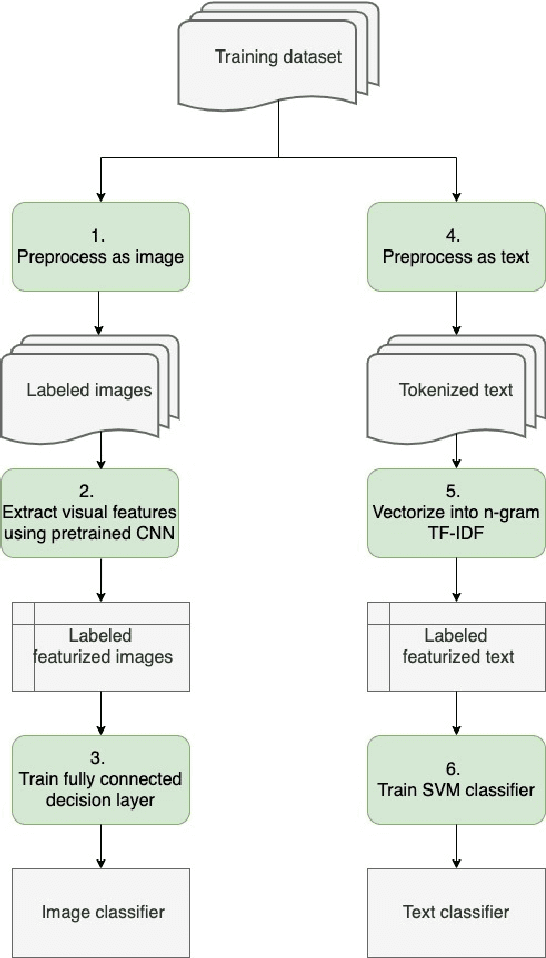
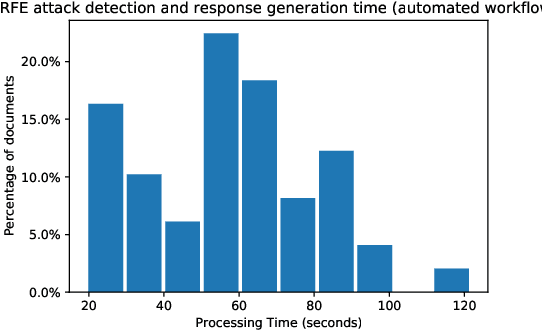
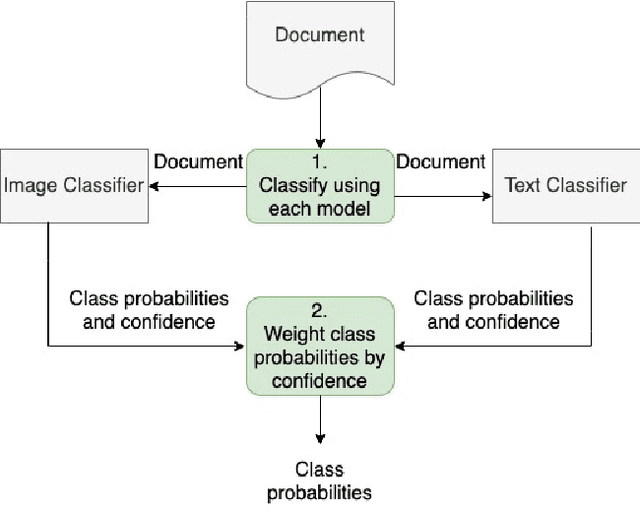
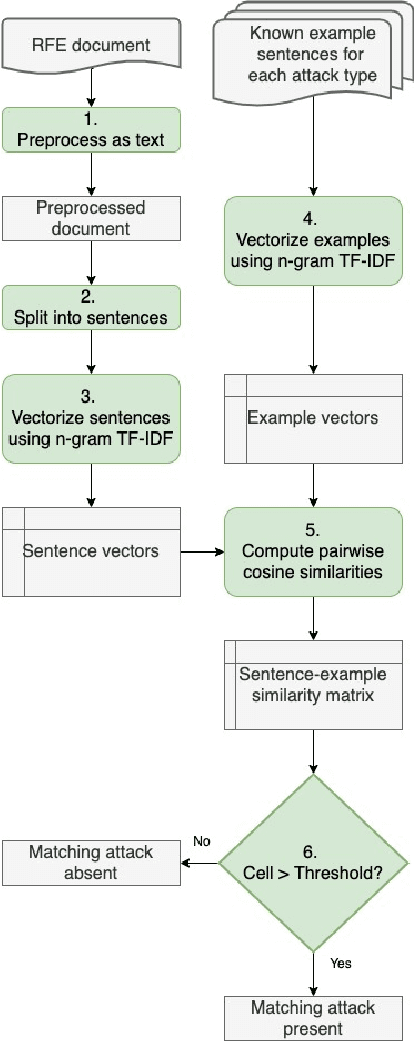
In this paper, we consider the problem of organizing supporting documents vital to U.S. work visa petitions, as well as responding to Requests For Evidence (RFE) issued by the U.S.~Citizenship and Immigration Services (USCIS). Typically, both processes require a significant amount of repetitive manual effort. To reduce the burden of mechanical work, we apply machine learning methods to automate these processes, with humans in the loop to review and edit output for submission. In particular, we use an ensemble of image and text classifiers to categorize supporting documents. We also use a text classifier to automatically identify the types of evidence being requested in an RFE, and used the identified types in conjunction with response templates and extracted fields to assemble draft responses. Empirical results suggest that our approach achieves considerable accuracy while significantly reducing processing time.
