 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveillance Camera Fight Dataset
Papers and Code
ForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance
Mar 24, 2026Despite decades of work, surveillance still struggles to find specific targets across long, multi-camera video. Prior methods -- tracking pipelines, CLIP based models, and VideoRAG -- require heavy manual filtering, capture only shallow attributes, and fail at temporal reasoning. Real-world searches are inherently multimodal (e.g., "When does this person join the fight?" with the person's image), yet this setting remains underexplored. Also, there are no proper benchmarks to evaluate those setting - asking video with multimodal queries. To address this gap, we introduce ForeSeaQA, a new benchmark specifically designed for video QA with image-and-text queries and timestamped annotations of key events. The dataset consists of long-horizon surveillance footage paired with diverse multimodal questions, enabling systematic evaluation of retrieval, temporal grounding, and multimodal reasoning in realistic forensic conditions. Not limited to this benchmark, we propose ForeSea, an AI forensic search system with a 3-stage, plug-and-play pipeline. (1) A tracking module filters irrelevant footage; (2) a multimodal embedding module indexes the remaining clips; and (3) during inference, the system retrieves top-K candidate clips for a Video Large Language Model (VideoLLM) to answer queries and localize events. On ForeSeaQA, ForeSea improves accuracy by 3.5% and temporal IoU by 11.0 over prior VideoRAG models. To our knowledge, ForeSeaQA is the first benchmark to support complex multimodal queries with precise temporal grounding, and ForeSea is the first VideoRAG system built to excel in this setting.
JOSENet: A Joint Stream Embedding Network for Violence Detection in Surveillance Videos
May 05, 2024



Due to the ever-increasing availability of video surveillance cameras and the growing need for crime prevention, the violence detection task is attracting greater attention from the research community. With respect to other action recognition tasks, violence detection in surveillance videos shows additional issues, such as the presence of a significant variety of real fight scenes. Unfortunately, available datasets seem to be very small compared with other action recognition datasets. Moreover, in surveillance applications, people in the scenes always differ for each video and the background of the footage differs for each camera. Also, violent actions in real-life surveillance videos must be detected quickly to prevent unwanted consequences, thus models would definitely benefit from a reduction in memory usage and computational costs. Such problems make classical action recognition methods difficult to be adopted. To tackle all these issues, we introduce JOSENet, a novel self-supervised framework that provides outstanding performance for violence detection in surveillance videos. The proposed model receives two spatiotemporal video streams, i.e., RGB frames and optical flows, and involves a new regularized self-supervised learning approach for videos. JOSENet provides improved performance compared to self-supervised state-of-the-art methods, while requiring one-fourth of the number of frames per video segment and a reduced frame rate. The source code and the instructions to reproduce our experiments are available at https://github.com/ispamm/JOSENet.
Estimating Distances Between People using a Single Overhead Fisheye Camera with Application to Social-Distancing Oversight
Mar 21, 2023



Unobtrusive monitoring of distances between people indoors is a useful tool in the fight against pandemics. A natural resource to accomplish this are surveillance cameras. Unlike previous distance estimation methods, we use a single, overhead, fisheye camera with wide area coverage and propose two approaches. One method leverages a geometric model of the fisheye lens, whereas the other method uses a neural network to predict the 3D-world distance from people-locations in a fisheye image. To evaluate our algorithms, we collected a first-of-its-kind dataset using single fisheye camera, that comprises a wide range of distances between people (1-58 ft) and will be made publicly available. The algorithms achieve 1-2 ft distance error and over 95% accuracy in detecting social-distance violations.
