Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic Role Contextualized Video Features for Multi-Instance Text-Video Retrieval EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Paper and Code
Jun 29, 2022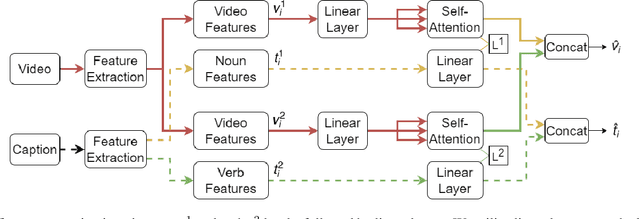
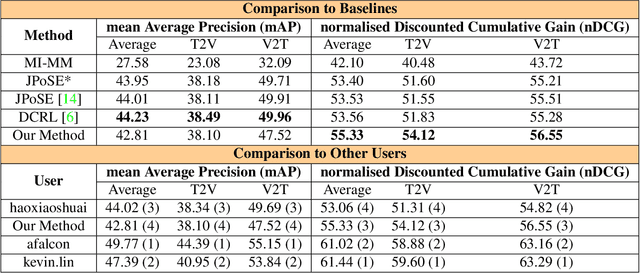
In this report, we present our approach for EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022. We first parse sentences into semantic roles corresponding to verbs and nouns; then utilize self-attentions to exploit semantic role contextualized video features along with textual features via triplet losses in multiple embedding spaces. Our method overpasses the strong baseline in normalized Discounted Cumulative Gain (nDCG), which is more valuable for semantic similarity. Our submission is ranked 3rd for nDCG and ranked 4th for mAP.
* Ranked joint 3rd place in the Multi-Instance Retrieval Challenge at
EPIC@CVPR2022
View paper on