Local semi-supervised approach to brain tissue classification in child brain MRI
May 20, 2020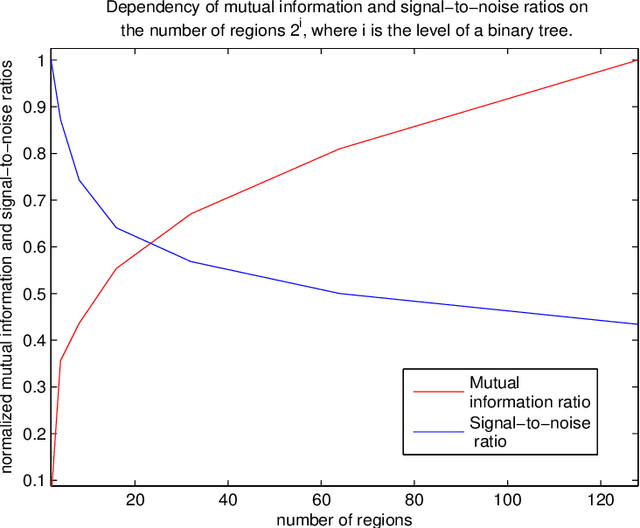
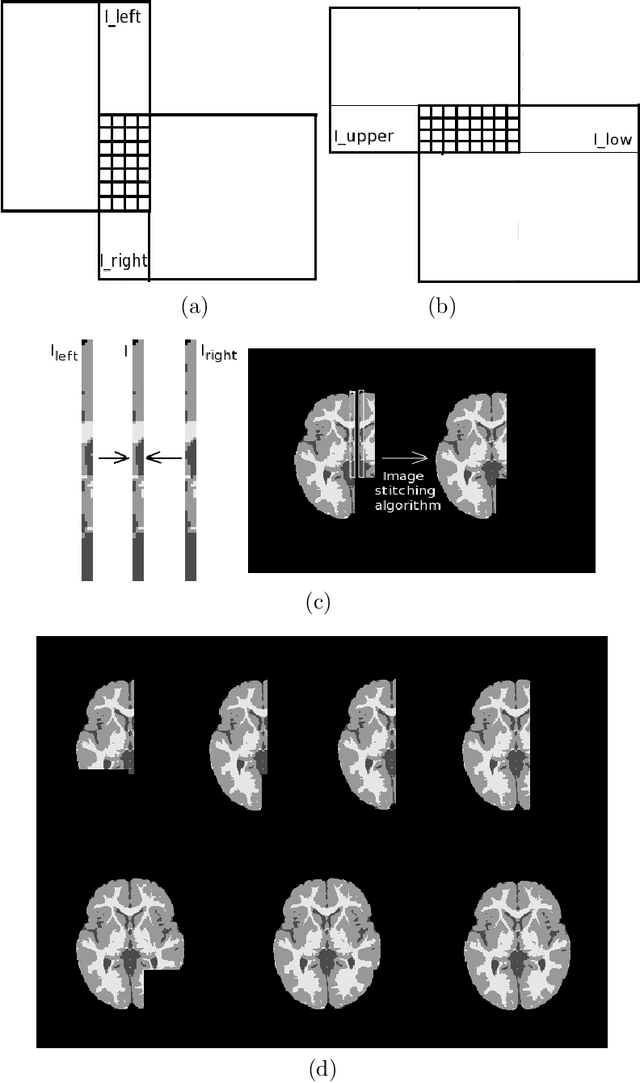
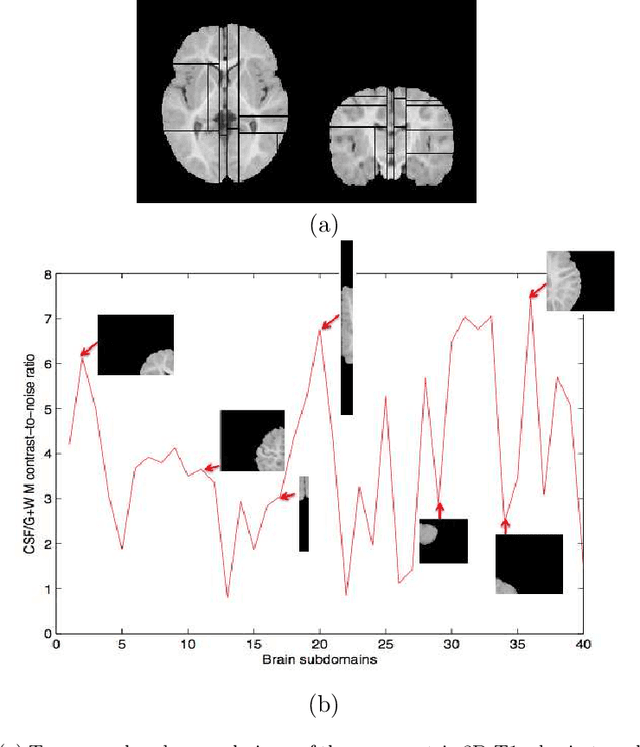

Most segmentation methods in child brain MRI are supervised and are based on global intensity distributions of major brain structures. The successful implementation of a supervised approach depends on availability of an age-appropriate probabilistic brain atlas. For the study of early normal brain development, the construction of such a brain atlas remains a significant challenge. Moreover, using global intensity statistics leads to inaccurate detection of major brain tissue classes due to substantial intensity variations of MR signal within the constituent parts of early developing brain. In order to overcome these methodological limitations we develop a local, semi-supervised framework. It is based on Kernel Fisher Discriminant Analysis (KFDA) for pattern recognition, combined with an objective structural similarity index (SSIM) for perceptual image quality assessment. The proposed method performs optimal brain partitioning into subdomains having different average intensity values followed by SSIM-guided computation of separating surfaces between the constituent brain parts. The classified image subdomains are then stitched slice by slice via simulated annealing to form a global image of the classified brain. In this paper, we consider classification into major tissue classes (white matter and grey matter) and the cerebrospinal fluid and illustrate the proposed framework on examples of brain templates for ages 8 to 11 months and ages 44 to 60 months. We show that our method improves detection of the tissue classes by its comparison to state-of-the-art classification techniques known as Partial Volume Estimation.
