 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Extract the Semi-transparent Motion-blurred Hand from a Single Image
Paper and Code
Jun 27, 2019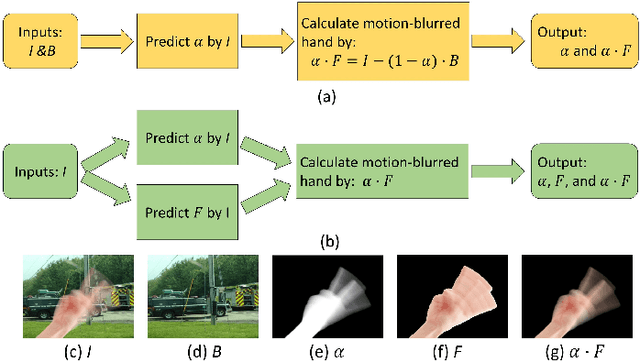
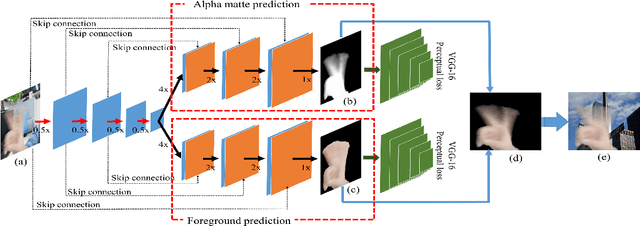


When we use video chat, video game, or other video applications, motion-blurred hands often appear. Accurately extracting these hands is very useful for video editing and behavior analysis. However, existing motion-blurred object extraction methods either need user interactions, such as user supplied trimaps and scribbles, or need additional information, such as background images. In this paper, a novel method which can automatically extract the semi-transparent motion-blurred hand just according to the original RGB image is proposed. The proposed method separates the extraction task into two subtasks: alpha matte prediction and foreground prediction. These two subtasks are implemented by Xception based encoder-decoder networks. The extracted motion-blurred hand images can be calculated by multiplying the predicted alpha mattes and foreground images. Experiments on synthetic and real datasets show that the proposed method has promising performance.