 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBambara Language Dataset
Papers and Code
Where Are We At with Automatic Speech Recognition for the Bambara Language?
Feb 10, 2026This paper introduces the first standardized benchmark for evaluating Automatic Speech Recognition (ASR) in the Bambara language, utilizing one hour of professionally recorded Malian constitutional text. Designed as a controlled reference set under near-optimal acoustic and linguistic conditions, the benchmark was used to evaluate 37 models, ranging from Bambara-trained systems to large-scale commercial models. Our findings reveal that current ASR performance remains significantly below deployment standards in a narrow formal domain; the top-performing system in terms of Word Error Rate (WER) achieved 46.76\% and the best Character Error Rate (CER) of 13.00\% was set by another model, while several prominent multilingual models exceeded 100\% WER. These results suggest that multilingual pre-training and model scaling alone are insufficient for underrepresented languages. Furthermore, because this dataset represents a best-case scenario of the most simplified and formal form of spoken Bambara, these figures are yet to be tested against practical, real-world settings. We provide the benchmark and an accompanying public leaderboard to facilitate transparent evaluation and future research in Bambara speech technology.
Kunnafonidilaw ka Cadeau: an ASR dataset of present-day Bambara
Dec 22, 2025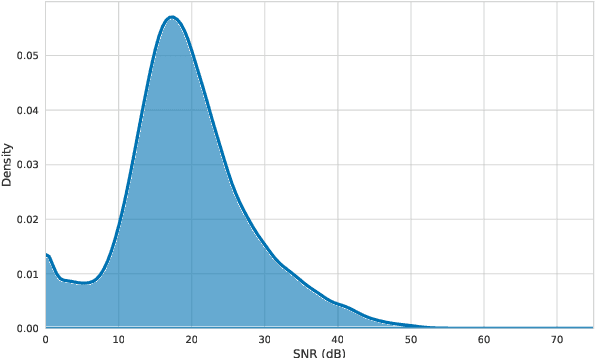
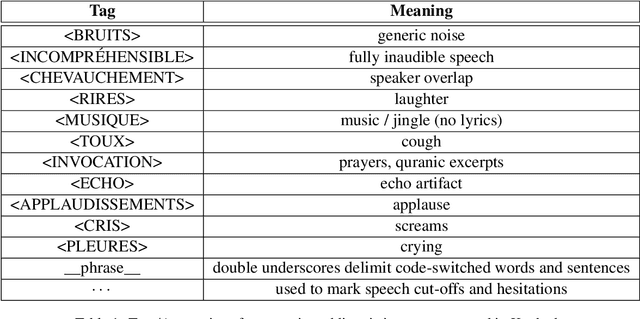
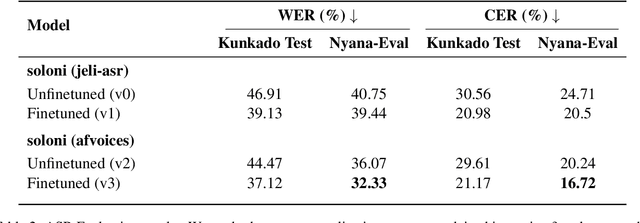
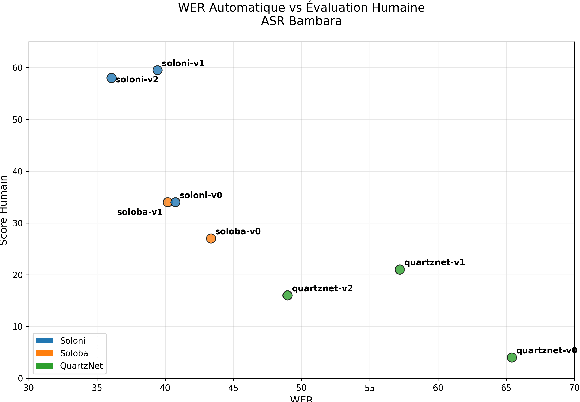
We present Kunkado, a 160-hour Bambara ASR dataset compiled from Malian radio archives to capture present-day spontaneous speech across a wide range of topics. It includes code-switching, disfluencies, background noise, and overlapping speakers that practical ASR systems encounter in real-world use. We finetuned Parakeet-based models on a 33.47-hour human-reviewed subset and apply pragmatic transcript normalization to reduce variability in number formatting, tags, and code-switching annotations. Evaluated on two real-world test sets, finetuning with Kunkado reduces WER from 44.47\% to 37.12\% on one and from 36.07\% to 32.33\% on the other. In human evaluation, the resulting model also outperforms a comparable system with the same architecture trained on 98 hours of cleaner, less realistic speech. We release the data and models to support robust ASR for predominantly oral languages.