Weakly Supervised Segmentation with Multi-scale Adversarial Attention Gates
Jul 02, 2020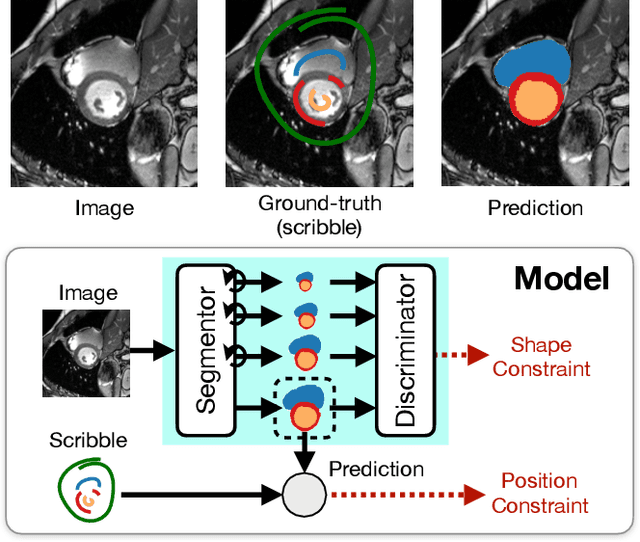



Large, fine-grained image segmentation datasets, annotated at pixel-level, are difficult to obtain, particularly in medical imaging, where annotations also require expert knowledge. Weakly-supervised learning can train models by relying on weaker forms of annotation, such as scribbles. Here, we learn to segment using scribble annotations in an adversarial game. With unpaired segmentation masks, we train a multi-scale GAN to generate realistic segmentation masks at multiple resolutions, while we use scribbles to learn the correct position in the image. Central to the model's success is a novel attention gating mechanism, which we condition with adversarial signals to act as a shape prior, resulting in better object localization at multiple scales. We evaluated our model on several medical (ACDC, LVSC, CHAOS) and non-medical (PPSS) datasets, and we report performance levels matching those achieved by models trained with fully annotated segmentation masks. We also demonstrate extensions in a variety of settings: semi-supervised learning; combining multiple scribble sources (a crowdsourcing scenario) and multi-task learning (combining scribble and mask supervision). We will release expert-made scribble annotations for the ACDC dataset, and the code used for the experiments, at https://gvalvano.github.io/wss-multiscale-adversarial-attention-gates.
CNN Encoder to Reduce the Dimensionality of Data Image for Motion Planning
Apr 10, 2020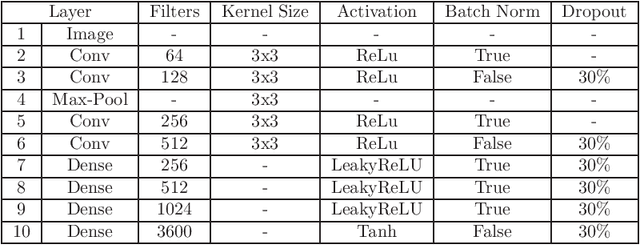
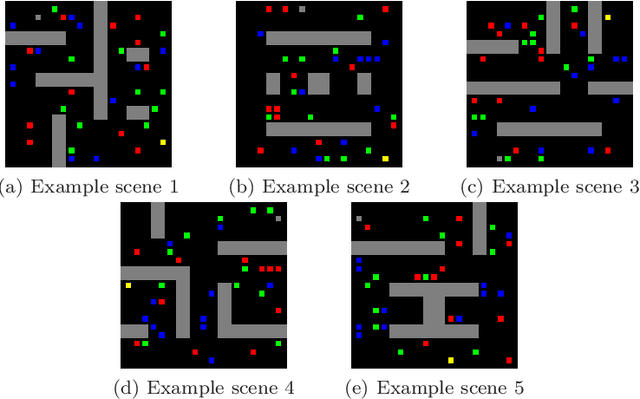
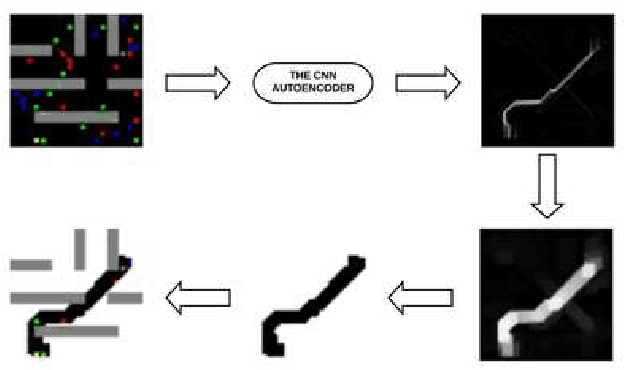
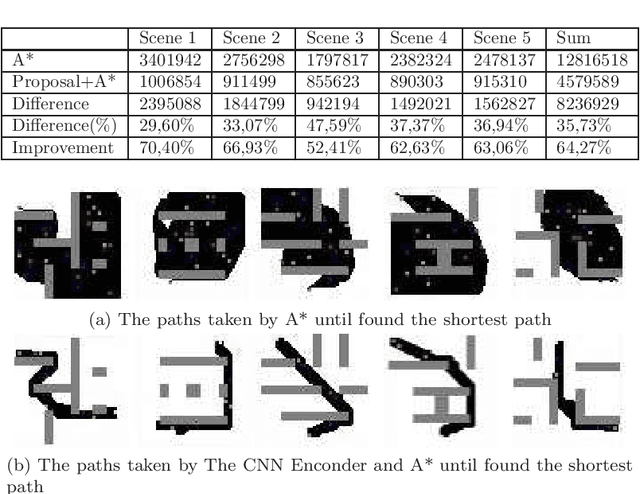
