 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Law Parsing with Latent Random Functions
Paper and Code
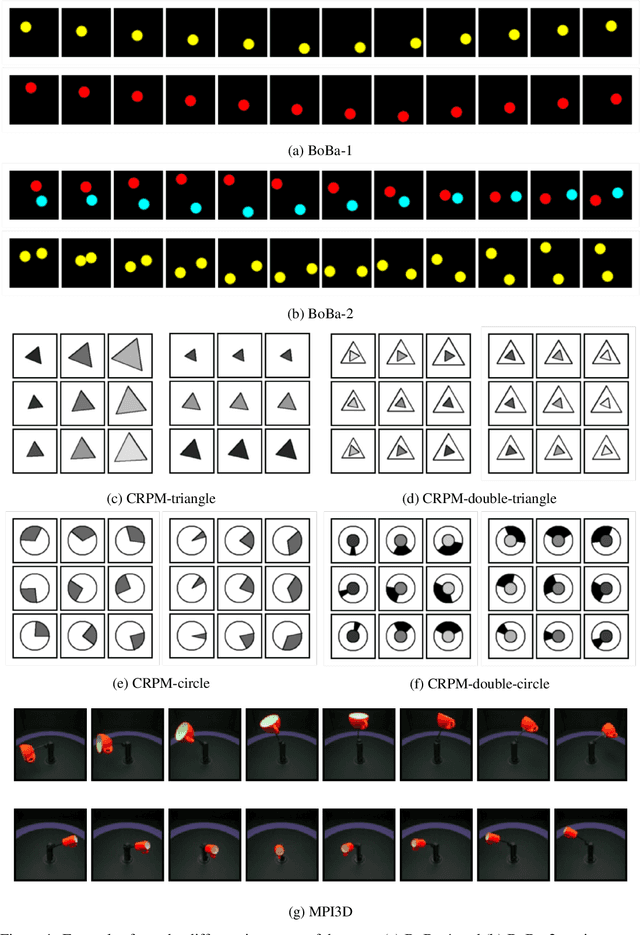
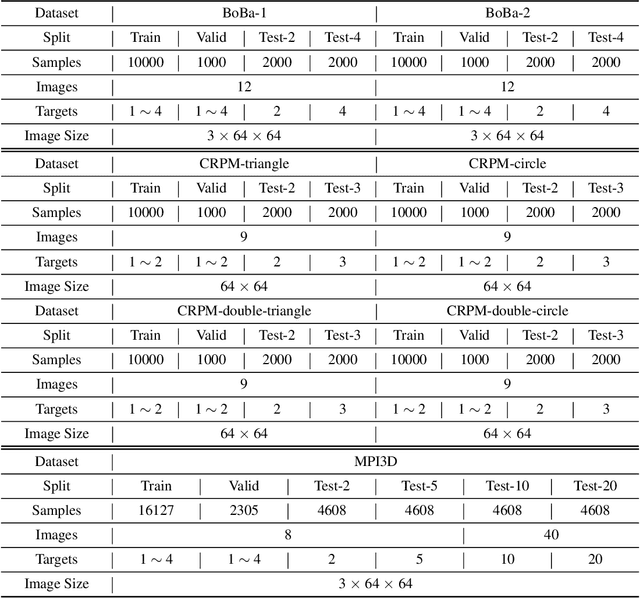
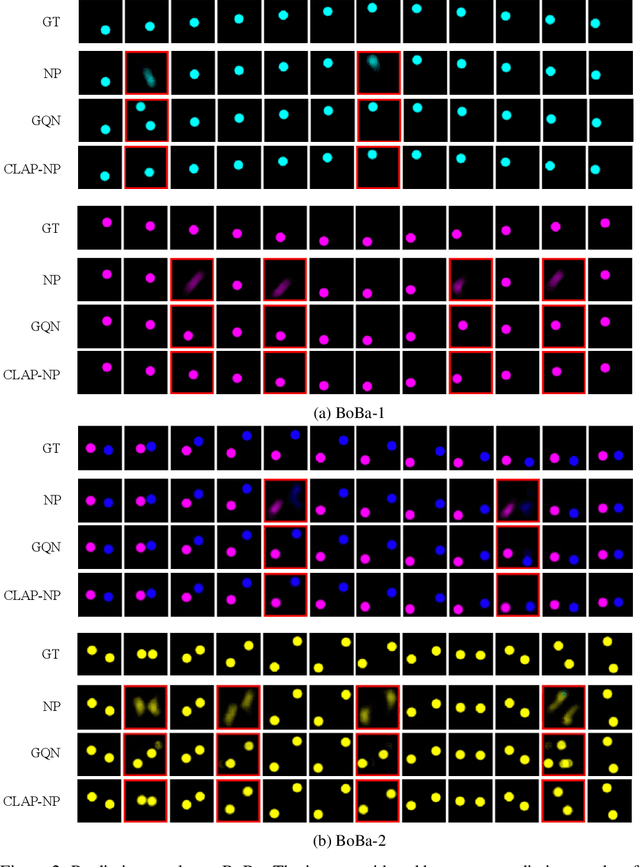
Human cognition has compositionality. We understand a scene by decomposing the scene into different concepts (e.g. shape and position of an object) and learning the respective laws of these concepts which may be either natural (e.g. laws of motion) or man-made (e.g. laws of a game). The automatic parsing of these laws indicates the model's ability to understand the scene, which makes law parsing play a central role in many visual tasks. In this paper, we propose a deep latent variable model for Compositional LAw Parsing (CLAP). CLAP achieves the human-like compositionality ability through an encoding-decoding architecture to represent concepts in the scene as latent variables, and further employ concept-specific random functions, instantiated with Neural Processes, in the latent space to capture the law on each concept. Our experimental results demonstrate that CLAP outperforms the compared baseline methods in multiple visual tasks including intuitive physics, abstract visual reasoning, and scene representation. In addition, CLAP can learn concept-specific laws in a scene without supervision and one can edit laws through modifying the corresponding latent random functions, validating its interpretability and manipulability.