Video Vision Transformers for Violence Detection
Sep 08, 2022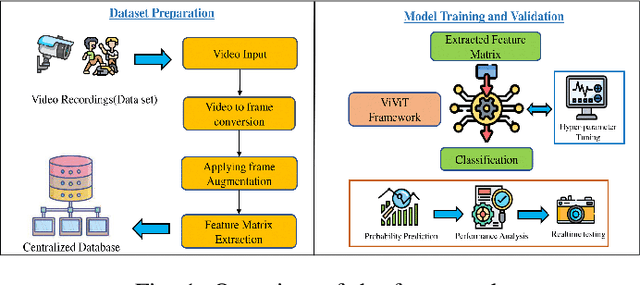
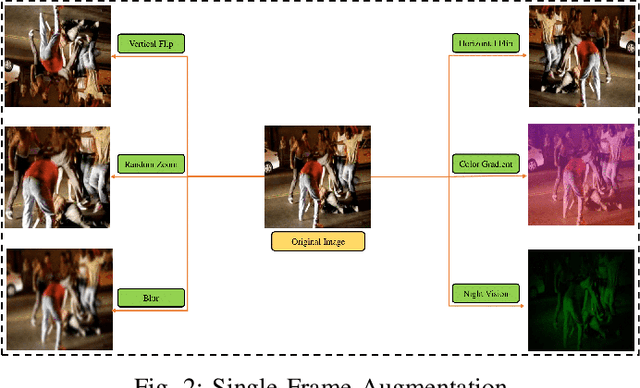
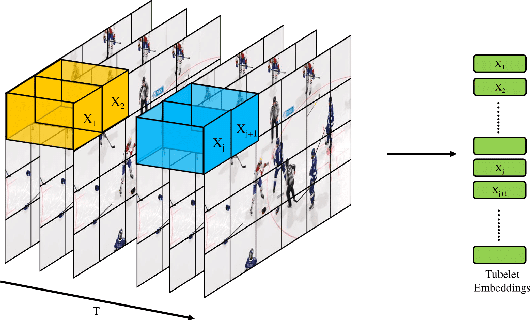
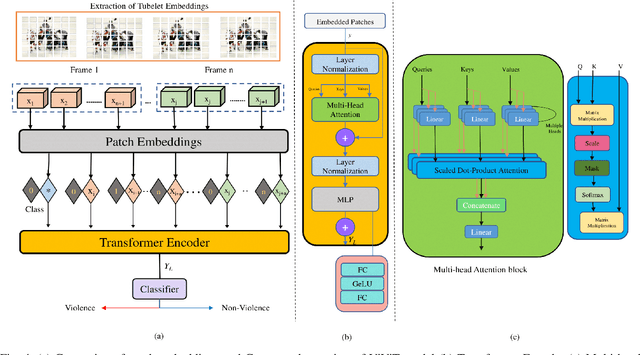
Law enforcement and city safety are significantly impacted by detecting violent incidents in surveillance systems. Although modern (smart) cameras are widely available and affordable, such technological solutions are impotent in most instances. Furthermore, personnel monitoring CCTV recordings frequently show a belated reaction, resulting in the potential cause of catastrophe to people and property. Thus automated detection of violence for swift actions is very crucial. The proposed solution uses a novel end-to-end deep learning-based video vision transformer (ViViT) that can proficiently discern fights, hostile movements, and violent events in video sequences. The study presents utilizing a data augmentation strategy to overcome the downside of weaker inductive biasness while training vision transformers on a smaller training datasets. The evaluated results can be subsequently sent to local concerned authority, and the captured video can be analyzed. In comparison to state-of-theart (SOTA) approaches the proposed method achieved auspicious performance on some of the challenging benchmark datasets.
