 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC: Pronunciation-Aware Contextualized Large Language Model-based Automatic Speech Recognition
Paper and Code
Sep 16, 2025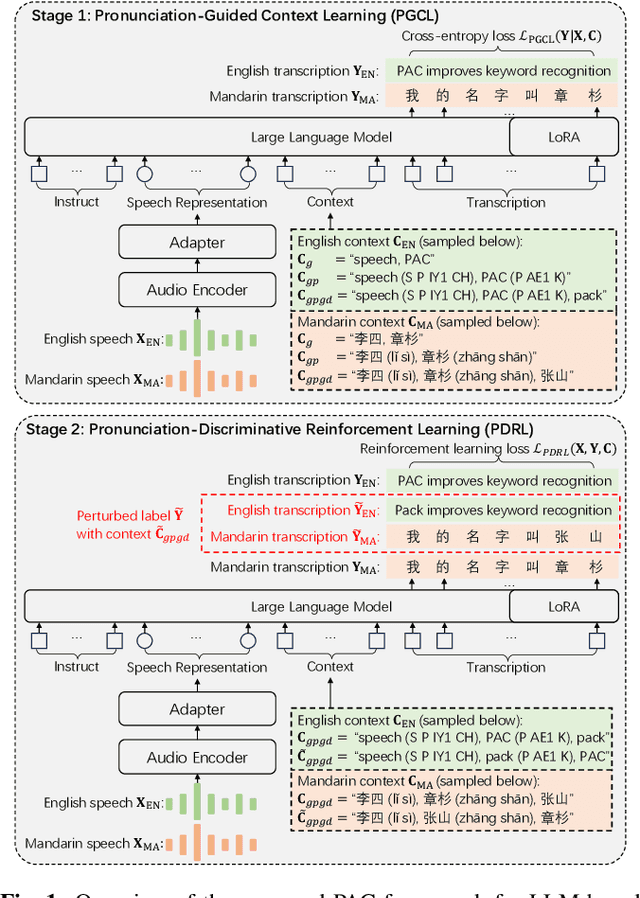



This paper presents a Pronunciation-Aware Contextualized (PAC) framework to address two key challenges in Large Language Model (LLM)-based Automatic Speech Recognition (ASR) systems: effective pronunciation modeling and robust homophone discrimination. Both are essential for raw or long-tail word recognition. The proposed approach adopts a two-stage learning paradigm. First, we introduce a pronunciation-guided context learning method. It employs an interleaved grapheme-phoneme context modeling strategy that incorporates grapheme-only distractors, encouraging the model to leverage phonemic cues for accurate recognition. Then, we propose a pronunciation-discriminative reinforcement learning method with perturbed label sampling to further enhance the model\'s ability to distinguish contextualized homophones. Experimental results on the public English Librispeech and Mandarin AISHELL-1 datasets indicate that PAC: (1) reduces relative Word Error Rate (WER) by 30.2% and 53.8% compared to pre-trained LLM-based ASR models, and (2) achieves 31.8% and 60.5% relative reductions in biased WER for long-tail words compared to strong baselines, respectively.