 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive Feature Codec: Adaptive Segmentation for Efficient Speech Representation
Paper and Code



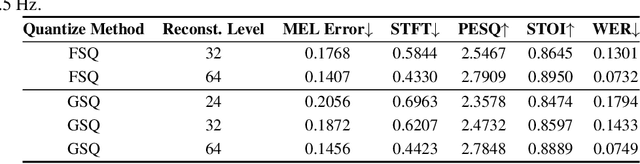
The tokenization of speech with neural speech codec models is a crucial aspect of AI systems designed for speech understanding and generation. While text-based systems naturally benefit from token boundaries between discrete symbols, tokenizing continuous speech signals is more complex due to the unpredictable timing of important acoustic variations. Most current neural speech codecs typically address this by using uniform processing at fixed time intervals, which overlooks the varying information density inherent in speech. In this paper, we introduce a distinctive feature-based approach that dynamically allocates tokens based on the perceptual significance of speech content. By learning to identify and prioritize distinctive regions in speech signals, our approach achieves a significantly more efficient speech representation compared with conventional frame-based methods. This work marks the first successful extension of traditional signal processing-based distinctive features into deep learning frameworks. Through rigorous experimentation, we demonstrate the effectiveness of our approach and provide theoretical insights into how aligning segment boundaries with natural acoustic transitions improves codebook utilization. Additionally, we enhance tokenization stability by developing a Group-wise Scalar Quantization approach for variable-length segments. Our distinctive feature-based approach offers a promising alternative to conventional frame-based processing and advances interpretable representation learning in the modern deep learning speech processing framework.