Cost Analysis of Human-corrected Transcription for Predominately Oral Languages
Oct 14, 2025


Creating speech datasets for low-resource languages is a critical yet poorly understood challenge, particularly regarding the actual cost in human labor. This paper investigates the time and complexity required to produce high-quality annotated speech data for a subset of low-resource languages, low literacy Predominately Oral Languages, focusing on Bambara, a Manding language of Mali. Through a one-month field study involving ten transcribers with native proficiency, we analyze the correction of ASR-generated transcriptions of 53 hours of Bambara voice data. We report that it takes, on average, 30 hours of human labor to accurately transcribe one hour of speech data under laboratory conditions and 36 hours under field conditions. The study provides a baseline and practical insights for a large class of languages with comparable profiles undertaking the creation of NLP resources.
A comparison of pipelines for the translation of a low resource language based on transformers
Sep 15, 2025This work compares three pipelines for training transformer-based neural networks to produce machine translators for Bambara, a Mand\`e language spoken in Africa by about 14,188,850 people. The first pipeline trains a simple transformer to translate sentences from French into Bambara. The second fine-tunes LLaMA3 (3B-8B) instructor models using decoder-only architectures for French-to-Bambara translation. Models from the first two pipelines were trained with different hyperparameter combinations to improve BLEU and chrF scores, evaluated on both test sentences and official Bambara benchmarks. The third pipeline uses language distillation with a student-teacher dual neural network to integrate Bambara into a pre-trained LaBSE model, which provides language-agnostic embeddings. A BERT extension is then applied to LaBSE to generate translations. All pipelines were tested on Dokotoro (medical) and Bayelemagaba (mixed domains). Results show that the first pipeline, although simpler, achieves the best translation accuracy (10% BLEU, 21% chrF on Bayelemagaba), consistent with low-resource translation results. On the Yiri dataset, created for this work, it achieves 33.81% BLEU and 41% chrF. Instructor-based models perform better on single datasets than on aggregated collections, suggesting they capture dataset-specific patterns more effectively.
Bridging the Gap: Enhancing LLM Performance for Low-Resource African Languages with New Benchmarks, Fine-Tuning, and Cultural Adjustments
Dec 16, 2024Large Language Models (LLMs) have shown remarkable performance across various tasks, yet significant disparities remain for non-English languages, and especially native African languages. This paper addresses these disparities by creating approximately 1 million human-translated words of new benchmark data in 8 low-resource African languages, covering a population of over 160 million speakers of: Amharic, Bambara, Igbo, Sepedi (Northern Sotho), Shona, Sesotho (Southern Sotho), Setswana, and Tsonga. Our benchmarks are translations of Winogrande and three sections of MMLU: college medicine, clinical knowledge, and virology. Using the translated benchmarks, we report previously unknown performance gaps between state-of-the-art (SOTA) LLMs in English and African languages. Finally, using results from over 400 fine-tuned models, we explore several methods to reduce the LLM performance gap, including high-quality dataset fine-tuning (using an LLM-as-an-Annotator), cross-lingual transfer, and cultural appropriateness adjustments. Key findings include average mono-lingual improvements of 5.6% with fine-tuning (with 5.4% average mono-lingual improvements when using high-quality data over low-quality data), 2.9% average gains from cross-lingual transfer, and a 3.0% out-of-the-box performance boost on culturally appropriate questions. The publicly available benchmarks, translations, and code from this study support further research and development aimed at creating more inclusive and effective language technologies.
