 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting optimal value functions by interpolating reward functions in scalarized multi-objective reinforcement learning
Paper and Code
Sep 19, 2019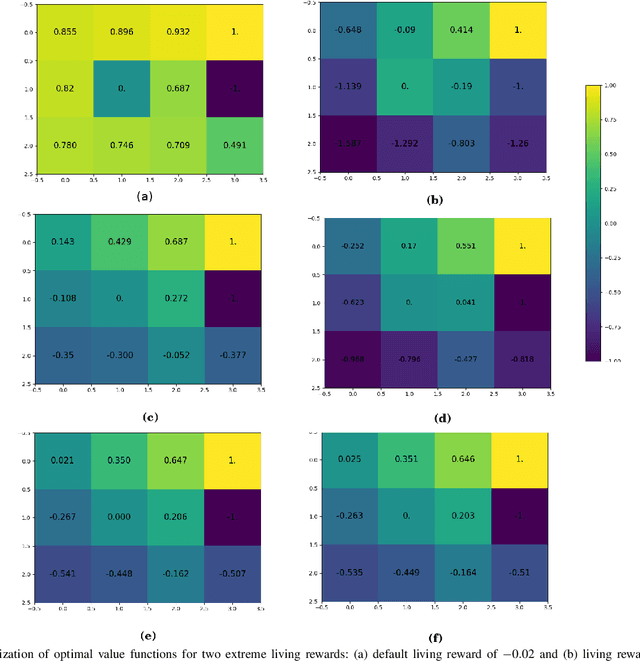
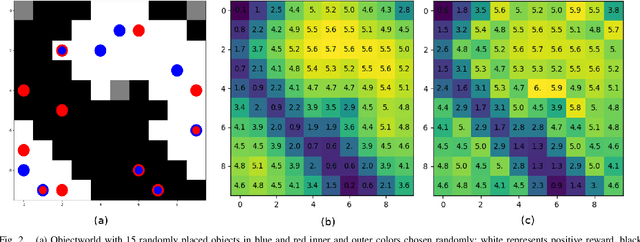
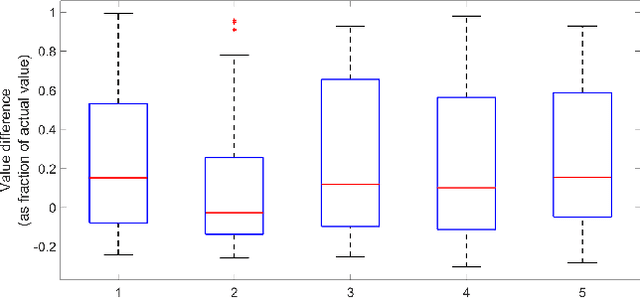

A common approach for defining a reward function for Multi-objective Reinforcement Learning (MORL) problems is the weighted sum of the multiple objectives. The weights are then treated as design parameters dependent on the expertise (and preference) of the person performing the learning, with the typical result that a new solution is required for any change in these settings. This paper investigates the relationship between the reward function and the optimal value function for MORL; specifically addressing the question of how to approximate the optimal value function well beyond the set of weights for which the optimization problem was actually solved, thereby avoiding the need to recompute for any particular choice. We prove that the value function transforms smoothly given a transformation of weights of the reward function (and thus a smooth interpolation in the policy space). A Gaussian process is used to obtain a smooth interpolation over the reward function weights of the optimal value function for three well-known examples: GridWorld, Objectworld and Pendulum. The results show that the interpolation can provide very robust values for sample states and action space in discrete and continuous domain problems. Significant advantages arise from utilizing this interpolation technique in the domain of autonomous vehicles: easy, instant adaptation of user preferences while driving and true randomization of obstacle vehicle behavior preferences during training.