 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Paper and Code
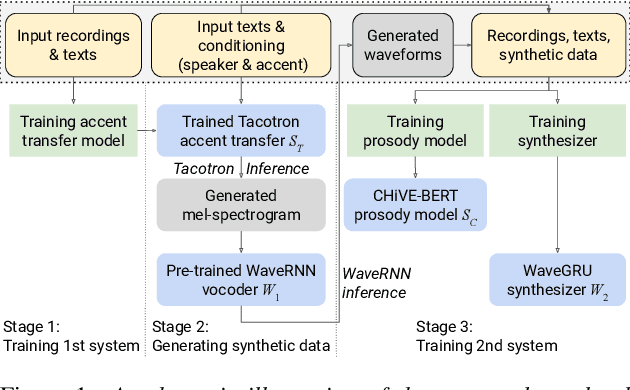
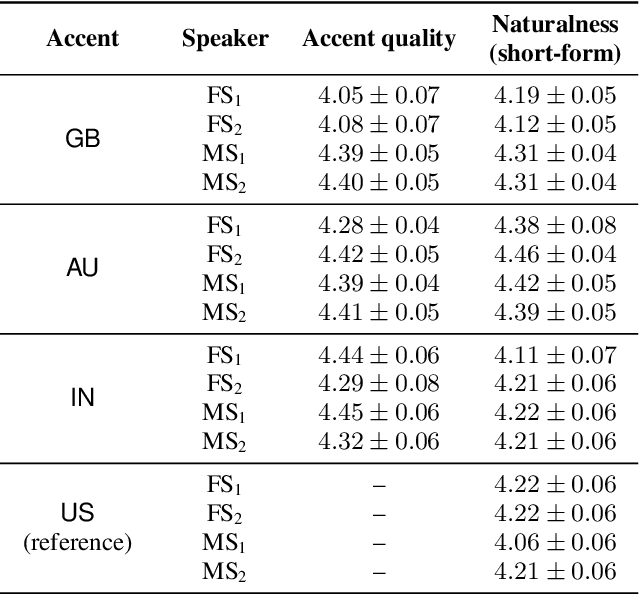
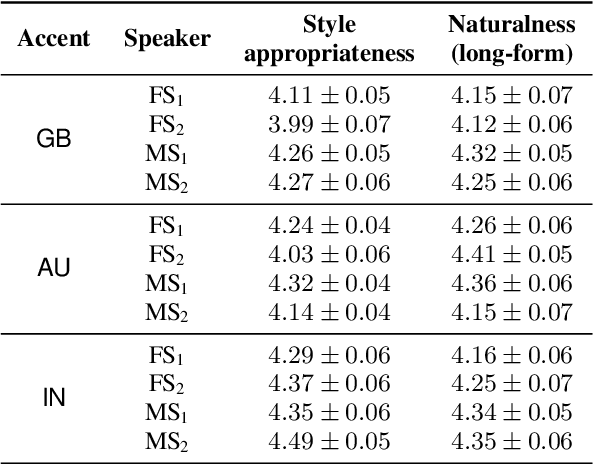
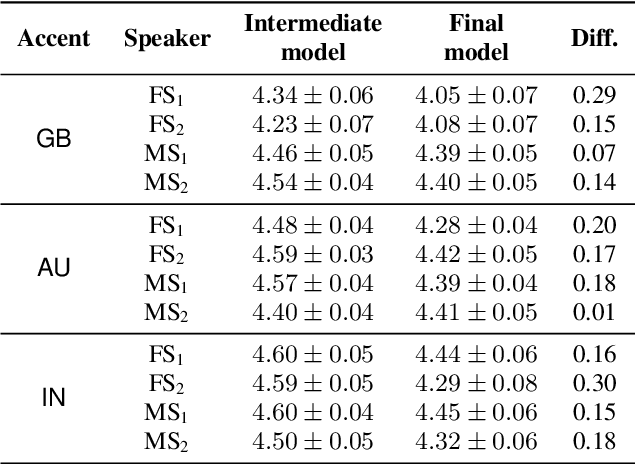
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.