 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Spam Reviews on Vietnamese E-commerce Websites
Jul 27, 2022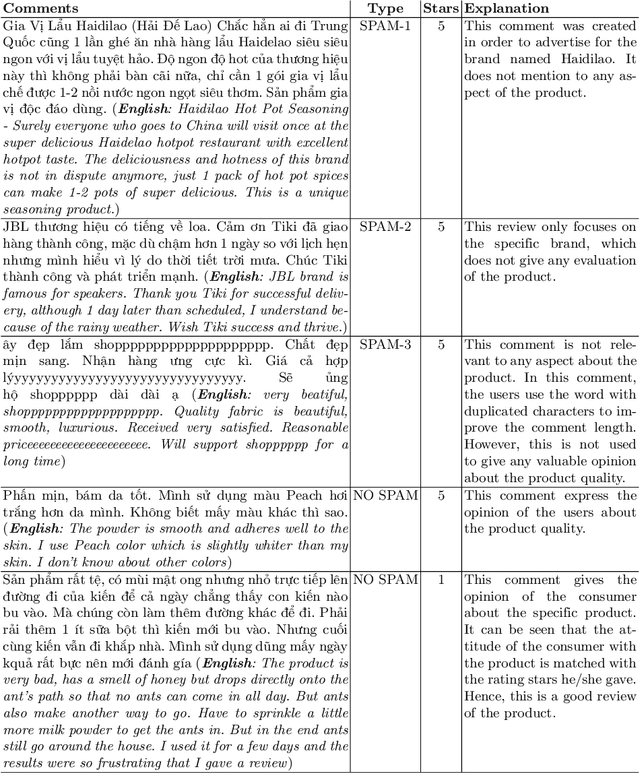
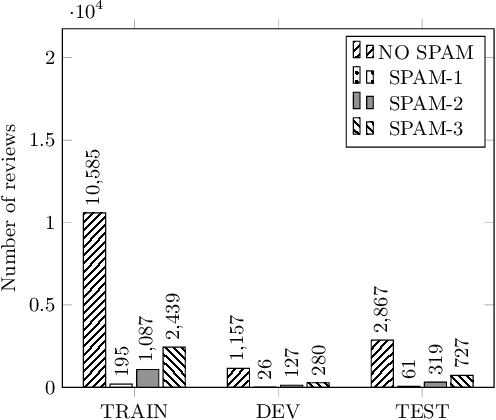

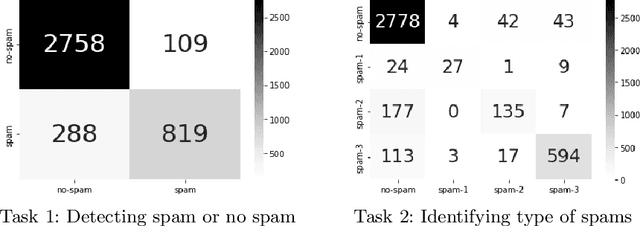
The reviews of customers play an essential role in online shopping. People often refer to reviews or comments of previous customers to decide whether to buy a new product. Catching up with this behavior, some people create untruths and illegitimate reviews to hoax customers about the fake quality of products. These reviews are called spam reviews, which confuse consumers on online shopping platforms and negatively affect online shopping behaviors. We propose the dataset called ViSpamReviews, which has a strict annotation procedure for detecting spam reviews on e-commerce platforms. Our dataset consists of two tasks: the binary classification task for detecting whether a review is a spam or not and the multi-class classification task for identifying the type of spam. The PhoBERT obtained the highest results on both tasks, 88.93% and 72.17%, respectively, by macro average F1 score.
XLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022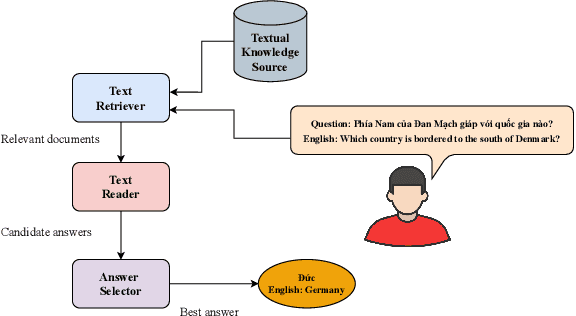
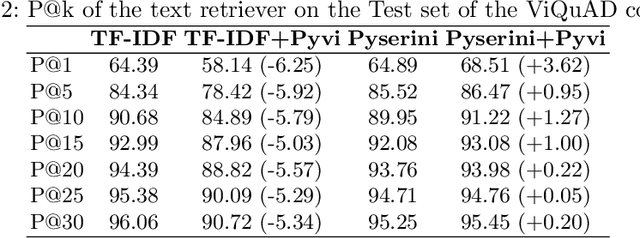
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.
Monolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization
Aug 31, 2021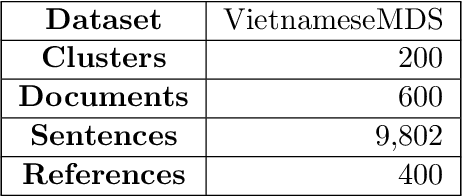
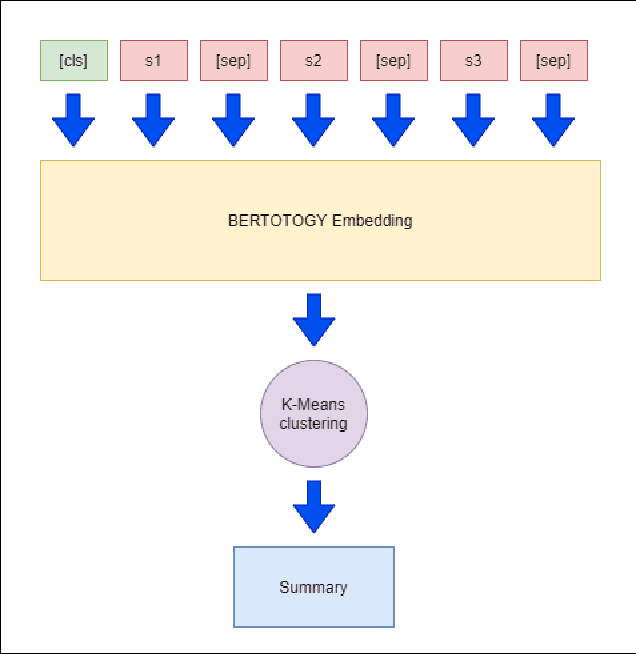
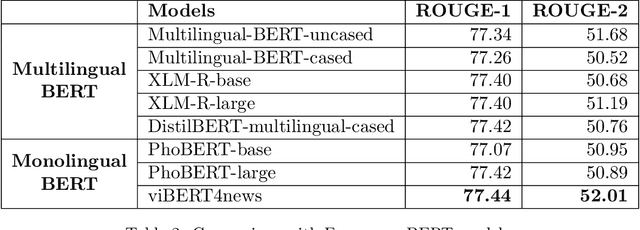
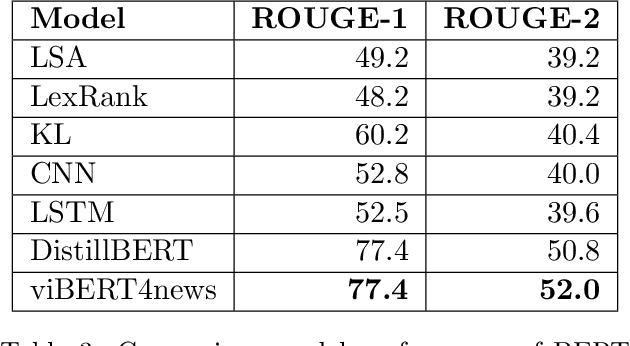
Recent researches have demonstrated that BERT shows potential in a wide range of natural language processing tasks. It is adopted as an encoder for many state-of-the-art automatic summarizing systems, which achieve excellent performance. However, so far, there is not much work done for Vietnamese. In this paper, we showcase how BERT can be implemented for extractive text summarization in Vietnamese. We introduce a novel comparison between different multilingual and monolingual BERT models. The experiment results indicate that monolingual models produce promising results compared to other multilingual models and previous text summarizing models for Vietnamese.
