 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepsim
Papers and Code
DeepSim-Nets: Deep Similarity Networks for Stereo Image Matching
Apr 17, 2023



We present three multi-scale similarity learning architectures, or DeepSim networks. These models learn pixel-level matching with a contrastive loss and are agnostic to the geometry of the considered scene. We establish a middle ground between hybrid and end-to-end approaches by learning to densely allocate all corresponding pixels of an epipolar pair at once. Our features are learnt on large image tiles to be expressive and capture the scene's wider context. We also demonstrate that curated sample mining can enhance the overall robustness of the predicted similarities and improve the performance on radiometrically homogeneous areas. We run experiments on aerial and satellite datasets. Our DeepSim-Nets outperform the baseline hybrid approaches and generalize better to unseen scene geometries than end-to-end methods. Our flexible architecture can be readily adopted in standard multi-resolution image matching pipelines.
DeepSim: A Reinforcement Learning Environment Build Toolkit for ROS and Gazebo
May 17, 2022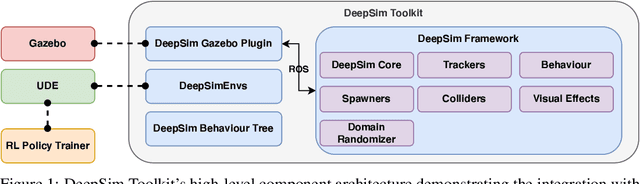
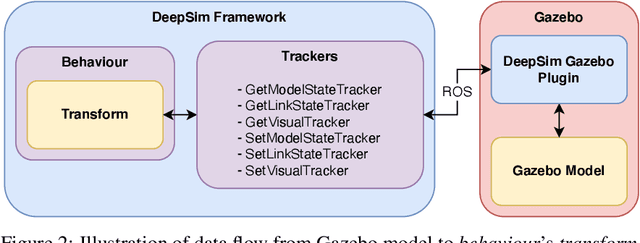
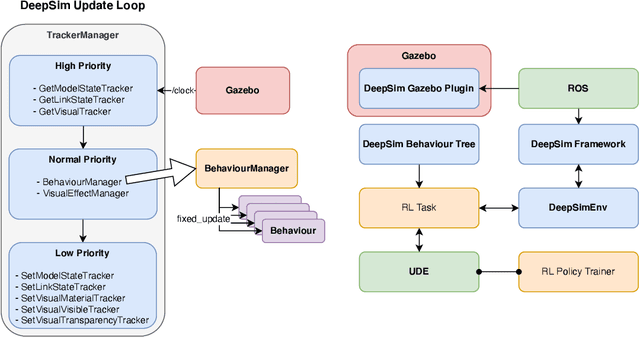
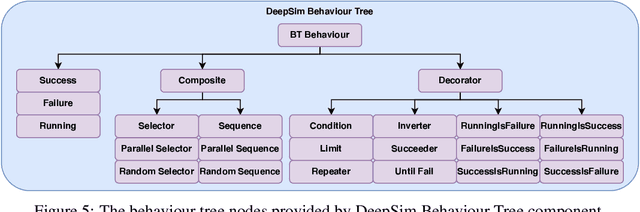
We propose DeepSim, a reinforcement learning environment build toolkit for ROS and Gazebo. It allows machine learning or reinforcement learning researchers to access the robotics domain and create complex and challenging custom tasks in ROS and Gazebo simulation environments. This toolkit provides building blocks of advanced features such as collision detection, behaviour control, domain randomization, spawner, and many more. DeepSim is designed to reduce the boundary between robotics and machine learning communities by providing Python interface. In this paper, we discuss the components and design decisions of DeepSim Toolkit.
Image Shape Manipulation from a Single Augmented Training Sample
Sep 13, 2021
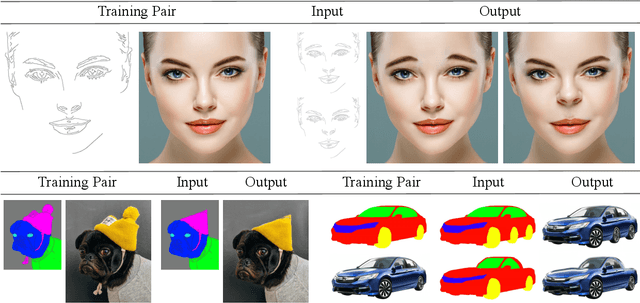


