 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Controllable Accented TTS
Paper and Code
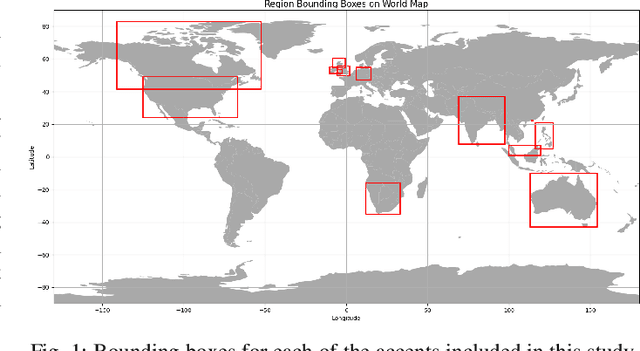
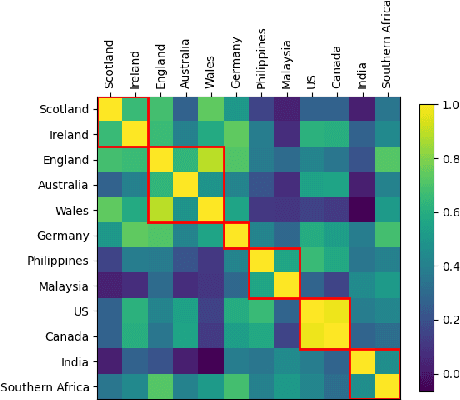
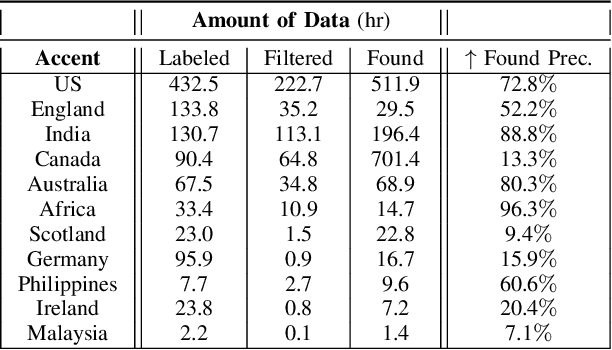

We tackle the challenge of scaling accented TTS systems, expanding their capabilities to include much larger amounts of training data and a wider variety of accent labels, even for accents that are poorly represented or unlabeled in traditional TTS datasets. To achieve this, we employ two strategies: 1. Accent label discovery via a speech geolocation model, which automatically infers accent labels from raw speech data without relying solely on human annotation; 2. Timbre augmentation through kNN voice conversion to increase data diversity and model robustness. These strategies are validated on CommonVoice, where we fine-tune XTTS-v2 for accented TTS with accent labels discovered or enhanced using geolocation. We demonstrate that the resulting accented TTS model not only outperforms XTTS-v2 fine-tuned on self-reported accent labels in CommonVoice, but also existing accented TTS benchmarks.