Sentence Extraction-Based Machine Reading Comprehension for Vietnamese
Jun 11, 2021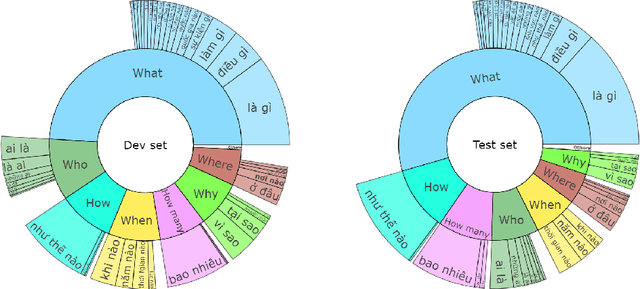
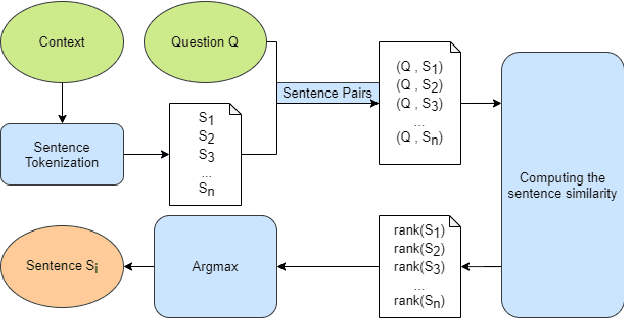
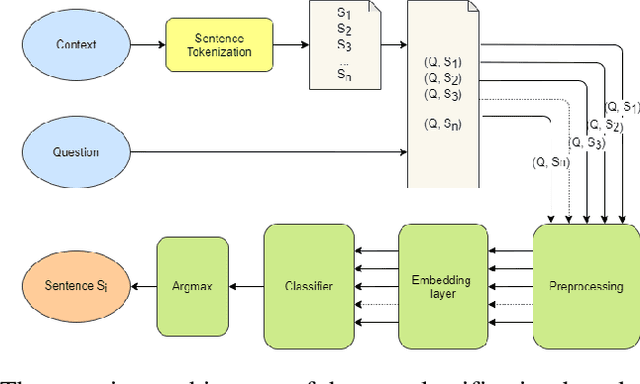
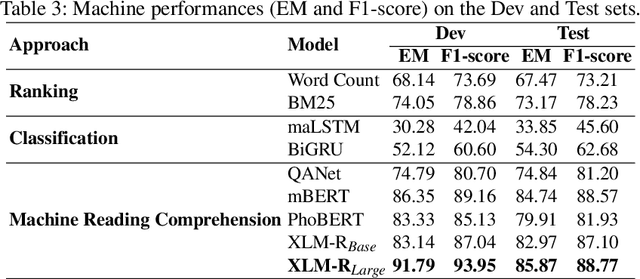
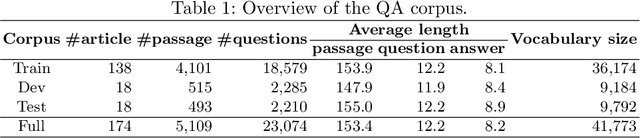
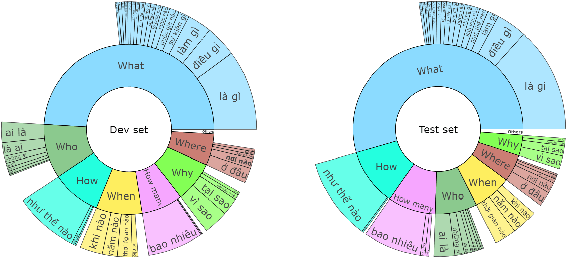
The development of natural language processing (NLP) in general and machine reading comprehension in particular has attracted the great attention of the research community. In recent years, there are a few datasets for machine reading comprehension tasks in Vietnamese with large sizes, such as UIT-ViQuAD and UIT-ViNewsQA. However, the datasets are not diverse in answers to serve the research. In this paper, we introduce UIT-ViWikiQA, the first dataset for evaluating sentence extraction-based machine reading comprehension in the Vietnamese language. The UIT-ViWikiQA dataset is converted from the UIT-ViQuAD dataset, consisting of comprises 23.074 question-answers based on 5.109 passages of 174 Wikipedia Vietnamese articles. We propose a conversion algorithm to create the dataset for sentence extraction-based machine reading comprehension and three types of approaches for sentence extraction-based machine reading comprehension in Vietnamese. Our experiments show that the best machine model is XLM-R_Large, which achieves an exact match (EM) of 85.97% and an F1-score of 88.77% on our dataset. Besides, we analyze experimental results in terms of the question type in Vietnamese and the effect of context on the performance of the MRC models, thereby showing the challenges from the UIT-ViWikiQA dataset that we propose to the language processing community.
