Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen silver glitters more than gold: Bootstrapping an Italian part-of-speech tagger for Twitter
Paper and Code


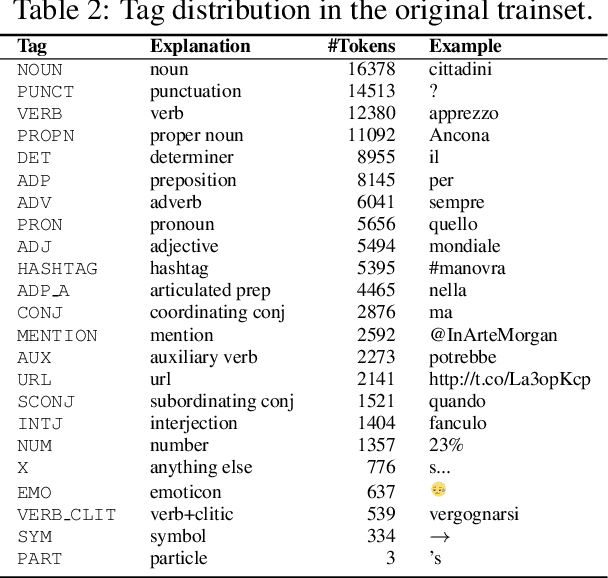
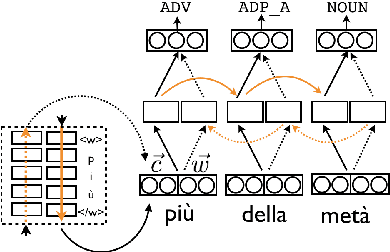
We bootstrap a state-of-the-art part-of-speech tagger to tag Italian Twitter data, in the context of the Evalita 2016 PoSTWITA shared task. We show that training the tagger on native Twitter data enriched with little amounts of specifically selected gold data and additional silver-labelled data scraped from Facebook, yields better results than using large amounts of manually annotated data from a mix of genres.
* Proceedings of the 5th Evaluation Campaign of Natural Language
Processing and Speech Tools for Italian (EVALITA 2016)
View paper on