 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies for Improved Lip-reading
Paper and Code
Sep 03, 2022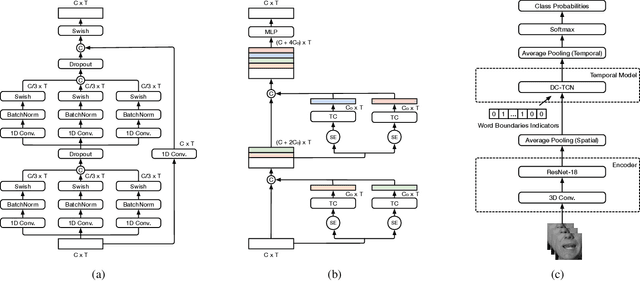
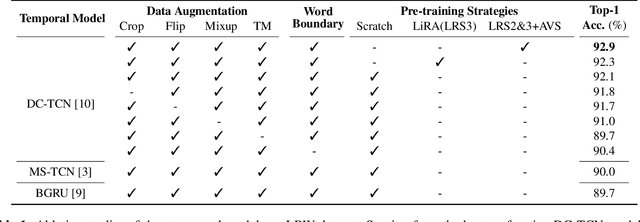
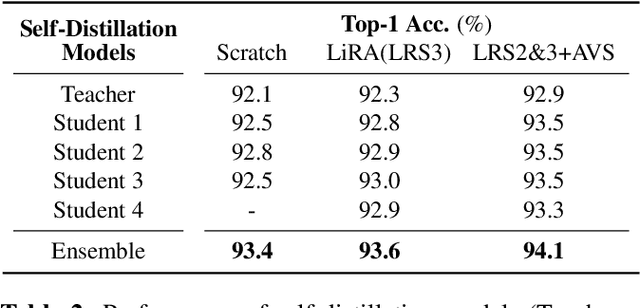
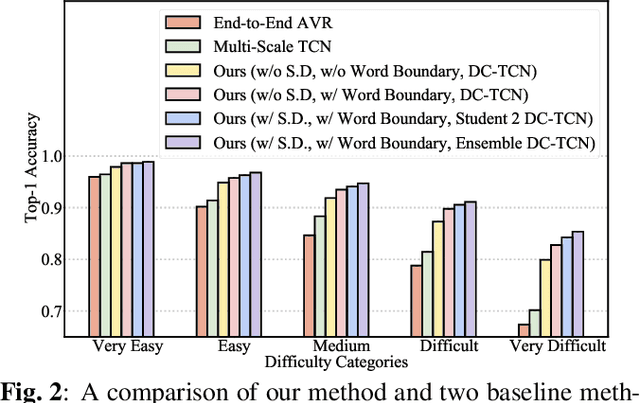
Several training strategies and temporal models have been recently proposed for isolated word lip-reading in a series of independent works. However, the potential of combining the best strategies and investigating the impact of each of them has not been explored. In this paper, we systematically investigate the performance of state-of-the-art data augmentation approaches, temporal models and other training strategies, like self-distillation and using word boundary indicators. Our results show that Time Masking (TM) is the most important augmentation followed by mixup and Densely-Connected Temporal Convolutional Networks (DC-TCN) are the best temporal model for lip-reading of isolated words. Using self-distillation and word boundary indicators is also beneficial but to a lesser extent. A combination of all the above methods results in a classification accuracy of 93.4%, which is an absolute improvement of 4.6% over the current state-of-the-art performance on the LRW dataset. The performance can be further improved to 94.1% by pre-training on additional datasets. An error analysis of the various training strategies reveals that the performance improves by increasing the classification accuracy of hard-to-recognise words.