Gender Prediction Based on Vietnamese Names with Machine Learning Techniques
Oct 27, 2020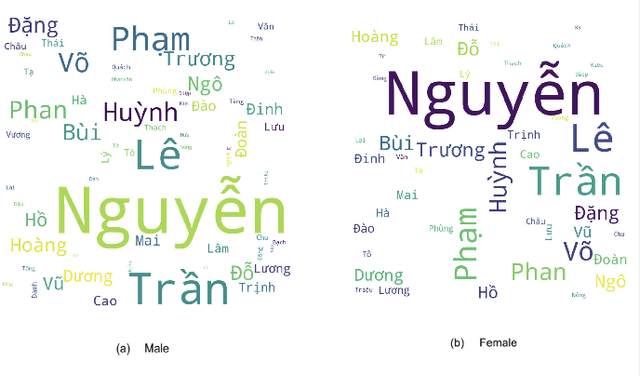

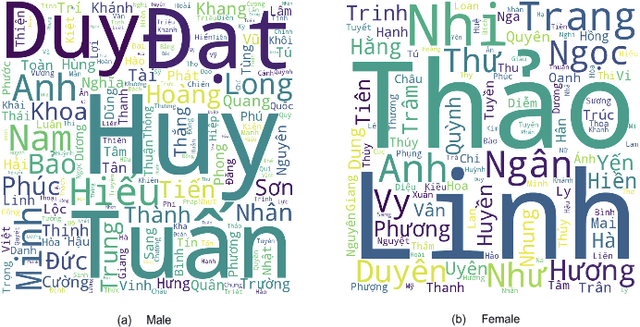
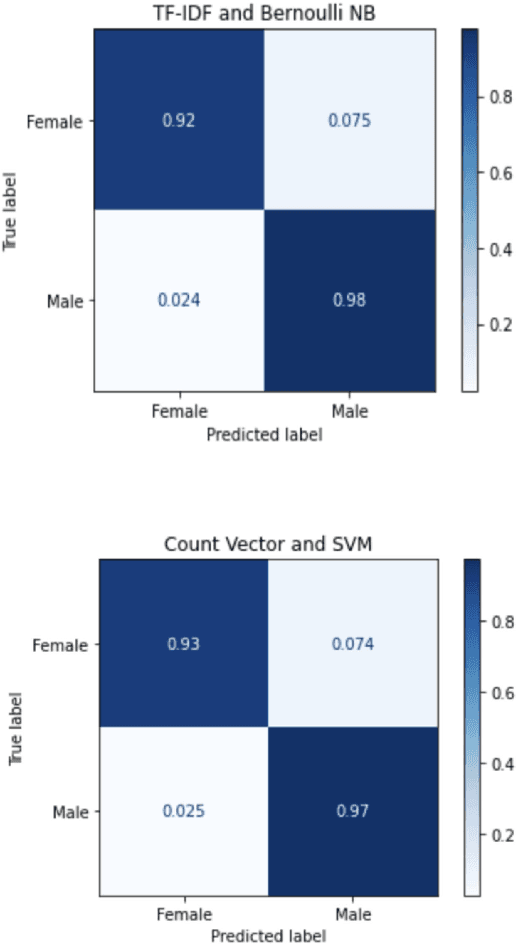
As biological gender is one of the aspects of presenting individual human, much work has been done on gender classification based on people names. The proposals for English and Chinese languages are tremendous; still, there have been few works done for Vietnamese so far. We propose a new dataset for gender prediction based on Vietnamese names. This dataset comprises over 26,000 full names annotated with genders. This dataset is available on our website for research purposes. In addition, this paper describes six machine learning algorithms (Support Vector Machine, Multinomial Naive Bayes, Bernoulli Naive Bayes, Decision Tree, Random Forrest and Logistic Regression) and a deep learning model (LSTM) with fastText word embedding for gender prediction on Vietnamese names. We create a dataset and investigate the impact of each name component on detecting gender. As a result, the best F1-score that we have achieved is up to 96\% on LSTM model and we generate a web API based on our trained model.
