 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVietnamese Machine Reading Comprehension
Papers and Code
ViQA-COVID: COVID-19 Machine Reading Comprehension Dataset for Vietnamese
Apr 21, 2025After two years of appearance, COVID-19 has negatively affected people and normal life around the world. As in May 2022, there are more than 522 million cases and six million deaths worldwide (including nearly ten million cases and over forty-three thousand deaths in Vietnam). Economy and society are both severely affected. The variant of COVID-19, Omicron, has broken disease prevention measures of countries and rapidly increased number of infections. Resources overloading in treatment and epidemics prevention is happening all over the world. It can be seen that, application of artificial intelligence (AI) to support people at this time is extremely necessary. There have been many studies applying AI to prevent COVID-19 which are extremely useful, and studies on machine reading comprehension (MRC) are also in it. Realizing that, we created the first MRC dataset about COVID-19 for Vietnamese: ViQA-COVID and can be used to build models and systems, contributing to disease prevention. Besides, ViQA-COVID is also the first multi-span extraction MRC dataset for Vietnamese, we hope that it can contribute to promoting MRC studies in Vietnamese and multilingual.
VlogQA: Task, Dataset, and Baseline Models for Vietnamese Spoken-Based Machine Reading Comprehension
Feb 05, 2024



This paper presents the development process of a Vietnamese spoken language corpus for machine reading comprehension (MRC) tasks and provides insights into the challenges and opportunities associated with using real-world data for machine reading comprehension tasks. The existing MRC corpora in Vietnamese mainly focus on formal written documents such as Wikipedia articles, online newspapers, or textbooks. In contrast, the VlogQA consists of 10,076 question-answer pairs based on 1,230 transcript documents sourced from YouTube -- an extensive source of user-uploaded content, covering the topics of food and travel. By capturing the spoken language of native Vietnamese speakers in natural settings, an obscure corner overlooked in Vietnamese research, the corpus provides a valuable resource for future research in reading comprehension tasks for the Vietnamese language. Regarding performance evaluation, our deep-learning models achieved the highest F1 score of 75.34% on the test set, indicating significant progress in machine reading comprehension for Vietnamese spoken language data. In terms of EM, the highest score we accomplished is 53.97%, which reflects the challenge in processing spoken-based content and highlights the need for further improvement.
ViTextVQA: A Large-Scale Visual Question Answering Dataset for Evaluating Vietnamese Text Comprehension in Images
Apr 16, 2024



Visual Question Answering (VQA) is a complicated task that requires the capability of simultaneously processing natural language and images. Initially, this task was researched, focusing on methods to help machines understand objects and scene contexts in images. However, some text appearing in the image that carries explicit information about the full content of the image is not mentioned. Along with the continuous development of the AI era, there have been many studies on the reading comprehension ability of VQA models in the world. As a developing country, conditions are still limited, and this task is still open in Vietnam. Therefore, we introduce the first large-scale dataset in Vietnamese specializing in the ability to understand text appearing in images, we call it ViTextVQA (\textbf{Vi}etnamese \textbf{Text}-based \textbf{V}isual \textbf{Q}uestion \textbf{A}nswering dataset) which contains \textbf{over 16,000} images and \textbf{over 50,000} questions with answers. Through meticulous experiments with various state-of-the-art models, we uncover the significance of the order in which tokens in OCR text are processed and selected to formulate answers. This finding helped us significantly improve the performance of the baseline models on the ViTextVQA dataset. Our dataset is available at this \href{https://github.com/minhquan6203/ViTextVQA-Dataset}{link} for research purposes.
Revealing Weaknesses of Vietnamese Language Models Through Unanswerable Questions in Machine Reading Comprehension
Mar 16, 2023



