 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfing: Iterative optimization over incrementally trained deep networks
Paper and Code
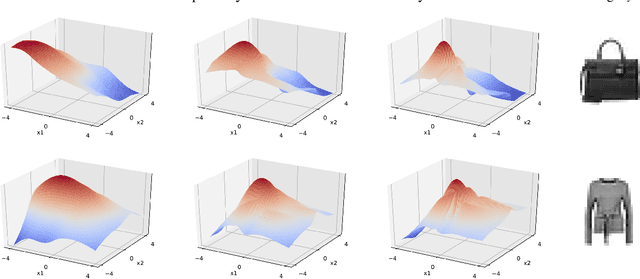
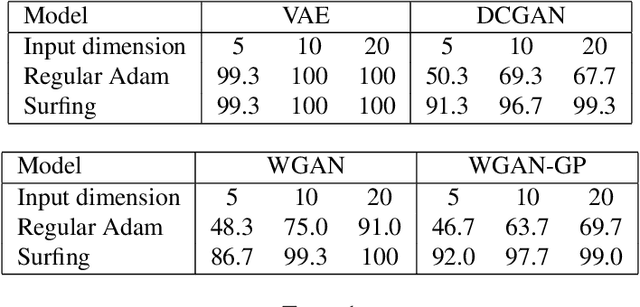
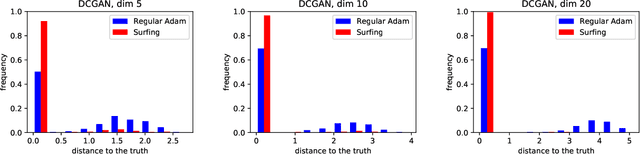
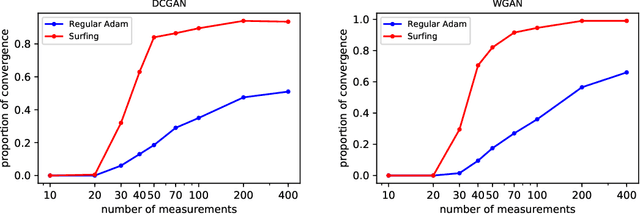
We investigate a sequential optimization procedure to minimize the empirical risk functional $f_{\hat\theta}(x) = \frac{1}{2}\|G_{\hat\theta}(x) - y\|^2$ for certain families of deep networks $G_{\theta}(x)$. The approach is to optimize a sequence of objective functions that use network parameters obtained during different stages of the training process. When initialized with random parameters $\theta_0$, we show that the objective $f_{\theta_0}(x)$ is "nice'' and easy to optimize with gradient descent. As learning is carried out, we obtain a sequence of generative networks $x \mapsto G_{\theta_t}(x)$ and associated risk functions $f_{\theta_t}(x)$, where $t$ indicates a stage of stochastic gradient descent during training. Since the parameters of the network do not change by very much in each step, the surface evolves slowly and can be incrementally optimized. The algorithm is formalized and analyzed for a family of expansive networks. We call the procedure {\it surfing} since it rides along the peak of the evolving (negative) empirical risk function, starting from a smooth surface at the beginning of learning and ending with a wavy nonconvex surface after learning is complete. Experiments show how surfing can be used to find the global optimum and for compressed sensing even when direct gradient descent on the final learned network fails.