A Vietnamese Dataset for Evaluating Machine Reading Comprehension
Oct 02, 2020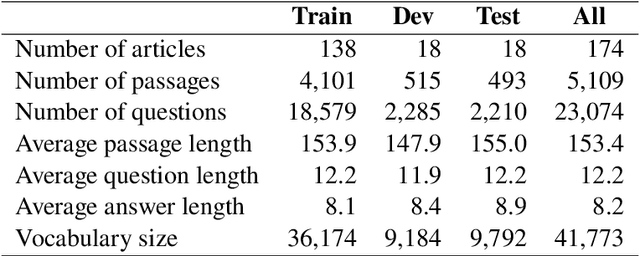
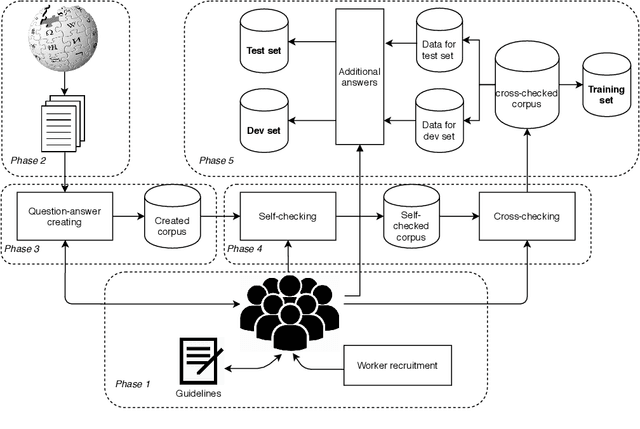
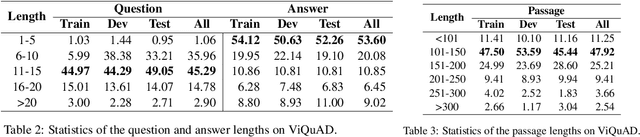
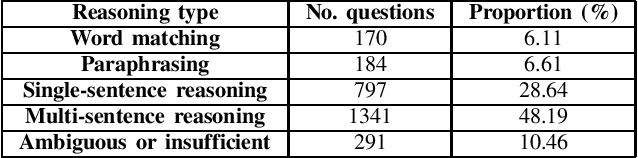
Over 97 million inhabitants speak Vietnamese as the native language in the world. However, there are few research studies on machine reading comprehension (MRC) in Vietnamese, the task of understanding a document or text, and answering questions related to it. Due to the lack of benchmark datasets for Vietnamese, we present the Vietnamese Question Answering Dataset (ViQuAD), a new dataset for the low-resource language as Vietnamese to evaluate MRC models. This dataset comprises over 23,000 human-generated question-answer pairs based on 5,109 passages of 174 Vietnamese articles from Wikipedia. In particular, we propose a new process of dataset creation for Vietnamese MRC. Our in-depth analyses illustrate that our dataset requires abilities beyond simple reasoning like word matching and demands complicate reasoning such as single-sentence and multiple-sentence inferences. Besides, we conduct experiments on state-of-the-art MRC methods in English and Chinese as the first experimental models on ViQuAD, which will be compared to further models. We also estimate human performances on the dataset and compare it to the experimental results of several powerful machine models. As a result, the substantial differences between humans and the best model performances on the dataset indicate that improvements can be explored on ViQuAD through future research. Our dataset is freely available to encourage the research community to overcome challenges in Vietnamese MRC.