Bambara Language Dataset for Sentiment Analysis
Aug 05, 2021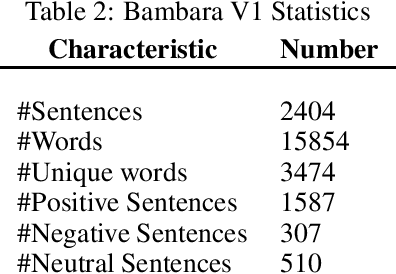
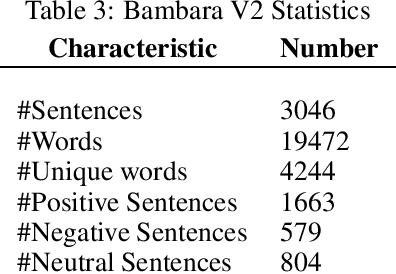
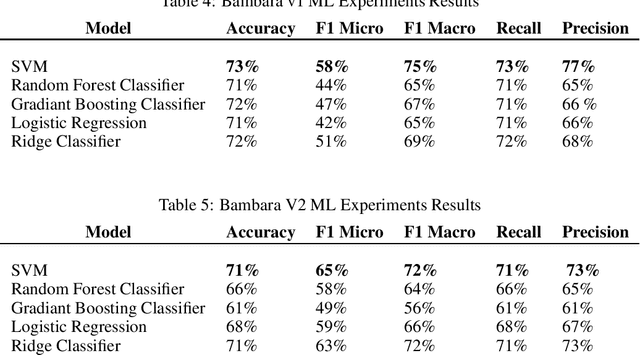

For easier communication, posting, or commenting on each others posts, people use their dialects. In Africa, various languages and dialects exist. However, they are still underrepresented and not fully exploited for analytical studies and research purposes. In order to perform approaches like Machine Learning and Deep Learning, datasets are required. One of the African languages is Bambara, used by citizens in different countries. However, no previous work on datasets for this language was performed for Sentiment Analysis. In this paper, we present the first common-crawl-based Bambara dialectal dataset dedicated for Sentiment Analysis, available freely for Natural Language Processing research purposes.
Domain-specific MT for Low-resource Languages: The case of Bambara-French
Mar 31, 2021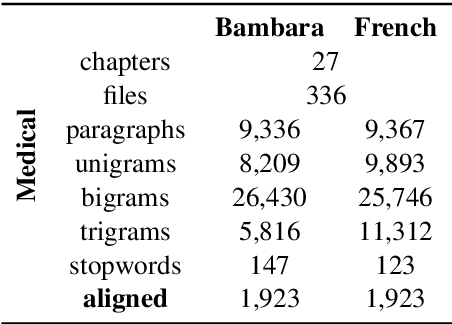
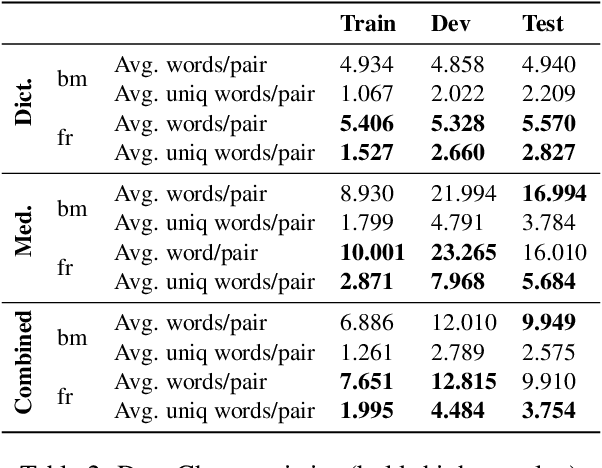
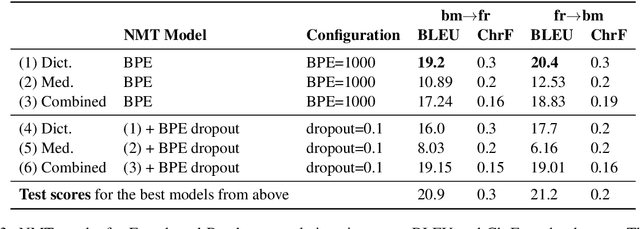
Translating to and from low-resource languages is a challenge for machine translation (MT) systems due to a lack of parallel data. In this paper we address the issue of domain-specific MT for Bambara, an under-resourced Mande language spoken in Mali. We present the first domain-specific parallel dataset for MT of Bambara into and from French. We discuss challenges in working with small quantities of domain-specific data for a low-resource language and we present the results of machine learning experiments on this data.
