 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen do you need Chain-of-Thought Prompting for ChatGPT?
Paper and Code
Apr 18, 2023
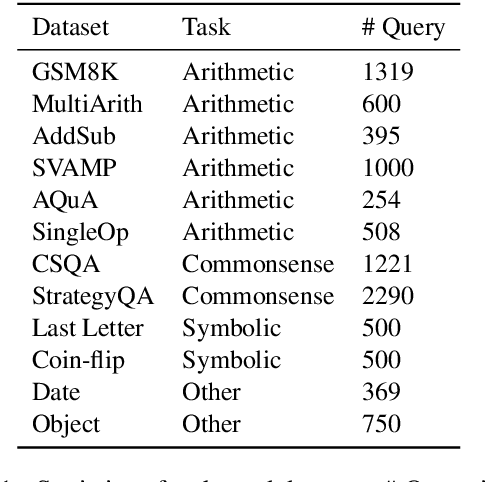
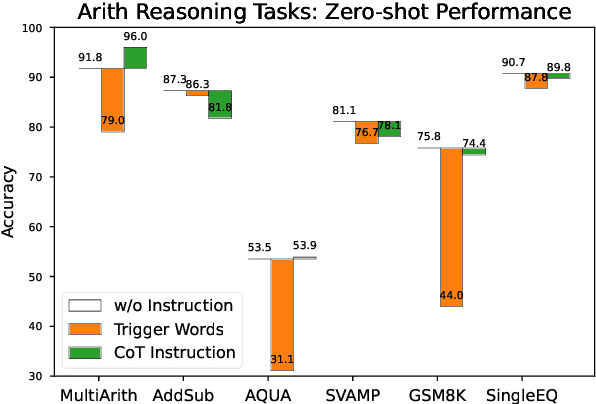
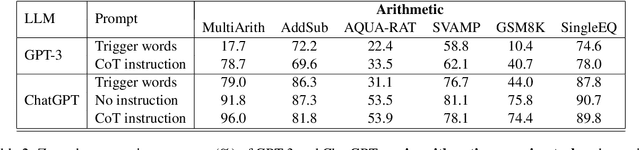
Chain-of-Thought (CoT) prompting can effectively elicit complex multi-step reasoning from Large Language Models~(LLMs). For example, by simply adding CoT instruction ``Let's think step-by-step'' to each input query of MultiArith dataset, GPT-3's accuracy can be improved from 17.7\% to 78.7\%. However, it is not clear whether CoT is still effective on more recent instruction finetuned (IFT) LLMs such as ChatGPT. Surprisingly, on ChatGPT, CoT is no longer effective for certain tasks such as arithmetic reasoning while still keeping effective on other reasoning tasks. Moreover, on the former tasks, ChatGPT usually achieves the best performance and can generate CoT even without being instructed to do so. Hence, it is plausible that ChatGPT has already been trained on these tasks with CoT and thus memorized the instruction so it implicitly follows such an instruction when applied to the same queries, even without CoT. Our analysis reflects a potential risk of overfitting/bias toward instructions introduced in IFT, which becomes more common in training LLMs. In addition, it indicates possible leakage of the pretraining recipe, e.g., one can verify whether a dataset and instruction were used in training ChatGPT. Our experiments report new baseline results of ChatGPT on a variety of reasoning tasks and shed novel insights into LLM's profiling, instruction memorization, and pretraining dataset leakage.