An Experimental Study of Deep Neural Network Models for Vietnamese Multiple-Choice Reading Comprehension
Aug 20, 2020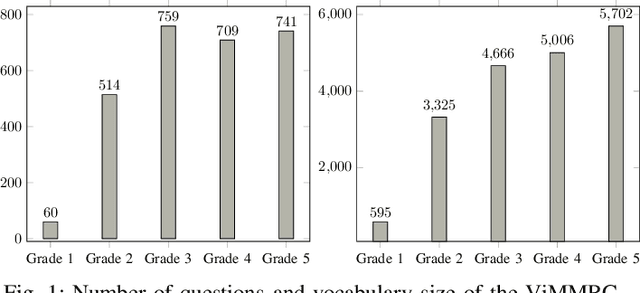
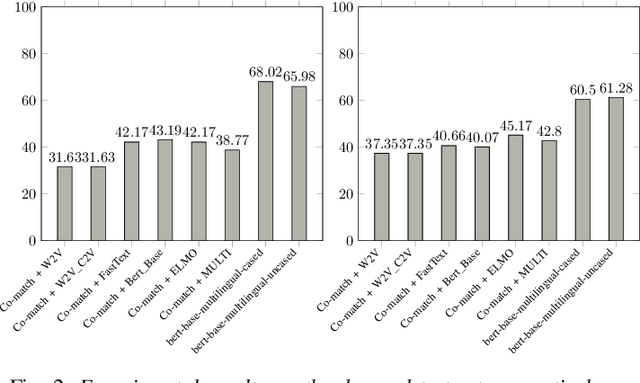
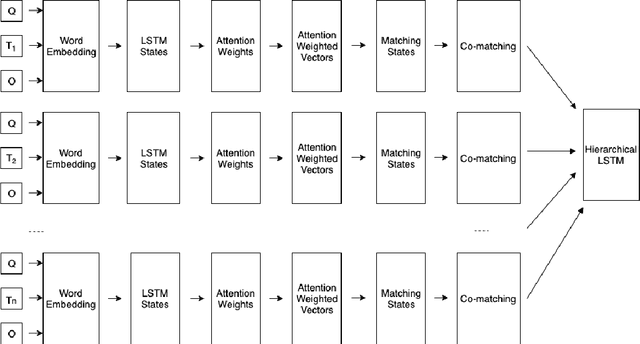
Machine reading comprehension (MRC) is a challenging task in natural language processing that makes computers understanding natural language texts and answer questions based on those texts. There are many techniques for solving this problems, and word representation is a very important technique that impact most to the accuracy of machine reading comprehension problem in the popular languages like English and Chinese. However, few studies on MRC have been conducted in low-resource languages such as Vietnamese. In this paper, we conduct several experiments on neural network-based model to understand the impact of word representation to the Vietnamese multiple-choice machine reading comprehension. Our experiments include using the Co-match model on six different Vietnamese word embeddings and the BERT model for multiple-choice reading comprehension. On the ViMMRC corpus, the accuracy of BERT model is 61.28% on test set.
New Vietnamese Corpus for Machine ReadingComprehension of Health News Articles
Jun 19, 2020



Although over 95 million people in the world speak the Vietnamese language, there are not any large and qualified datasets for automatic reading comprehension. In addition, machine reading comprehension for the health domain offers great potential for practical applications; however, there is still very little machine reading comprehension research in this domain. In this study, we present ViNewsQA as a new corpus for the low-resource Vietnamese language to evaluate models of machine reading comprehension. The corpus comprises 10,138 human-generated question-answer pairs. Crowdworkers created the questions and answers based on a set of over 2,030 online Vietnamese news articles from the VnExpress news website, where the answers comprised spans extracted from the corresponding articles. In particular, we developed a process of creating a corpus for the Vietnamese language. Comprehensive evaluations demonstrated that our corpus requires abilities beyond simple reasoning such as word matching, as well as demanding difficult reasoning similar to inferences based on single-or-multiple-sentence information. We conducted experiments using state-of-the-art methods for machine reading comprehension to obtain the first baseline performance measures, which will be compared with further models' performances. We measured human performance based on the corpus and compared it with several strong neural models. Our experiments showed that the best model was BERT, which achieved an exact match score of 57.57% and F1-score of 76.90% on our corpus. The significant difference between humans and the best model (F1-score of 15.93%) on the test set of our corpus indicates that improvements in ViNewsQA can be explored in future research. Our corpus is freely available on our website in order to encourage the research community to make these improvements.
