 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI-DCCRN-VAE: An Improved Deep Representation Learning Framework for Complex VAE-based Single-channel Speech Enhancement
Paper and Code

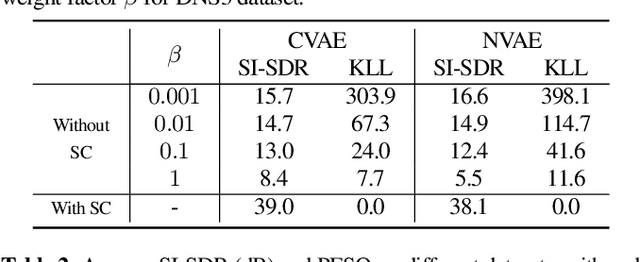
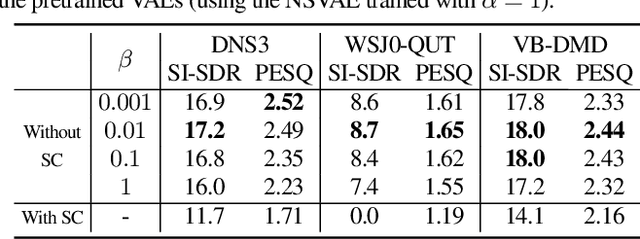

Recently, a complex variational autoencoder (VAE)-based single-channel speech enhancement system based on the DCCRN architecture has been proposed. In this system, a noise suppression VAE (NSVAE) learns to extract clean speech representations from noisy speech using pretrained clean speech and noise VAEs with skip connections. In this paper, we improve DCCRN-VAE by incorporating three key modifications: 1) removing the skip connections in the pretrained VAEs to encourage more informative speech and noise latent representations; 2) using $\beta$-VAE in pretraining to better balance reconstruction and latent space regularization; and 3) a NSVAE generating both speech and noise latent representations. Experiments show that the proposed system achieves comparable performance as the DCCRN and DCCRN-VAE baselines on the matched DNS3 dataset but outperforms the baselines on mismatched datasets (WSJ0-QUT, Voicebank-DEMEND), demonstrating improved generalization ability. In addition, an ablation study shows that a similar performance can be achieved with classical fine-tuning instead of adversarial training, resulting in a simpler training pipeline.