Many real-world applications need path planning algorithms to solve tasks in different areas, such as social applications, autonomous cars, and tracking activities. And most importantly motion planning. Although the use of path planning is sufficient in most motion planning scenarios, they represent potential bottlenecks in large environments with dynamic changes. To tackle this problem, the number of possible routes could be reduced to make it easier for path planning algorithms to find the shortest path with less efforts. An traditional algorithm for path planning is the A*, it uses an heuristic to work faster than other solutions. In this work, we propose a CNN encoder capable of eliminating useless routes for motion planning problems, then we combine the proposed neural network output with A*. To measure the efficiency of our solution, we propose a database with different scenarios of motion planning problems. The evaluated metric is the number of the iterations to find the shortest path. The A* was compared with the CNN Encoder (proposal) with A*. In all evaluated scenarios, our solution reduced the number of iterations by more than 60\%.
Vokenization: Improving Language Understanding with Contextualized, Visual-Grounded Supervision
Oct 14, 2020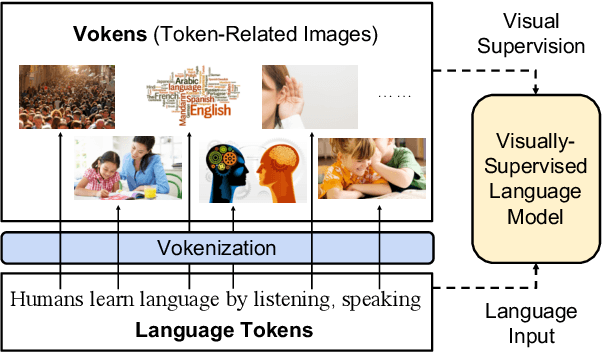
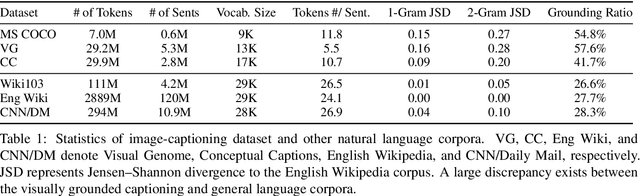
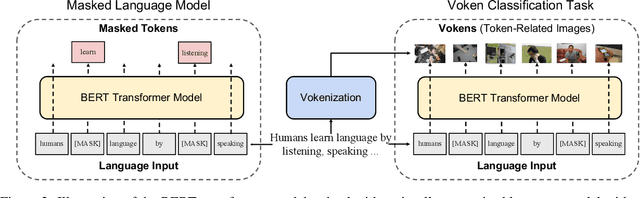
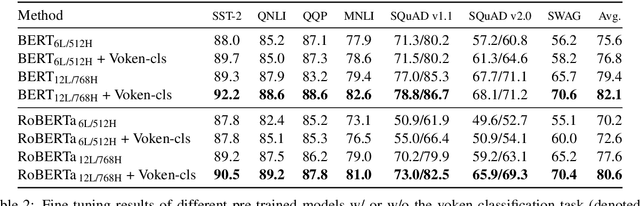
Humans learn language by listening, speaking, writing, reading, and also, via interaction with the multimodal real world. Existing language pre-training frameworks show the effectiveness of text-only self-supervision while we explore the idea of a visually-supervised language model in this paper. We find that the main reason hindering this exploration is the large divergence in magnitude and distributions between the visually-grounded language datasets and pure-language corpora. Therefore, we