 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Are We At with Automatic Speech Recognition for the Bambara Language?
Feb 10, 2026This paper introduces the first standardized benchmark for evaluating Automatic Speech Recognition (ASR) in the Bambara language, utilizing one hour of professionally recorded Malian constitutional text. Designed as a controlled reference set under near-optimal acoustic and linguistic conditions, the benchmark was used to evaluate 37 models, ranging from Bambara-trained systems to large-scale commercial models. Our findings reveal that current ASR performance remains significantly below deployment standards in a narrow formal domain; the top-performing system in terms of Word Error Rate (WER) achieved 46.76\% and the best Character Error Rate (CER) of 13.00\% was set by another model, while several prominent multilingual models exceeded 100\% WER. These results suggest that multilingual pre-training and model scaling alone are insufficient for underrepresented languages. Furthermore, because this dataset represents a best-case scenario of the most simplified and formal form of spoken Bambara, these figures are yet to be tested against practical, real-world settings. We provide the benchmark and an accompanying public leaderboard to facilitate transparent evaluation and future research in Bambara speech technology.
Listen, Attend, Understand: a Regularization Technique for Stable E2E Speech Translation Training on High Variance labels
Jan 03, 2026End-to-End Speech Translation often shows slower convergence and worse performance when target transcriptions exhibit high variance and semantic ambiguity. We propose Listen, Attend, Understand (LAU), a semantic regularization technique that constrains the acoustic encoder's latent space during training. By leveraging frozen text embeddings to provide a directional auxiliary loss, LAU injects linguistic groundedness into the acoustic representation without increasing inference cost. We evaluate our method on a Bambara-to-French dataset with 30 hours of Bambara speech translated by non-professionals. Experimental results demonstrate that LAU models achieve comparable performance by standard metrics compared to an E2E-ST system pretrained with 100\% more data and while performing better in preserving semantic meaning. Furthermore, we introduce Total Parameter Drift as a metric to quantify the structural impact of regularization to demonstrate that semantic constraints actively reorganize the encoder's weights to prioritize meaning over literal phonetics. Our findings suggest that LAU is a robust alternative to post-hoc rescoring and a valuable addition to E2E-ST training, especially when training data is scarce and/or noisy.
Kunnafonidilaw ka Cadeau: an ASR dataset of present-day Bambara
Dec 22, 2025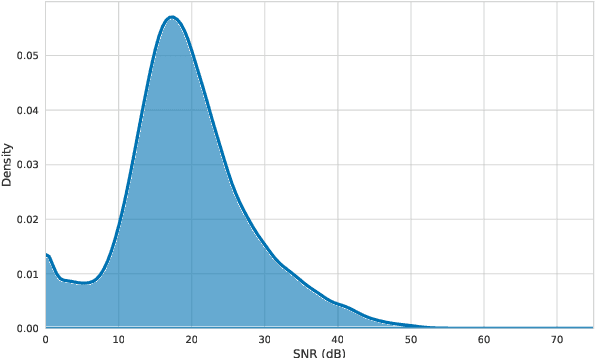
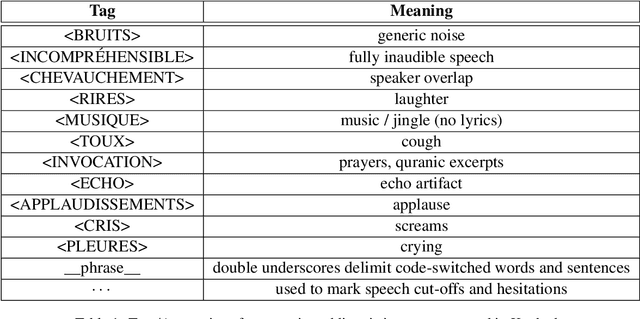
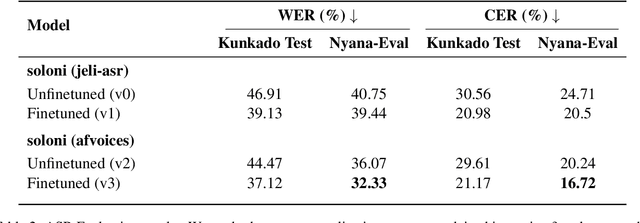
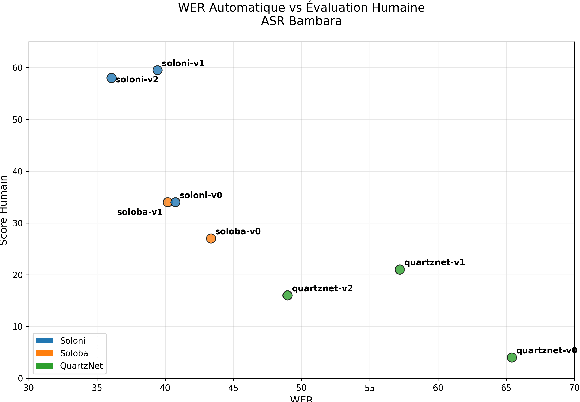
We present Kunkado, a 160-hour Bambara ASR dataset compiled from Malian radio archives to capture present-day spontaneous speech across a wide range of topics. It includes code-switching, disfluencies, background noise, and overlapping speakers that practical ASR systems encounter in real-world use. We finetuned Parakeet-based models on a 33.47-hour human-reviewed subset and apply pragmatic transcript normalization to reduce variability in number formatting, tags, and code-switching annotations. Evaluated on two real-world test sets, finetuning with Kunkado reduces WER from 44.47\% to 37.12\% on one and from 36.07\% to 32.33\% on the other. In human evaluation, the resulting model also outperforms a comparable system with the same architecture trained on 98 hours of cleaner, less realistic speech. We release the data and models to support robust ASR for predominantly oral languages.
Cost Analysis of Human-corrected Transcription for Predominately Oral Languages
Oct 14, 2025


Creating speech datasets for low-resource languages is a critical yet poorly understood challenge, particularly regarding the actual cost in human labor. This paper investigates the time and complexity required to produce high-quality annotated speech data for a subset of low-resource languages, low literacy Predominately Oral Languages, focusing on Bambara, a Manding language of Mali. Through a one-month field study involving ten transcribers with native proficiency, we analyze the correction of ASR-generated transcriptions of 53 hours of Bambara voice data. We report that it takes, on average, 30 hours of human labor to accurately transcribe one hour of speech data under laboratory conditions and 36 hours under field conditions. The study provides a baseline and practical insights for a large class of languages with comparable profiles undertaking the creation of NLP resources.