 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimality of Graphlet Screening in High Dimensional Variable Selection
Paper and Code
Jun 13, 2014


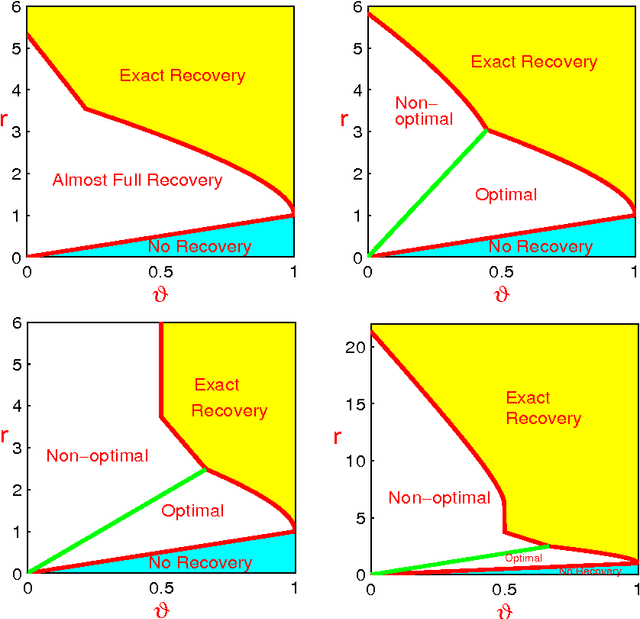
Consider a linear regression model where the design matrix X has n rows and p columns. We assume (a) p is much large than n, (b) the coefficient vector beta is sparse in the sense that only a small fraction of its coordinates is nonzero, and (c) the Gram matrix G = X'X is sparse in the sense that each row has relatively few large coordinates (diagonals of G are normalized to 1). The sparsity in G naturally induces the sparsity of the so-called graph of strong dependence (GOSD). We find an interesting interplay between the signal sparsity and the graph sparsity, which ensures that in a broad context, the set of true signals decompose into many different small-size components of GOSD, where different components are disconnected. We propose Graphlet Screening (GS) as a new approach to variable selection, which is a two-stage Screen and Clean method. The key methodological innovation of GS is to use GOSD to guide both the screening and cleaning. Compared to m-variate brute-forth screening that has a computational cost of p^m, the GS only has a computational cost of p (up to some multi-log(p) factors) in screening. We measure the performance of any variable selection procedure by the minimax Hamming distance. We show that in a very broad class of situations, GS achieves the optimal rate of convergence in terms of the Hamming distance. Somewhat surprisingly, the well-known procedures subset selection and the lasso are rate non-optimal, even in very simple settings and even when their tuning parameters are ideally set.