develop a technique named "vokenization" that extrapolates multimodal alignments to language-only data by contextually mapping language tokens to their related images (which we call "vokens"). The "vokenizer" is trained on relatively small image captioning datasets and we then apply it to generate vokens for large language corpora. Trained with these contextually generated vokens, our visually-supervised language models show consistent improvements over self-supervised alternatives on multiple pure-language tasks such as GLUE, SQuAD, and SWAG. Code and pre-trained models publicly available at https://github.com/airsplay/vokenization
Trustworthy Convolutional Neural Networks: A Gradient Penalized-based Approach
Sep 29, 2020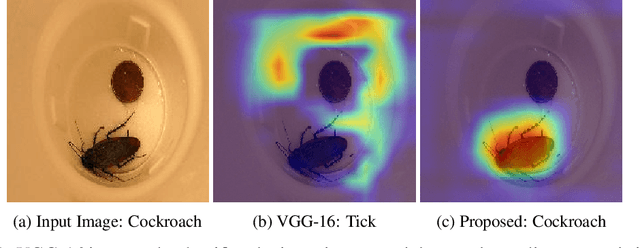
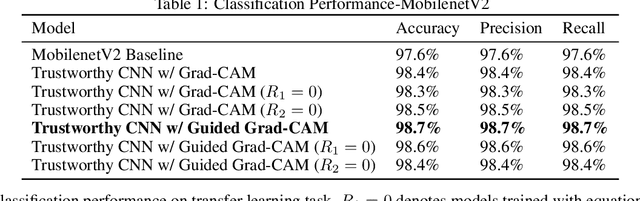
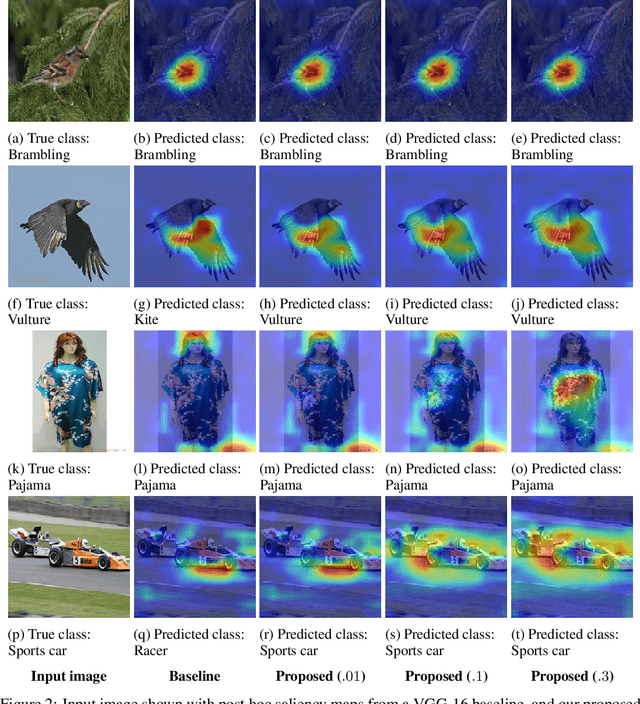
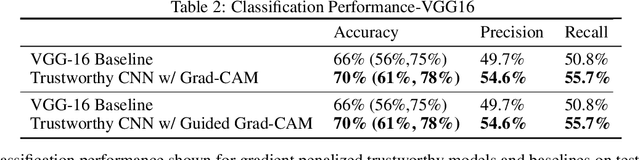
Convolutional neural networks (CNNs) are commonly used for image classification. Saliency methods are examples of approaches that can be used to interpret CNNs post hoc, identifying the most relevant pixels for a prediction following the gradients flow. Even though CNNs can correctly classify images, the underlying saliency maps could be erroneous in many cases. This can result in skepticism as to the validity of the model or its interpretation. We propose a novel approach for training trustworthy CNNs by penalizing parameter choices that result in inaccurate saliency maps generated during training. We add a penalty term for inaccurate saliency maps produced when the predicted label is correct, a penalty term for accurate saliency maps produced when the predicted label is incorrect, and a regularization term penalizing overly confident saliency maps. Experiments show increased classification performance, user engagement, and trust.