Job Prediction: From Deep Neural Network Models to Applications
Jan 31, 2020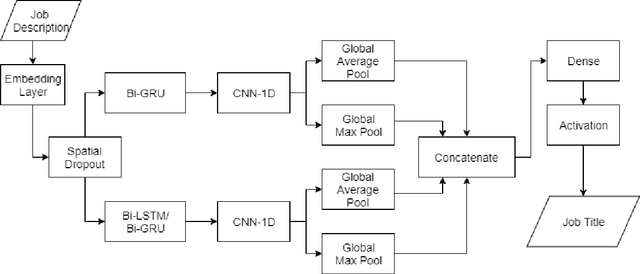
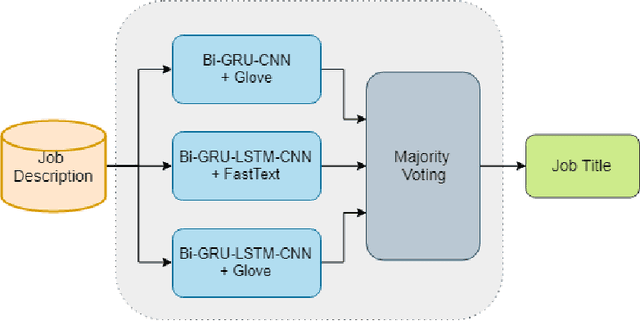
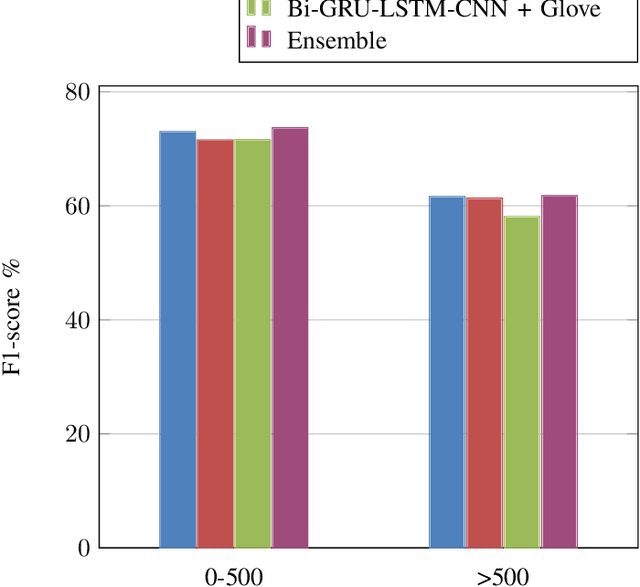
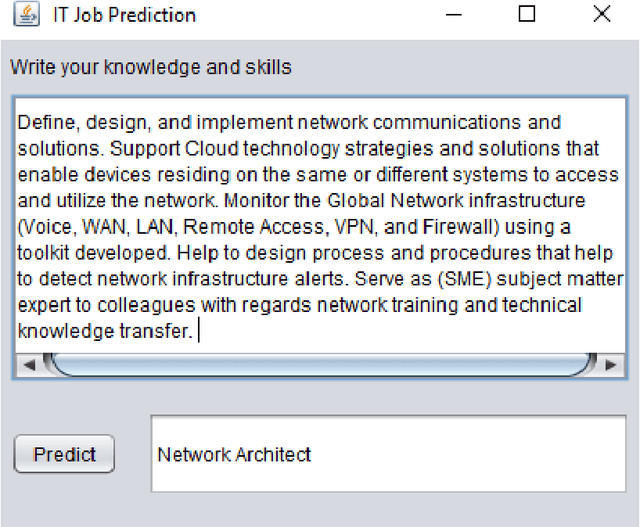
Determining the job is suitable for a student or a person looking for work based on their job's descriptions such as knowledge and skills that are difficult, as well as how employers must find ways to choose the candidates that match the job they require. In this paper, we focus on studying the job prediction using different deep neural network models including TextCNN, Bi-GRU-LSTM-CNN, and Bi-GRU-CNN with various pre-trained word embeddings on the IT Job dataset. In addition, we also proposed a simple and effective ensemble model combining different deep neural network models. The experimental results illustrated that our proposed ensemble model achieved the highest result with an F1 score of 72.71%. Moreover, we analyze these experimental results to have insights about this problem to find better solutions in the future.
