 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePieapp Dataset
Papers and Code
Evaluating the Stability of Deep Image Quality Assessment With Respect to Image Scaling
Jul 20, 2022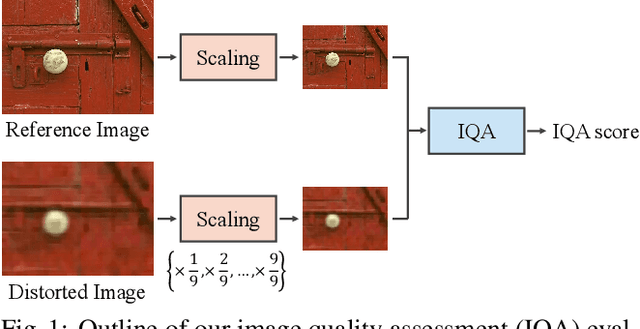

Image quality assessment (IQA) is a fundamental metric for image processing tasks (e.g., compression). With full-reference IQAs, traditional IQAs, such as PSNR and SSIM, have been used. Recently, IQAs based on deep neural networks (deep IQAs), such as LPIPS and DISTS, have also been used. It is known that image scaling is inconsistent among deep IQAs, as some perform down-scaling as pre-processing, whereas others instead use the original image size. In this paper, we show that the image scale is an influential factor that affects deep IQA performance. We comprehensively evaluate four deep IQAs on the same five datasets, and the experimental results show that image scale significantly influences IQA performance. We found that the most appropriate image scale is often neither the default nor the original size, and the choice differs depending on the methods and datasets used. We visualized the stability and found that PieAPP is the most stable among the four deep IQAs.
PieAPP: Perceptual Image-Error Assessment through Pairwise Preference
Jun 06, 2018
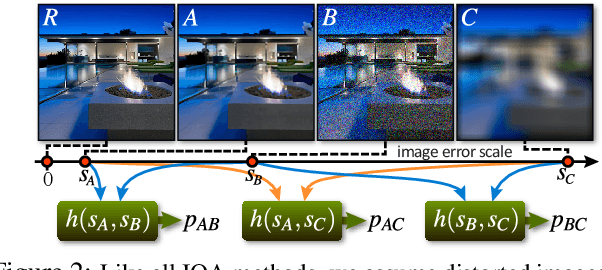
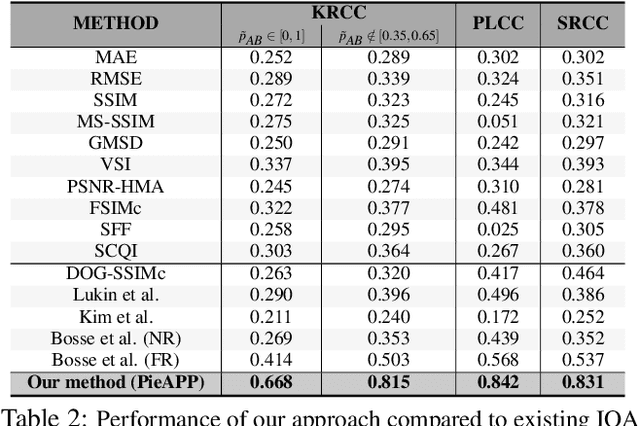
The ability to estimate the perceptual error between images is an important problem in computer vision with many applications. Although it has been studied extensively, however, no method currently exists that can robustly predict visual differences like humans. Some previous approaches used hand-coded models, but they fail to model the complexity of the human visual system. Others used machine learning to train models on human-labeled datasets, but creating large, high-quality datasets is difficult because people are unable to assign consistent error labels to distorted images. In this paper, we present a new learning-based method that is the first to predict perceptual image error like human observers. Since it is much easier for people to compare two given images and identify the one more similar to a reference than to assign quality scores to each, we propose a new, large-scale dataset labeled with the probability that humans will prefer one image over another. We then train a deep-learning model using a novel, pairwise-learning framework to predict the preference of one distorted image over the other. Our key observation is that our trained network can then be used separately with only one distorted image and a reference to predict its perceptual error, without ever being trained on explicit human perceptual-error labels. The perceptual error estimated by our new metric, PieAPP, is well-correlated with human opinion. Furthermore, it significantly outperforms existing algorithms, beating the state-of-the-art by almost 3x on our test set in terms of binary error rate, while also generalizing to new kinds of distortions, unlike previous learning-based methods.
* 8 pages; 5 figures; proceedings of CVPR 2018