 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Target Tracking by Learning Feature Representation and Distance Metric Jointly
Paper and Code
Feb 09, 2018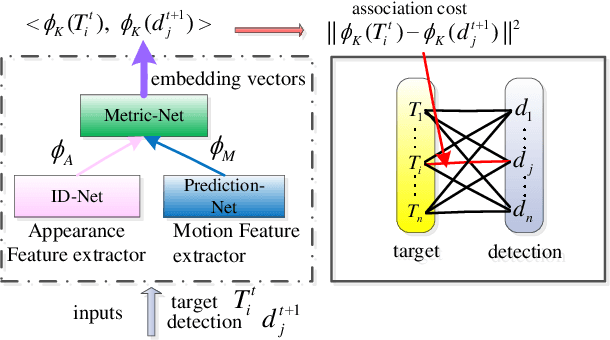
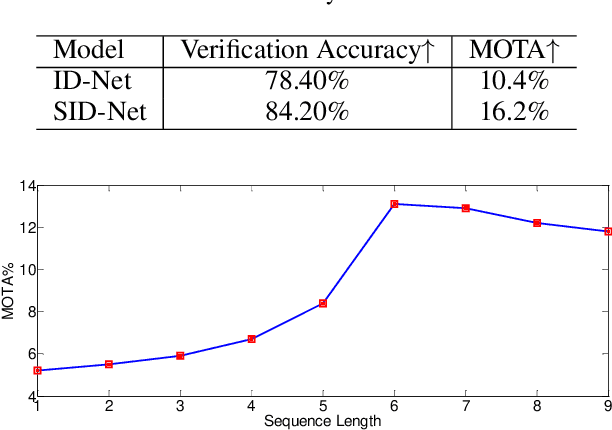
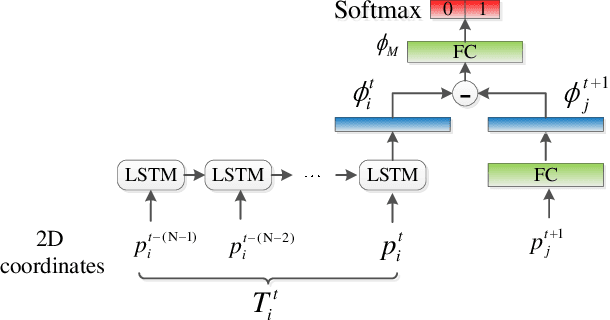
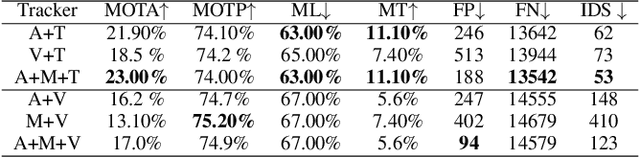
Designing a robust affinity model is the key issue in multiple target tracking (MTT). This paper proposes a novel affinity model by learning feature representation and distance metric jointly in a unified deep architecture. Specifically, we design a CNN network to obtain appearance cue tailored towards person Re-ID, and an LSTM network for motion cue to predict target position, respectively. Both cues are combined with a triplet loss function, which performs end-to-end learning of the fused features in a desired embedding space. Experiments in the challenging MOT benchmark demonstrate, that even by a simple Linear Assignment strategy fed with affinity scores of our method, very competitive results are achieved when compared with the most recent state-of-theart approaches.