 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
Paper and Code
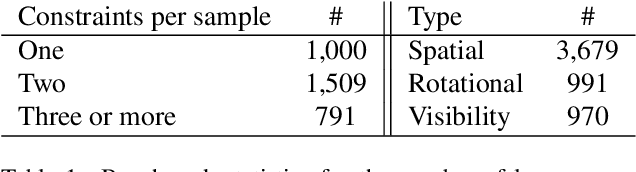
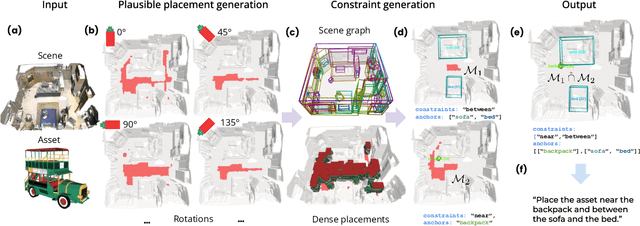
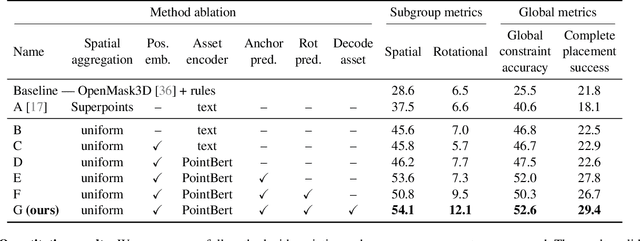
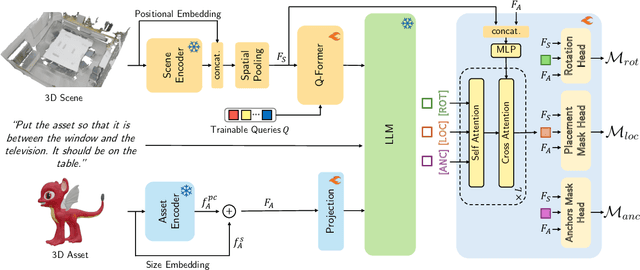
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.