 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Multi-intent Spoken Language Understanding with prompting
Paper and Code
Oct 07, 2022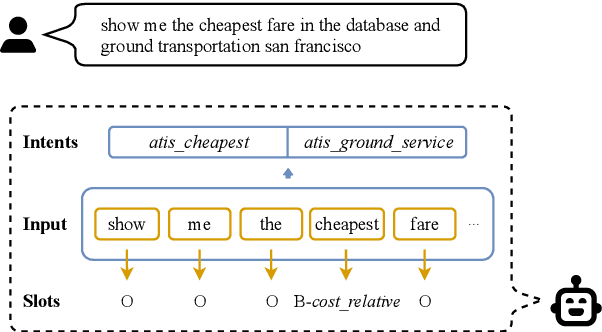
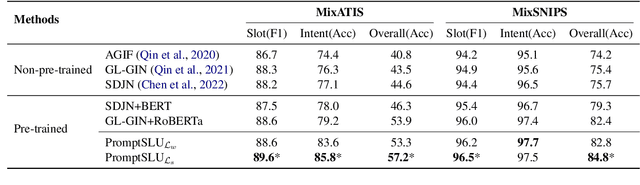
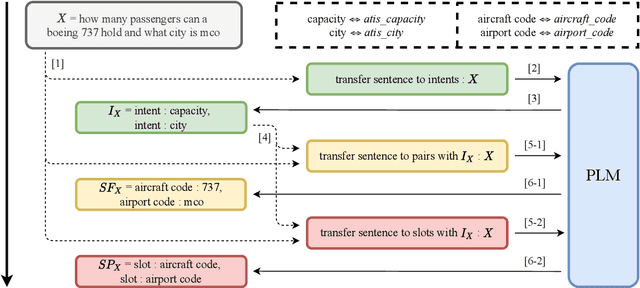
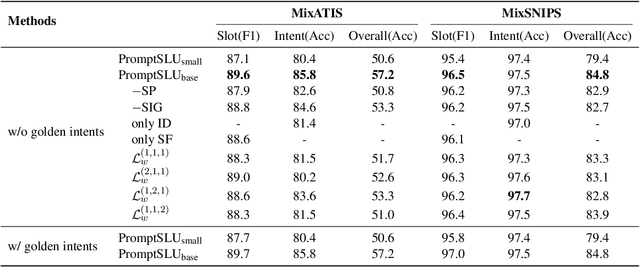
Multi-intent Spoken Language Understanding has great potential for widespread implementation. Jointly modeling Intent Detection and Slot Filling in it provides a channel to exploit the correlation between intents and slots. However, current approaches are apt to formulate these two sub-tasks differently, which leads to two issues: 1) It hinders models from effective extraction of shared features. 2) Pretty complicated structures are involved to enhance expression ability while causing damage to the interpretability of frameworks. In this work, we describe a Prompt-based Spoken Language Understanding (PromptSLU) framework, to intuitively unify two sub-tasks into the same form by offering a common pre-trained Seq2Seq model. In detail, ID and SF are completed by concisely filling the utterance into task-specific prompt templates as input, and sharing output formats of key-value pairs sequence. Furthermore, variable intents are predicted first, then naturally embedded into prompts to guide slot-value pairs inference from a semantic perspective. Finally, we are inspired by prevalent multi-task learning to introduce an auxiliary sub-task, which helps to learn relationships among provided labels. Experiment results show that our framework outperforms several state-of-the-art baselines on two public datasets.