 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Speaker Representation Framework for One-shot Singing Voice Conversion
Paper and Code
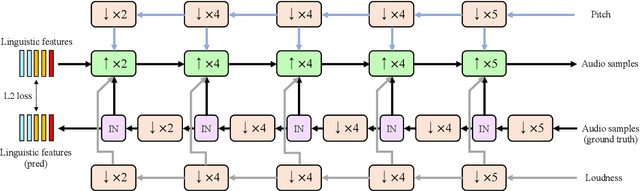
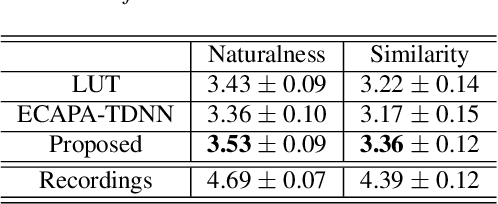
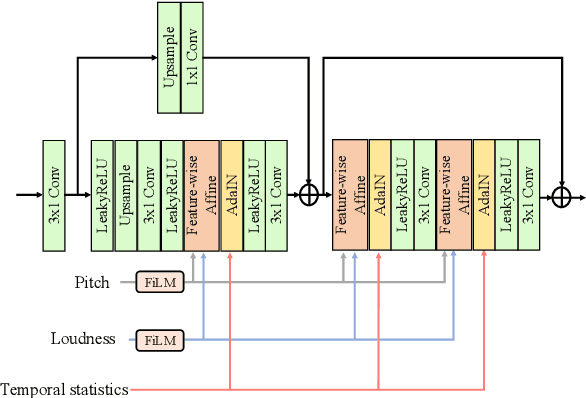
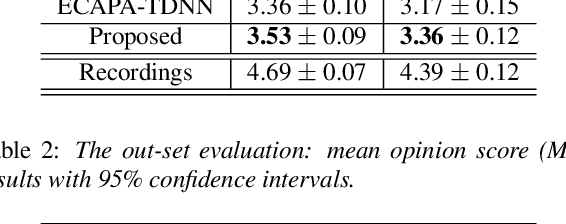
Typically, singing voice conversion (SVC) depends on an embedding vector, extracted from either a speaker lookup table (LUT) or a speaker recognition network (SRN), to model speaker identity. However, singing contains more expressive speaker characteristics than conversational speech. It is suspected that a single embedding vector may only capture averaged and coarse-grained speaker characteristics, which is insufficient for the SVC task. To this end, this work proposes a novel hierarchical speaker representation framework for SVC, which can capture fine-grained speaker characteristics at different granularity. It consists of an up-sampling stream and three down-sampling streams. The up-sampling stream transforms the linguistic features into audio samples, while one down-sampling stream of the three operates in the reverse direction. It is expected that the temporal statistics of each down-sampling block can represent speaker characteristics at different granularity, which will be engaged in the up-sampling blocks to enhance the speaker modeling. Experiment results verify that the proposed method outperforms both the LUT and SRN based SVC systems. Moreover, the proposed system supports the one-shot SVC with only a few seconds of reference audio.