 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicContextEval: A Benchmark for Evaluating Context Utilisation in Audio Large Language Models Across 8 Indic Languages
Jun 17, 2026AudioLLMs enable speech recognition conditioned on textual prompts such as domain descriptions or entity lists. However, it remains unclear whether these models genuinely utilise such context or rely on parametric knowledge learned during pretraining. Existing benchmarks cannot answer this question because they evaluate transcription under fixed prompting conditions and rarely include explicit contextual inputs. We introduce IndicContextEval, a 56-hour multilingual benchmark of natural speech from 555 speakers across 8 Indian languages and 23 professional domains. We design a 7-level prompting framework that progressively introduces contextual signals, including metadata, natural-language descriptions, entity lists in English and native script, and adversarial prompts with incorrect entities. Evaluating five models reveals substantial differences in context utilisation behaviour, highlighting the need for explicit evaluation of contextual grounding in AudioLLMs.
SARCH: Multimodal Search for Archaeological Archives
Nov 07, 2025In this paper, we describe a multi-modal search system designed to search old archaeological books and reports. This corpus is digitally available as scanned PDFs, but varies widely in the quality of scans. Our pipeline, designed for multi-modal archaeological documents, extracts and indexes text, images (classified into maps, photos, layouts, and others), and tables. We evaluated different retrieval strategies, including keyword-based search, embedding-based models, and a hybrid approach that selects optimal results from both modalities. We report and analyze our preliminary results and discuss future work in this exciting vertical.
Video Vision Transformers for Violence Detection
Sep 08, 2022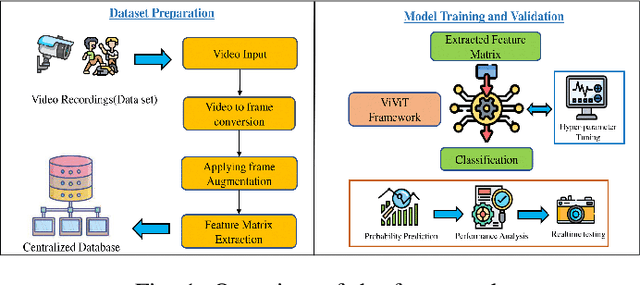
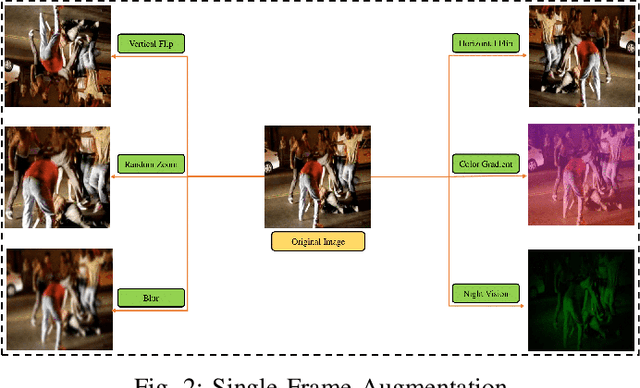
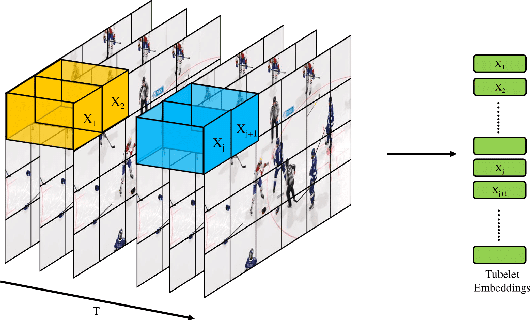
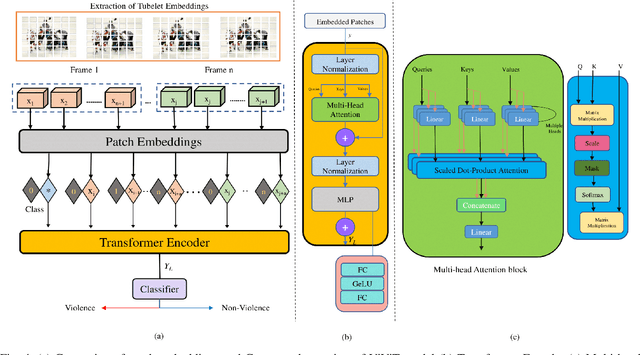
Law enforcement and city safety are significantly impacted by detecting violent incidents in surveillance systems. Although modern (smart) cameras are widely available and affordable, such technological solutions are impotent in most instances. Furthermore, personnel monitoring CCTV recordings frequently show a belated reaction, resulting in the potential cause of catastrophe to people and property. Thus automated detection of violence for swift actions is very crucial. The proposed solution uses a novel end-to-end deep learning-based video vision transformer (ViViT) that can proficiently discern fights, hostile movements, and violent events in video sequences. The study presents utilizing a data augmentation strategy to overcome the downside of weaker inductive biasness while training vision transformers on a smaller training datasets. The evaluated results can be subsequently sent to local concerned authority, and the captured video can be analyzed. In comparison to state-of-theart (SOTA) approaches the proposed method achieved auspicious performance on some of the challenging benchmark datasets.