Although the curse of multilinguality significantly restricts the language abilities of multilingual models in monolingual settings, researchers now still have to rely on multilingual models to develop state-of-the-art systems in Vietnamese Machine Reading Comprehension. This difficulty in researching is because of the limited number of high-quality works in developing Vietnamese language models. In order to encourage more work in this research field, we present a comprehensive analysis of language weaknesses and strengths of current Vietnamese monolingual models using the downstream task of Machine Reading Comprehension. From the analysis results, we suggest new directions for developing Vietnamese language models. Besides this main contribution, we also successfully reveal the existence of artifacts in Vietnamese Machine Reading Comprehension benchmarks and suggest an urgent need for new high-quality benchmarks to track the progress of Vietnamese Machine Reading Comprehension. Moreover, we also introduced a minor but valuable modification to the process of annotating unanswerable questions for Machine Reading Comprehension from previous work. Our proposed modification helps improve the quality of unanswerable questions to a higher level of difficulty for Machine Reading Comprehension systems to solve.
Integrating Semantic Information into Sketchy Reading Module of Retro-Reader for Vietnamese Machine Reading Comprehension
Jan 01, 2023



Machine Reading Comprehension has become one of the most advanced and popular research topics in the fields of Natural Language Processing in recent years. The classification of answerability questions is a relatively significant sub-task in machine reading comprehension; however, there haven't been many studies. Retro-Reader is one of the studies that has solved this problem effectively. However, the encoders of most traditional machine reading comprehension models in general and Retro-Reader, in particular, have not been able to exploit the contextual semantic information of the context completely. Inspired by SemBERT, we use semantic role labels from the SRL task to add semantics to pre-trained language models such as mBERT, XLM-R, PhoBERT. This experiment was conducted to compare the influence of semantics on the classification of answerability for the Vietnamese machine reading comprehension. Additionally, we hope this experiment will enhance the encoder for the Retro-Reader model's Sketchy Reading Module. The improved Retro-Reader model's encoder with semantics was first applied to the Vietnamese Machine Reading Comprehension task and obtained positive results.
A Multiple Choices Reading Comprehension Corpus for Vietnamese Language Education
Mar 31, 2023



Machine reading comprehension has been an interesting and challenging task in recent years, with the purpose of extracting useful information from texts. To attain the computer ability to understand the reading text and answer relevant information, we introduce ViMMRC 2.0 - an extension of the previous ViMMRC for the task of multiple-choice reading comprehension in Vietnamese Textbooks which contain the reading articles for students from Grade 1 to Grade 12. This dataset has 699 reading passages which are prose and poems, and 5,273 questions. The questions in the new dataset are not fixed with four options as in the previous version. Moreover, the difficulty of questions is increased, which challenges the models to find the correct choice. The computer must understand the whole context of the reading passage, the question, and the content of each choice to extract the right answers. Hence, we propose the multi-stage approach that combines the multi-step attention network (MAN) with the natural language inference (NLI) task to enhance the performance of the reading comprehension model. Then, we compare the proposed methodology with the baseline BERTology models on the new dataset and the ViMMRC 1.0. Our multi-stage models achieved 58.81% by Accuracy on the test set, which is 5.34% better than the highest BERTology models. From the results of the error analysis, we found the challenge of the reading comprehension models is understanding the implicit context in texts and linking them together in order to find the correct answers. Finally, we hope our new dataset will motivate further research in enhancing the language understanding ability of computers in the Vietnamese language.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022
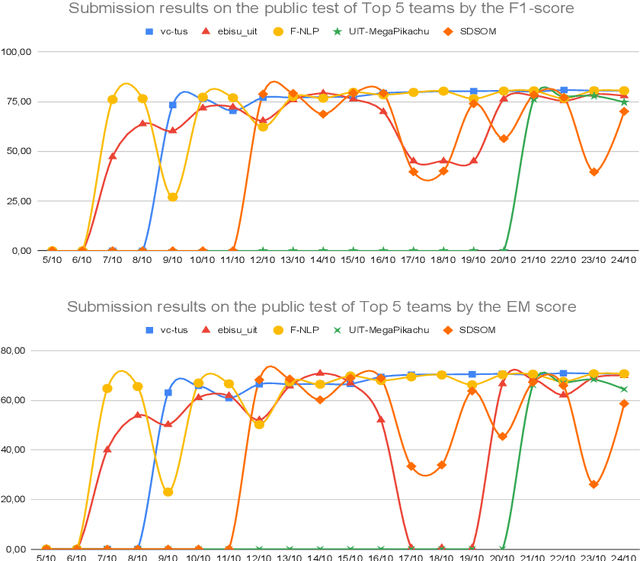