Multilingual training set selection for ASR in under-resourced Malian languages
Aug 13, 2021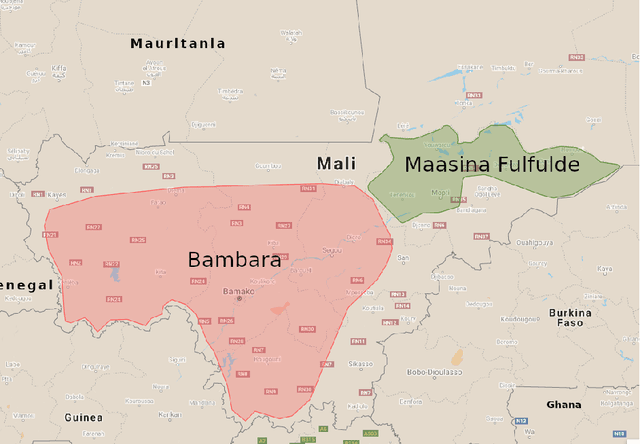

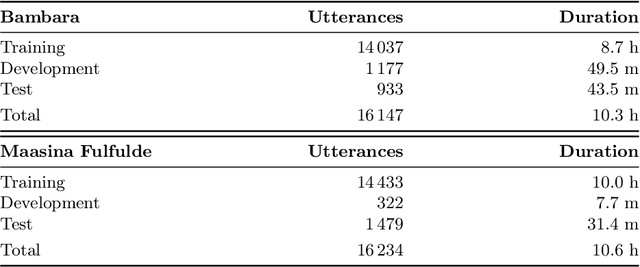
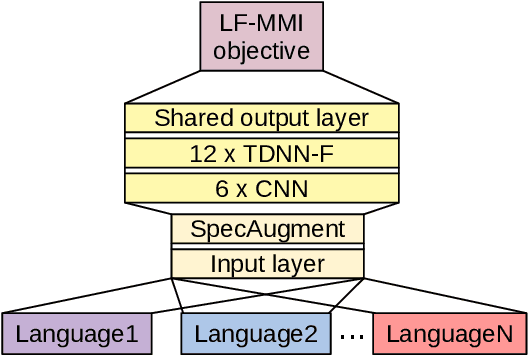
We present first speech recognition systems for the two severely under-resourced Malian languages Bambara and Maasina Fulfulde. These systems will be used by the United Nations as part of a monitoring system to inform and support humanitarian programmes in rural Africa. We have compiled datasets in Bambara and Maasina Fulfulde, but since these are very small, we take advantage of six similarly under-resourced datasets in other languages for multilingual training. We focus specifically on the best composition of the multilingual pool of speech data for multilingual training. We find that, although maximising the training pool by including all six additional languages provides improved speech recognition in both target languages, substantially better performance can be achieved by a more judicious choice. Our experiments show that the addition of just one language provides best performance. For Bambara, this additional language is Maasina Fulfulde, and its introduction leads to a relative word error rate reduction of 6.7%, as opposed to a 2.4% relative reduction achieved when pooling all six additional languages. For the case of Maasina Fulfulde, best performance was achieved when adding only Luganda, leading to a relative word error rate improvement of 9.4% as opposed to a 3.9% relative improvement when pooling all six languages. We conclude that careful selection of the out-of-language data is worthwhile for multilingual training even in highly under-resourced settings, and that the general assumption that more data is better does not always hold.