A Pilot Study on Multiple Choice Machine Reading Comprehension for Vietnamese Texts
Jan 16, 2020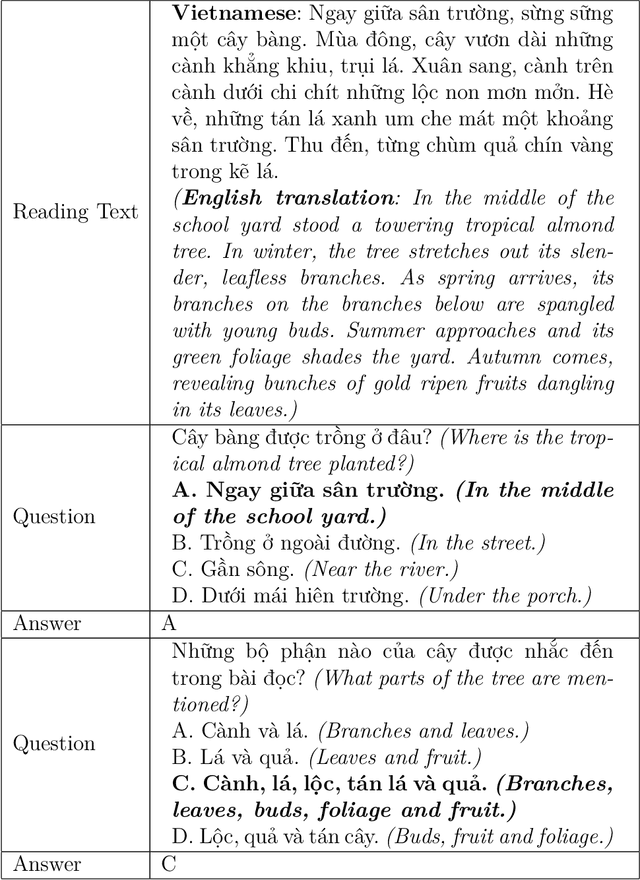

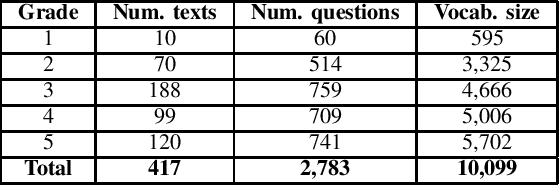
Machine Reading Comprehension (MRC) is the task of natural language processing which studies the ability to read and understand unstructured texts and then find the correct answers for questions. Until now, we have not yet had any MRC dataset for such a low-resource language as Vietnamese. In this paper, we introduce ViMMRC, a challenging machine comprehension corpus with multiple-choice questions, intended for research on the machine comprehension of Vietnamese text. This corpus includes 2,783 multiple-choice questions and answers based on a set of 417 Vietnamese texts used for teaching reading comprehension for 1st to 5th graders. Answers may be extracted from the contents of single or multiple sentences in the corresponding reading text. A thorough analysis of the corpus and experimental results in this paper illustrate that our corpus ViMMRC demands reasoning abilities beyond simple word matching. We proposed the method of Boosted Sliding Window (BSW) that improves 5.51% in accuracy over the best baseline method. We also measured human performance on the corpus and compared it to our MRC models. The performance gap between humans and our best experimental model indicates that significant progress can be made on Vietnamese machine reading comprehension in further research. The corpus is freely available at our website for research purposes.