 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Convolutional Reinforcement Learning for Multi-Agent Cooperation
Paper and Code
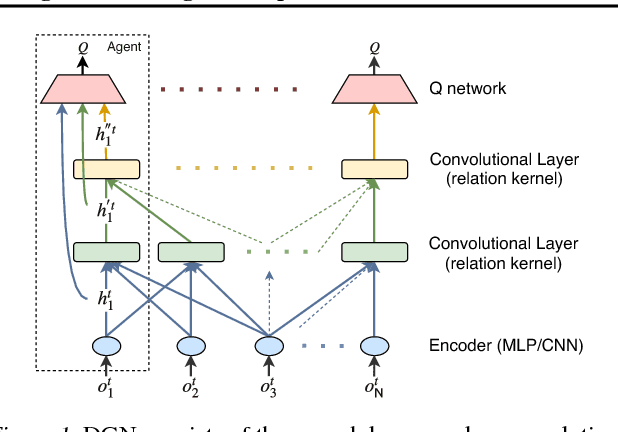
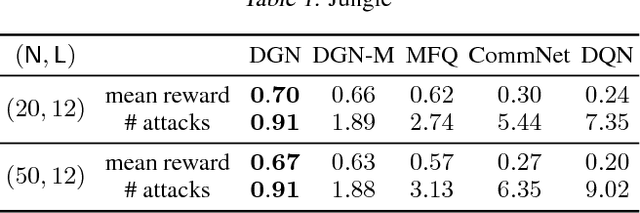
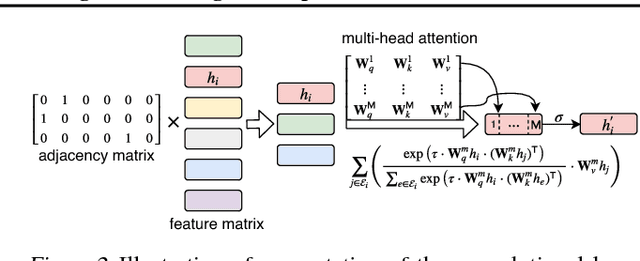
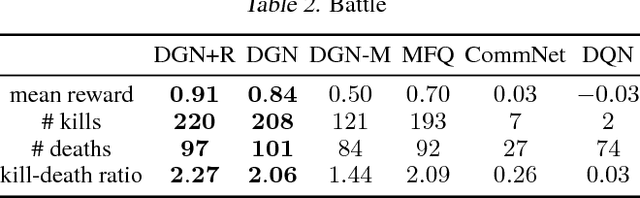
Learning to cooperate is crucially important in multi-agent reinforcement learning. The key is to take the influence of other agents into consideration when performing distributed decision making. However, multi-agent environment is highly dynamic, which makes it hard to learn abstract representations of influences between agents by only low-order features that existing methods exploit. In this paper, we propose a graph convolutional model for multi-agent cooperation. The graph convolution architecture adapts to the dynamics of the underlying graph of the multi-agent environment, where the influence among agents is captured by their abstract relation representations. High-order features extracted by relation kernels of convolutional layers from gradually increased receptive fields are exploited to learn cooperative strategies. The gradient of an agent not only backpropagates to itself but also to other agents in its receptive fields to reinforce the learned cooperative strategies. Moreover, the relation representations are temporally regularized to make the cooperation more consistent. Empirically, we show that our model enables agents to develop more cooperative and sophisticated strategies than existing methods in jungle and battle games and routing in packet switching networks.