 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Semantic Grasping Detection
Paper and Code
Nov 20, 2021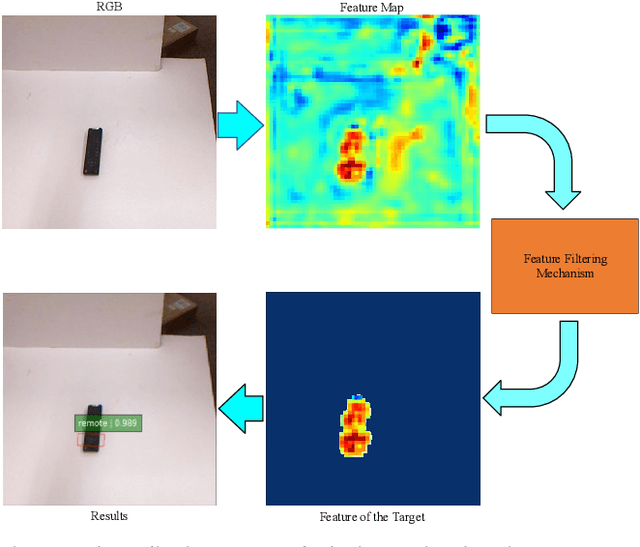
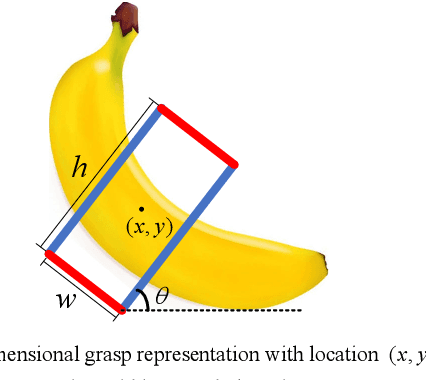
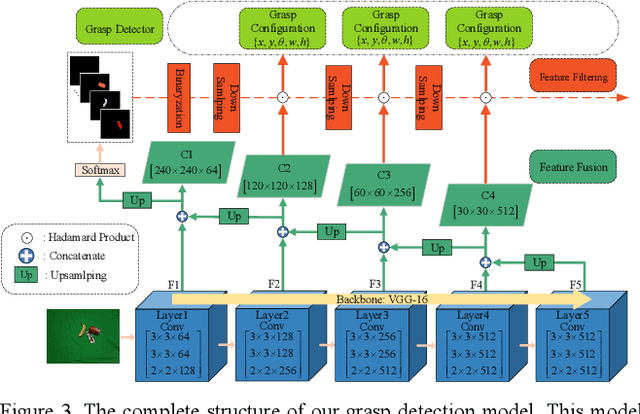

Reducing the scope of grasping detection according to the semantic information of the target is significant to improve the accuracy of the grasping detection model and expand its application. Researchers have been trying to combine these capabilities in an end-to-end network to grasp specific objects in a cluttered scene efficiently. In this paper, we propose an end-to-end semantic grasping detection model, which can accomplish both semantic recognition and grasping detection. And we also design a target feature filtering mechanism, which only maintains the features of a single object according to the semantic information for grasping detection. This method effectively reduces the background features that are weakly correlated to the target object, thus making the features more unique and guaranteeing the accuracy and efficiency of grasping detection. Experimental results show that the proposed method can achieve 98.38% accuracy in Cornell grasping dataset Furthermore, our results on different datasets or evaluation metrics show the domain adaptability of our method over the state-of-the-art.