 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model-Based Semantic-Guided Imaging Biomarker for Early Lung Cancer Detection
Paper and Code
Apr 30, 2025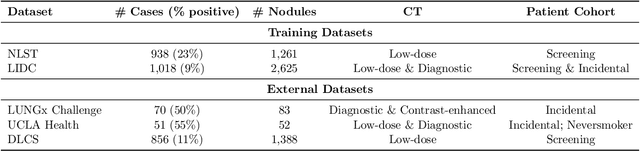
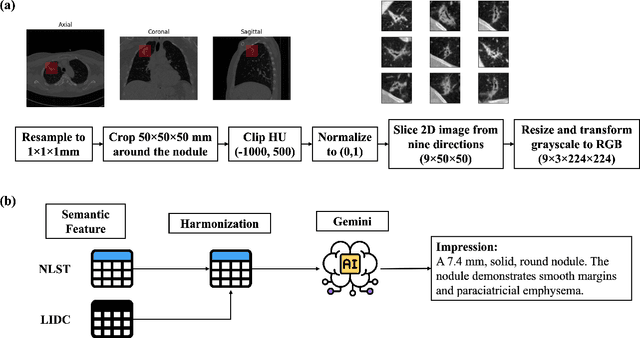
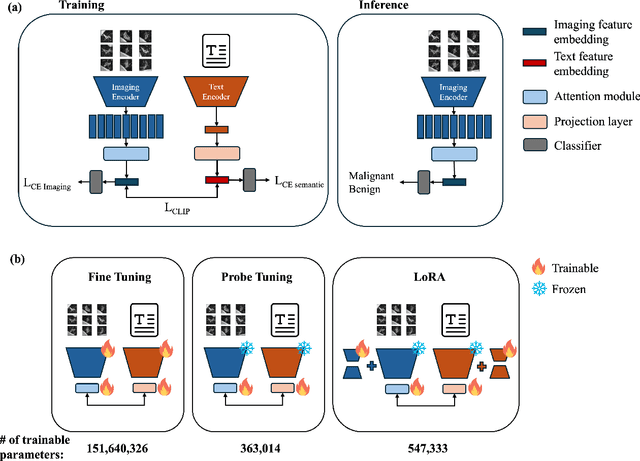
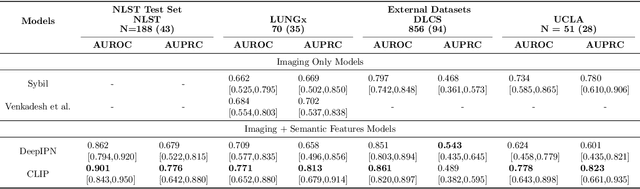
Objective: A number of machine learning models have utilized semantic features, deep features, or both to assess lung nodule malignancy. However, their reliance on manual annotation during inference, limited interpretability, and sensitivity to imaging variations hinder their application in real-world clinical settings. Thus, this research aims to integrate semantic features derived from radiologists' assessments of nodules, allowing the model to learn clinically relevant, robust, and explainable features for predicting lung cancer. Methods: We obtained 938 low-dose CT scans from the National Lung Screening Trial with 1,246 nodules and semantic features. The Lung Image Database Consortium dataset contains 1,018 CT scans, with 2,625 lesions annotated for nodule characteristics. Three external datasets were obtained from UCLA Health, the LUNGx Challenge, and the Duke Lung Cancer Screening. We finetuned a pretrained Contrastive Language-Image Pretraining model with a parameter-efficient fine-tuning approach to align imaging and semantic features and predict the one-year lung cancer diagnosis. Results: We evaluated the performance of the one-year diagnosis of lung cancer with AUROC and AUPRC and compared it to three state-of-the-art models. Our model demonstrated an AUROC of 0.90 and AUPRC of 0.78, outperforming baseline state-of-the-art models on external datasets. Using CLIP, we also obtained predictions on semantic features, such as nodule margin (AUROC: 0.81), nodule consistency (0.81), and pleural attachment (0.84), that can be used to explain model predictions. Conclusion: Our approach accurately classifies lung nodules as benign or malignant, providing explainable outputs, aiding clinicians in comprehending the underlying meaning of model predictions. This approach also prevents the model from learning shortcuts and generalizes across clinical settings.