 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgVisAgent: Multimodal Agentic Model for Versatile Surgical Visual Enhancement
Paper and Code
Jul 03, 2025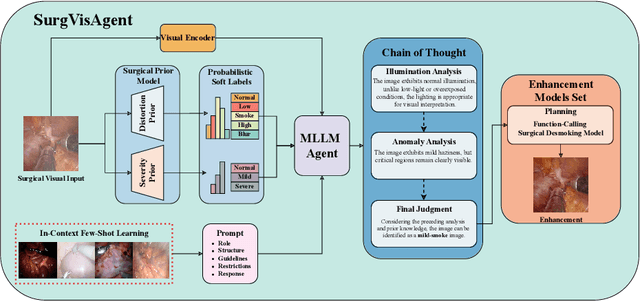
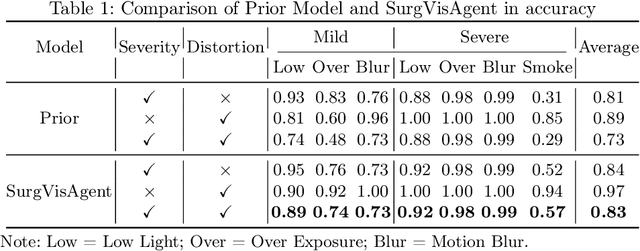
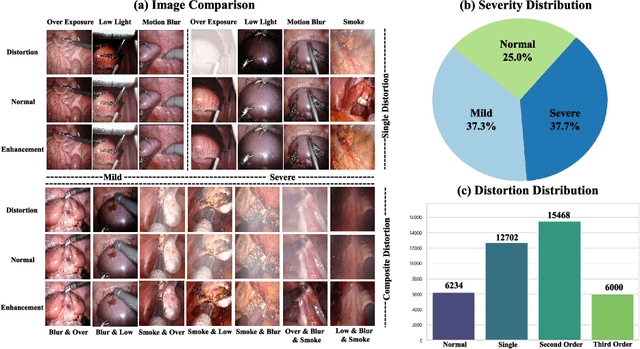
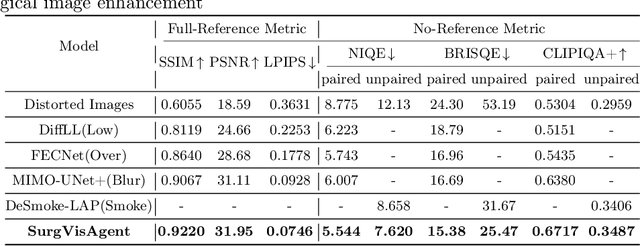
Precise surgical interventions are vital to patient safety, and advanced enhancement algorithms have been developed to assist surgeons in decision-making. Despite significant progress, these algorithms are typically designed for single tasks in specific scenarios, limiting their effectiveness in complex real-world situations. To address this limitation, we propose SurgVisAgent, an end-to-end intelligent surgical vision agent built on multimodal large language models (MLLMs). SurgVisAgent dynamically identifies distortion categories and severity levels in endoscopic images, enabling it to perform a variety of enhancement tasks such as low-light enhancement, overexposure correction, motion blur elimination, and smoke removal. Specifically, to achieve superior surgical scenario understanding, we design a prior model that provides domain-specific knowledge. Additionally, through in-context few-shot learning and chain-of-thought (CoT) reasoning, SurgVisAgent delivers customized image enhancements tailored to a wide range of distortion types and severity levels, thereby addressing the diverse requirements of surgeons. Furthermore, we construct a comprehensive benchmark simulating real-world surgical distortions, on which extensive experiments demonstrate that SurgVisAgent surpasses traditional single-task models, highlighting its potential as a unified solution for surgical assistance.