Detecting Violence in Video Based on Deep Features Fusion Technique
Apr 15, 2022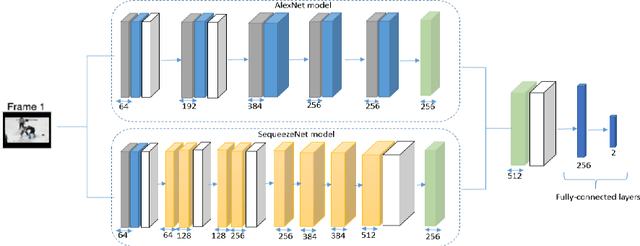
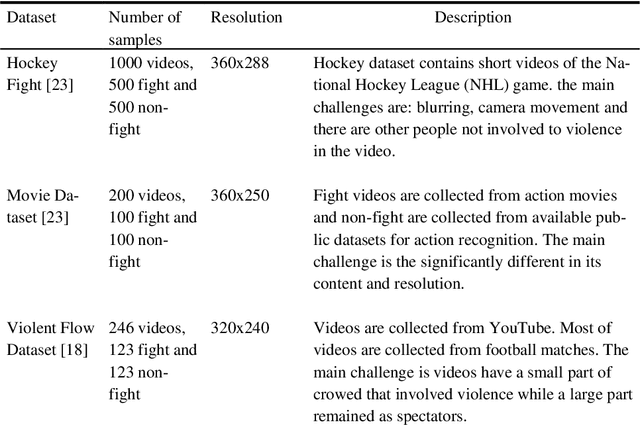
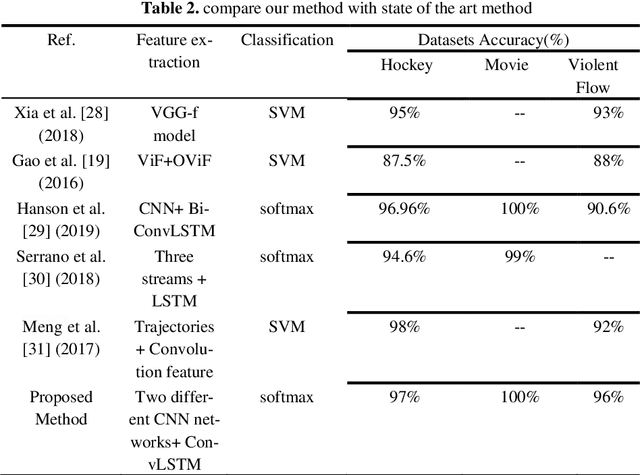

With the rapid growth of surveillance cameras in many public places to mon-itor human activities such as in malls, streets, schools and, prisons, there is a strong demand for such systems to detect violence events automatically. Au-tomatic analysis of video to detect violence is significant for law enforce-ment. Moreover, it helps to avoid any social, economic and environmental damages. Mostly, all systems today require manual human supervisors to de-tect violence scenes in the video which is inefficient and inaccurate. in this work, we interest in physical violence that involved two persons or more. This work proposed a novel method to detect violence using a fusion tech-nique of two significantly different convolutional neural networks (CNNs) which are AlexNet and SqueezeNet networks. Each network followed by separate Convolution Long Short Term memory (ConvLSTM) to extract ro-bust and richer features from a video in the final hidden state. Then, making a fusion of these two obtained states and fed to the max-pooling layer. Final-ly, features were classified using a series of fully connected layers and soft-max classifier. The performance of the proposed method is evaluated using three standard benchmark datasets in terms of detection accuracy: Hockey Fight dataset, Movie dataset and Violent Flow dataset. The results show an accuracy of 97%, 100%, and 96% respectively. A comparison of the results with the state of the art techniques revealed the promising capability of the proposed method in recognizing violent videos.
Vision-based Fight Detection from Surveillance Cameras
Feb 11, 2020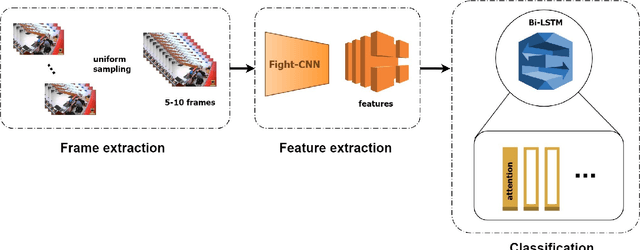



Vision-based action recognition is one of the most challenging research topics of computer vision and pattern recognition. A specific application of it, namely, detecting fights from surveillance cameras in public areas, prisons, etc., is desired to quickly get under control these violent incidents. This paper addresses this research problem and explores LSTM-based approaches to solve it. Moreover, the attention layer is also utilized. Besides, a new dataset is collected, which consists of fight scenes from surveillance camera videos available at YouTube. This dataset is made publicly available. From the extensive experiments conducted on Hockey Fight, Peliculas, and the newly collected fight datasets, it is observed that the proposed approach, which integrates Xception model, Bi-LSTM, and attention, improves the state-of-the-art accuracy for fight scene classification.