 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeqa
Papers and Code
Lost in Transcription: How Speech-to-Text Errors Derail Code Understanding
Jan 20, 2026Code understanding is a foundational capability in software engineering tools and developer workflows. However, most existing systems are designed for English-speaking users interacting via keyboards, which limits accessibility in multilingual and voice-first settings, particularly in regions like India. Voice-based interfaces offer a more inclusive modality, but spoken queries involving code present unique challenges due to the presence of non-standard English usage, domain-specific vocabulary, and custom identifiers such as variable and function names, often combined with code-mixed expressions. In this work, we develop a multilingual speech-driven framework for code understanding that accepts spoken queries in a user native language, transcribes them using Automatic Speech Recognition (ASR), applies code-aware ASR output refinement using Large Language Models (LLMs), and interfaces with code models to perform tasks such as code question answering and code retrieval through benchmarks such as CodeSearchNet, CoRNStack, and CodeQA. Focusing on four widely spoken Indic languages and English, we systematically characterize how transcription errors impact downstream task performance. We also identified key failure modes in ASR for code and demonstrated that LLM-guided refinement significantly improves performance across both transcription and code understanding stages. Our findings underscore the need for code-sensitive adaptations in speech interfaces and offer a practical solution for building robust, multilingual voice-driven programming tools.
SWE-QA: Can Language Models Answer Repository-level Code Questions?
Sep 18, 2025Understanding and reasoning about entire software repositories is an essential capability for intelligent software engineering tools. While existing benchmarks such as CoSQA and CodeQA have advanced the field, they predominantly focus on small, self-contained code snippets. These setups fail to capture the complexity of real-world repositories, where effective understanding and reasoning often require navigating multiple files, understanding software architecture, and grounding answers in long-range code dependencies. In this paper, we present SWE-QA, a repository-level code question answering (QA) benchmark designed to facilitate research on automated QA systems in realistic code environments. SWE-QA involves 576 high-quality question-answer pairs spanning diverse categories, including intention understanding, cross-file reasoning, and multi-hop dependency analysis. To construct SWE-QA, we first crawled 77,100 GitHub issues from 11 popular repositories. Based on an analysis of naturally occurring developer questions extracted from these issues, we developed a two-level taxonomy of repository-level questions and constructed a set of seed questions for each category. For each category, we manually curated and validated questions and collected their corresponding answers. As a prototype application, we further develop SWE-QA-Agent, an agentic framework in which LLM agents reason and act to find answers automatically. We evaluate six advanced LLMs on SWE-QA under various context augmentation strategies. Experimental results highlight the promise of LLMs, particularly our SWE-QA-Agent framework, in addressing repository-level QA, while also revealing open challenges and pointing to future research directions.
CodeQA: A Question Answering Dataset for Source Code Comprehension
Sep 17, 2021
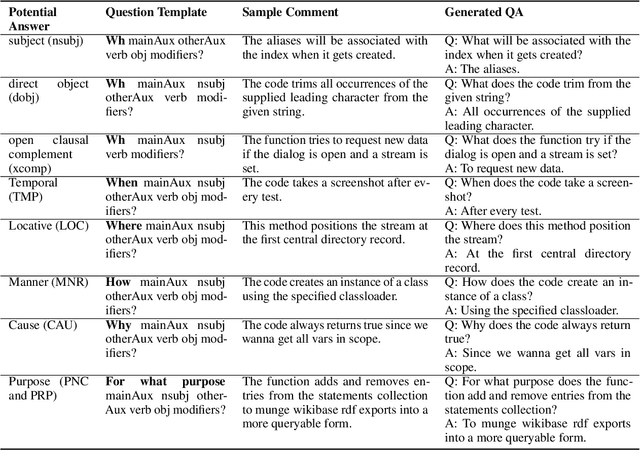
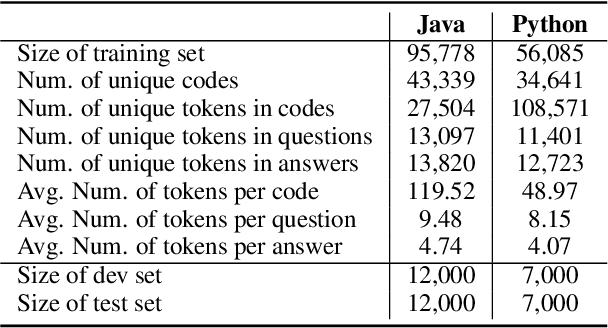
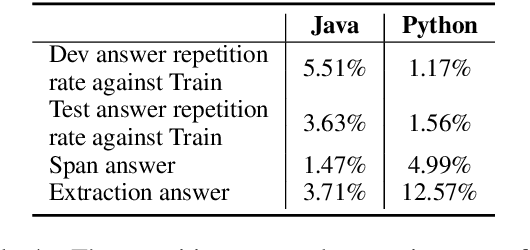
We propose CodeQA, a free-form question answering dataset for the purpose of source code comprehension: given a code snippet and a question, a textual answer is required to be generated. CodeQA contains a Java dataset with 119,778 question-answer pairs and a Python dataset with 70,085 question-answer pairs. To obtain natural and faithful questions and answers, we implement syntactic rules and semantic analysis to transform code comments into question-answer pairs. We present the construction process and conduct systematic analysis of our dataset. Experiment results achieved by several neural baselines on our dataset are shown and discussed. While research on question-answering and machine reading comprehension develops rapidly, few prior work has drawn attention to code question answering. This new dataset can serve as a useful research benchmark for source code comprehension.