 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
Paper and Code

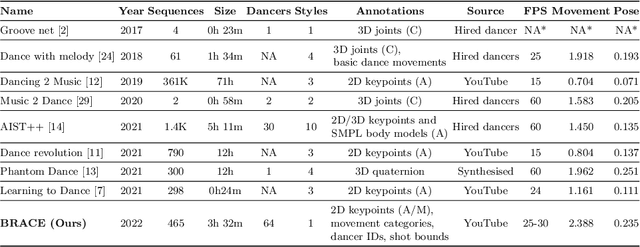


Generative models for audio-conditioned dance motion synthesis map music features to dance movements. Models are trained to associate motion patterns to audio patterns, usually without an explicit knowledge of the human body. This approach relies on a few assumptions: strong music-dance correlation, controlled motion data and relatively simple poses and movements. These characteristics are found in all existing datasets for dance motion synthesis, and indeed recent methods can achieve good results.We introduce a new dataset aiming to challenge these common assumptions, compiling a set of dynamic dance sequences displaying complex human poses. We focus on breakdancing which features acrobatic moves and tangled postures. We source our data from the Red Bull BC One competition videos. Estimating human keypoints from these videos is difficult due to the complexity of the dance, as well as the multiple moving cameras recording setup. We adopt a hybrid labelling pipeline leveraging deep estimation models as well as manual annotations to obtain good quality keypoint sequences at a reduced cost. Our efforts produced the BRACE dataset, which contains over 3 hours and 30 minutes of densely annotated poses. We test state-of-the-art methods on BRACE, showing their limitations when evaluated on complex sequences. Our dataset can readily foster advance in dance motion synthesis. With intricate poses and swift movements, models are forced to go beyond learning a mapping between modalities and reason more effectively about body structure and movements.