 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic21
Papers and Code
Comparative Assessment of Markov Models and Recurrent Neural Networks for Jazz Music Generation
Sep 14, 2023As generative models have risen in popularity, a domain that has risen alongside is generative models for music. Our study aims to compare the performance of a simple Markov chain model and a recurrent neural network (RNN) model, two popular models for sequence generating tasks, in jazz music improvisation. While music, especially jazz, remains subjective in telling whether a composition is "good" or "bad", we aim to quantify our results using metrics of groove pattern similarity and pitch class histogram entropy. We trained both models using transcriptions of jazz blues choruses from professional jazz players, and also fed musical jazz seeds to help give our model some context in beginning the generation. Our results show that the RNN outperforms the Markov model on both of our metrics, indicating better rhythmic consistency and tonal stability in the generated music. Through the use of music21 library, we tokenized our jazz dataset into pitches and durations that our model could interpret and train on. Our findings contribute to the growing field of AI-generated music, highlighting the important use of metrics to assess generation quality. Future work includes expanding the dataset of MIDI files to a larger scale, conducting human surveys for subjective evaluations, and incorporating additional metrics to address the challenge of subjectivity in music evaluation. Our study provides valuable insight into the use of recurrent neural networks for sequential based tasks like generating music.
Optimizing Feature Extraction for Symbolic Music
Jul 11, 2023This paper presents a comprehensive investigation of existing feature extraction tools for symbolic music and contrasts their performance to determine the set of features that best characterizes the musical style of a given music score. In this regard, we propose a novel feature extraction tool, named musif, and evaluate its efficacy on various repertoires and file formats, including MIDI, MusicXML, and **kern. Musif approximates existing tools such as jSymbolic and music21 in terms of computational efficiency while attempting to enhance the usability for custom feature development. The proposed tool also enhances classification accuracy when combined with other sets of features. We demonstrate the contribution of each set of features and the computational resources they require. Our findings indicate that the optimal tool for feature extraction is a combination of the best features from each tool rather than those of a single one. To facilitate future research in music information retrieval, we release the source code of the tool and benchmarks.
TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation
Oct 26, 2021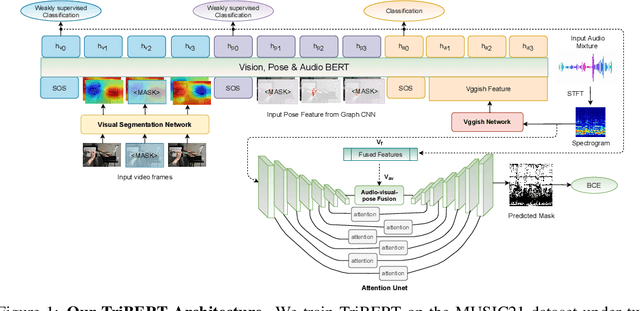

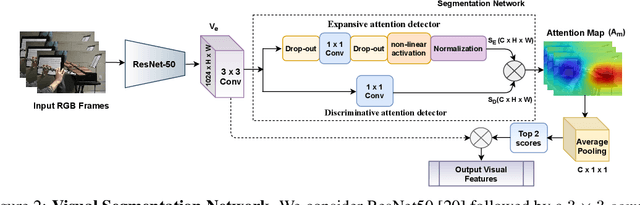
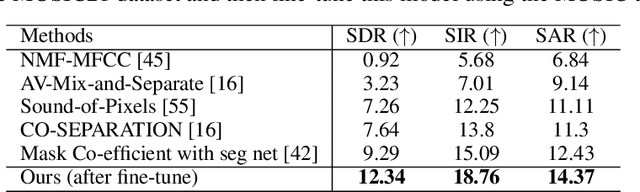
The recent success of transformer models in language, such as BERT, has motivated the use of such architectures for multi-modal feature learning and tasks. However, most multi-modal variants (e.g., ViLBERT) have limited themselves to visual-linguistic data. Relatively few have explored its use in audio-visual modalities, and none, to our knowledge, illustrate them in the context of granular audio-visual detection or segmentation tasks such as sound source separation and localization. In this work, we introduce TriBERT -- a transformer-based architecture, inspired by ViLBERT, which enables contextual feature learning across three modalities: vision, pose, and audio, with the use of flexible co-attention. The use of pose keypoints is inspired by recent works that illustrate that such representations can significantly boost performance in many audio-visual scenarios where often one or more persons are responsible for the sound explicitly (e.g., talking) or implicitly (e.g., sound produced as a function of human manipulating an object). From a technical perspective, as part of the TriBERT architecture, we introduce a learned visual tokenization scheme based on spatial attention and leverage weak-supervision to allow granular cross-modal interactions for visual and pose modalities. Further, we supplement learning with sound-source separation loss formulated across all three streams. We pre-train our model on the large MUSIC21 dataset and demonstrate improved performance in audio-visual sound source separation on that dataset as well as other datasets through fine-tuning. In addition, we show that the learned TriBERT representations are generic and significantly improve performance on other audio-visual tasks such as cross-modal audio-visual-pose retrieval by as much as 66.7% in top-1 accuracy.
* 10 pages, 5 Figures, Neurips 2021