One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
Conversational Machine Reading Comprehension for Vietnamese Healthcare Texts
May 21, 2021
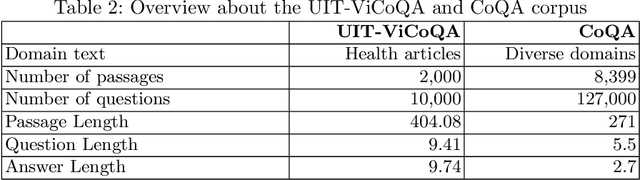
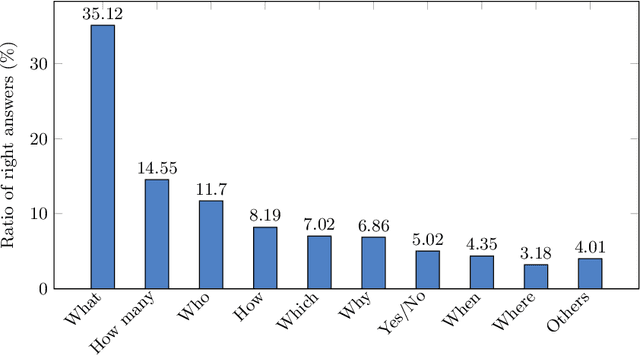

Machine reading comprehension (MRC) is a sub-field in natural language processing that aims to help computers understand unstructured texts and then answer questions related to them. In practice, conversation is an essential way to communicate and transfer information. To help machines understand conversation texts, we present UIT-ViCoQA - a new corpus for conversational machine reading comprehension in the Vietnamese language. This corpus consists of 10,000 questions with answers to over 2,000 conversations about health news articles. Then, we evaluate several baseline approaches for conversational machine comprehension on the UIT-ViCoQA corpus. The best model obtains an F1 score of 45.27%, which is 30.91 points behind human performance (76.18%), indicating that there is ample room for improvement.
Sentence Extraction-Based Machine Reading Comprehension for Vietnamese
Jun 11, 2021
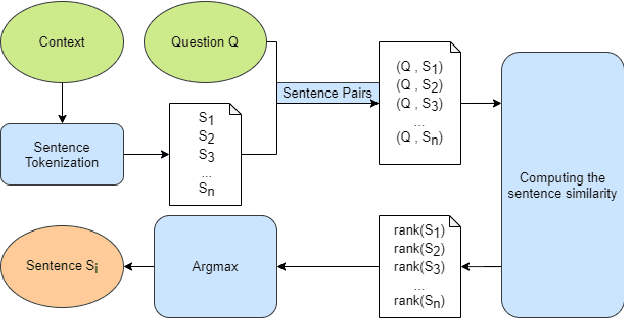
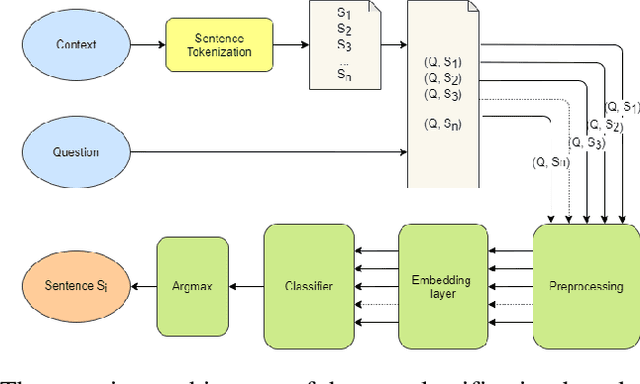
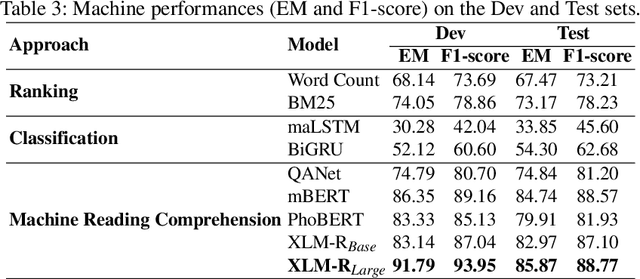
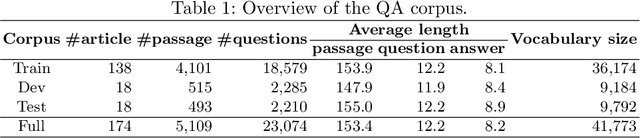
