 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the calibration of underrepresented classes in LiDAR-based semantic segmentation
Paper and Code
Oct 13, 2022
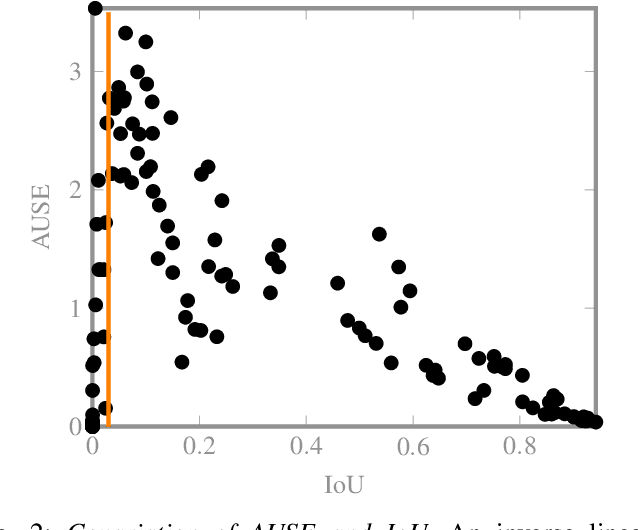
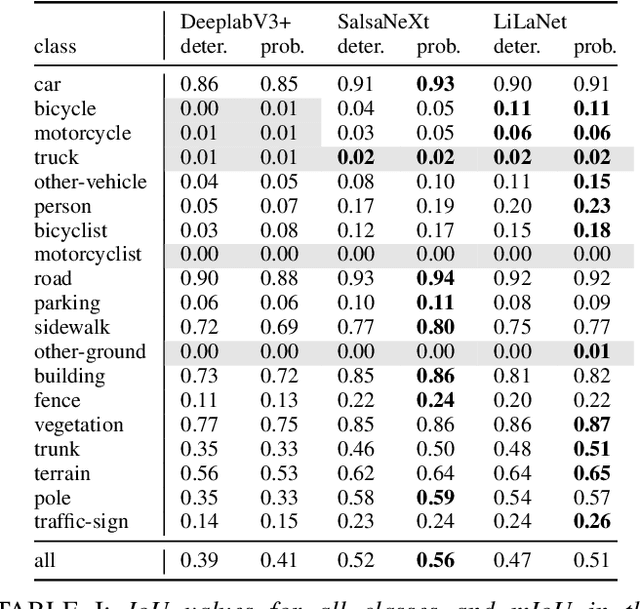
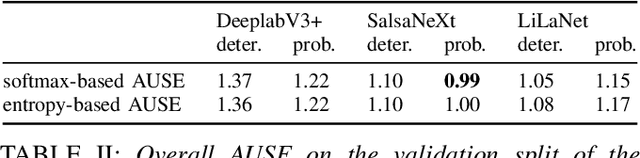
The calibration of deep learning-based perception models plays a crucial role in their reliability. Our work focuses on a class-wise evaluation of several model's confidence performance for LiDAR-based semantic segmentation with the aim of providing insights into the calibration of underrepresented classes. Those classes often include VRUs and are thus of particular interest for safety reasons. With the help of a metric based on sparsification curves we compare the calibration abilities of three semantic segmentation models with different architectural concepts, each in a in deterministic and a probabilistic version. By identifying and describing the dependency between the predictive performance of a class and the respective calibration quality we aim to facilitate the model selection and refinement for safety-critical applications.