 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Limits of Poisoning Attacks in Episodic Reinforcement Learning
Paper and Code
Aug 29, 2022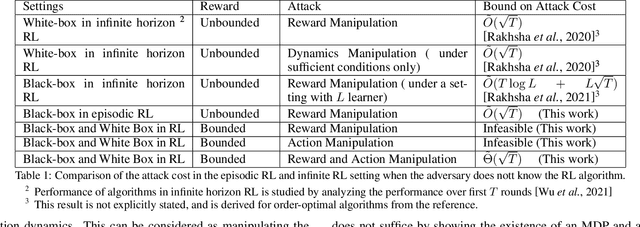
To understand the security threats to reinforcement learning (RL) algorithms, this paper studies poisoning attacks to manipulate \emph{any} order-optimal learning algorithm towards a targeted policy in episodic RL and examines the potential damage of two natural types of poisoning attacks, i.e., the manipulation of \emph{reward} and \emph{action}. We discover that the effect of attacks crucially depend on whether the rewards are bounded or unbounded. In bounded reward settings, we show that only reward manipulation or only action manipulation cannot guarantee a successful attack. However, by combining reward and action manipulation, the adversary can manipulate any order-optimal learning algorithm to follow any targeted policy with $\tilde{\Theta}(\sqrt{T})$ total attack cost, which is order-optimal, without any knowledge of the underlying MDP. In contrast, in unbounded reward settings, we show that reward manipulation attacks are sufficient for an adversary to successfully manipulate any order-optimal learning algorithm to follow any targeted policy using $\tilde{O}(\sqrt{T})$ amount of contamination. Our results reveal useful insights about what can or cannot be achieved by poisoning attacks, and are set to spur more works on the design of robust RL algorithms.