The development of natural language processing (NLP) in general and machine reading comprehension in particular has attracted the great attention of the research community. In recent years, there are a few datasets for machine reading comprehension tasks in Vietnamese with large sizes, such as UIT-ViQuAD and UIT-ViNewsQA. However, the datasets are not diverse in answers to serve the research. In this paper, we introduce UIT-ViWikiQA, the first dataset for evaluating sentence extraction-based machine reading comprehension in the Vietnamese language. The UIT-ViWikiQA dataset is converted from the UIT-ViQuAD dataset, consisting of comprises 23.074 question-answers based on 5.109 passages of 174 Wikipedia Vietnamese articles. We propose a conversion algorithm to create the dataset for sentence extraction-based machine reading comprehension and three types of approaches for sentence extraction-based machine reading comprehension in Vietnamese. Our experiments show that the best machine model is XLM-R_Large, which achieves an exact match (EM) of 85.97% and an F1-score of 88.77% on our dataset. Besides, we analyze experimental results in terms of the question type in Vietnamese and the effect of context on the performance of the MRC models, thereby showing the challenges from the UIT-ViWikiQA dataset that we propose to the language processing community.
XLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022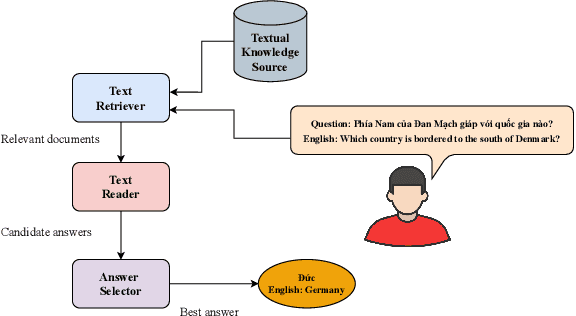
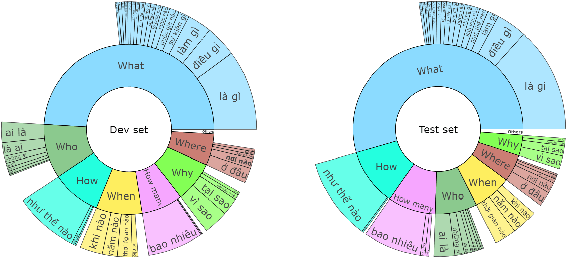
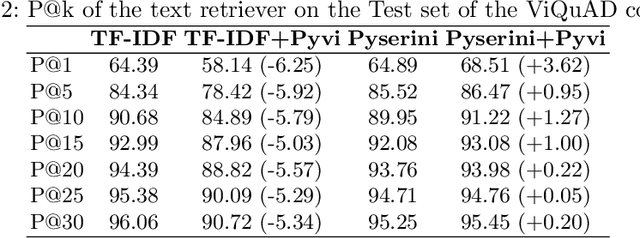
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.