In this paper, we present DeepSIM, a generative model for conditional image manipulation based on a single image. We find that extensive augmentation is key for enabling single image training, and incorporate the use of thin-plate-spline (TPS) as an effective augmentation. Our network learns to map between a primitive representation of the image to the image itself. The choice of a primitive representation has an impact on the ease and expressiveness of the manipulations and can be automatic (e.g. edges), manual (e.g. segmentation) or hybrid such as edges on top of segmentations. At manipulation time, our generator allows for making complex image changes by modifying the primitive input representation and mapping it through the network. Our method is shown to achieve remarkable performance on image manipulation tasks.
DeepSim: Semantic similarity metrics for learned image registration
Nov 11, 2020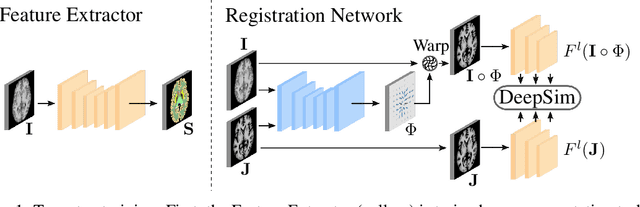
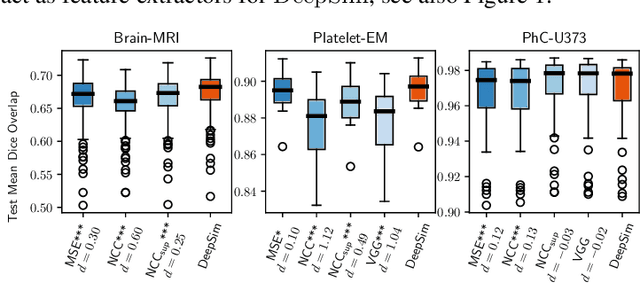
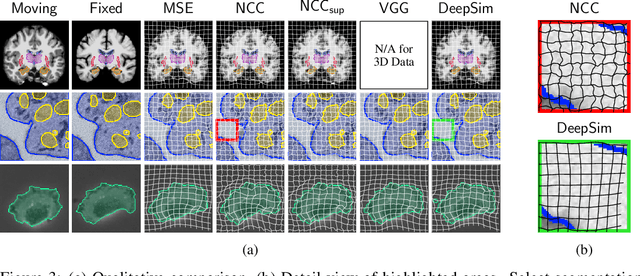
We propose a semantic similarity metric for image registration. Existing metrics like euclidean distance or normalized cross-correlation focus on aligning intensity values, giving difficulties with low intensity contrast or noise. Our semantic approach learns dataset-specific features that drive the optimization of a learning-based registration model. Comparing to existing unsupervised and supervised methods across multiple image modalities and applications, we achieve consistently high registration accuracy and faster convergence than state of the art, and the learned invariance to noise gives smoother transformations on low-quality images.
Generating Images with Perceptual Similarity Metrics based on Deep Networks
Feb 09, 2016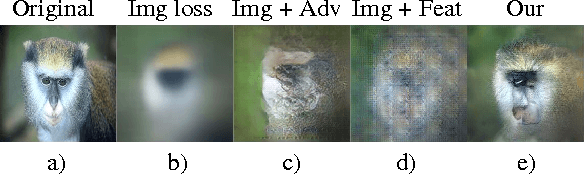

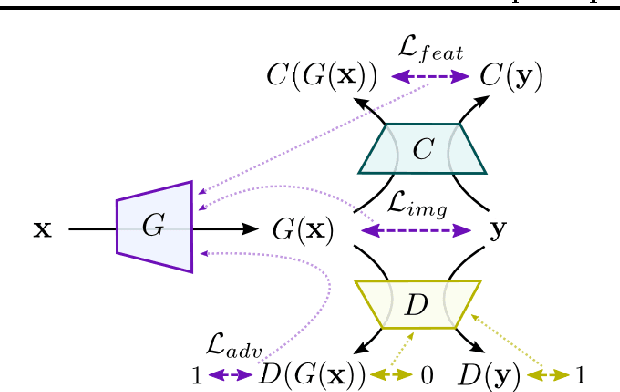
Image-generating machine learning models are typically trained with loss functions based on distance in the image space. This often leads to over-smoothed results. We propose a class of loss functions, which we call deep perceptual similarity metrics (DeePSiM), that mitigate this problem. Instead of computing distances in the image space, we compute distances between image features extracted by deep neural networks. This metric better reflects perceptually similarity of images and thus leads to better results. We show three applications: autoencoder training, a modification of a variational autoencoder, and inversion of deep convolutional networks. In all cases, the generated images look sharp and resemble natural images.