 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCoVQA: Temporal Distortion-Content Transformers for Video Quality Assessment
Paper and Code
Jun 20, 2022
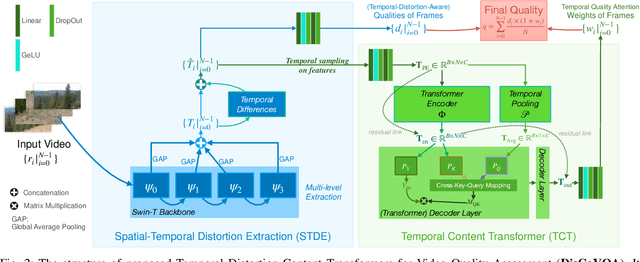
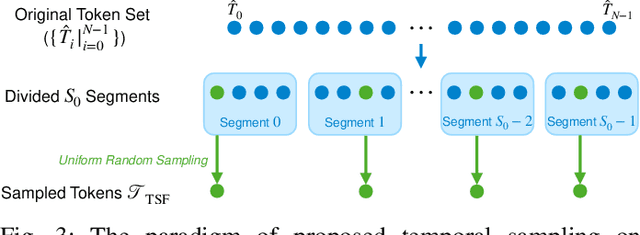
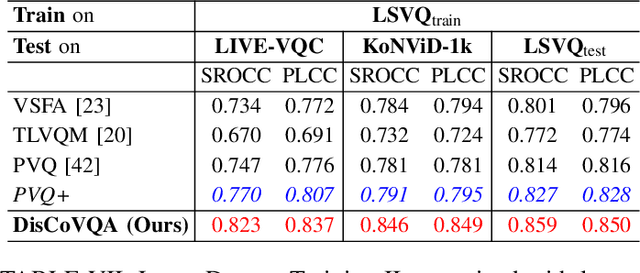
The temporal relationships between frames and their influences on video quality assessment (VQA) are still under-studied in existing works. These relationships lead to two important types of effects for video quality. Firstly, some temporal variations (such as shaking, flicker, and abrupt scene transitions) are causing temporal distortions and lead to extra quality degradations, while other variations (e.g. those related to meaningful happenings) do not. Secondly, the human visual system often has different attention to frames with different contents, resulting in their different importance to the overall video quality. Based on prominent time-series modeling ability of transformers, we propose a novel and effective transformer-based VQA method to tackle these two issues. To better differentiate temporal variations and thus capture the temporal distortions, we design a transformer-based Spatial-Temporal Distortion Extraction (STDE) module. To tackle with temporal quality attention, we propose the encoder-decoder-like temporal content transformer (TCT). We also introduce the temporal sampling on features to reduce the input length for the TCT, so as to improve the learning effectiveness and efficiency of this module. Consisting of the STDE and the TCT, the proposed Temporal Distortion-Content Transformers for Video Quality Assessment (DisCoVQA) reaches state-of-the-art performance on several VQA benchmarks without any extra pre-training datasets and up to 10% better generalization ability than existing methods. We also conduct extensive ablation experiments to prove the effectiveness of each part in our proposed model, and provide visualizations to prove that the proposed modules achieve our intention on modeling these temporal issues. We will publish our codes and pretrained weights later.