 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Zero Constraint Violation for Constrained Reinforcement Learning via Conservative Natural Policy Gradient Primal-Dual Algorithm
Paper and Code
Jun 12, 2022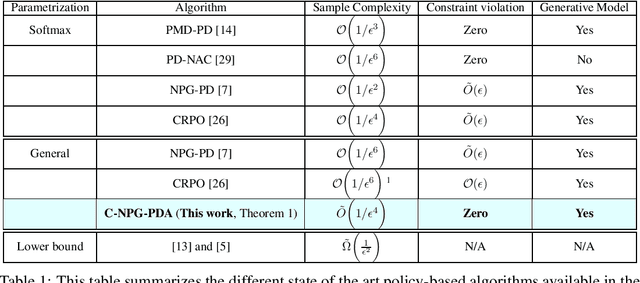
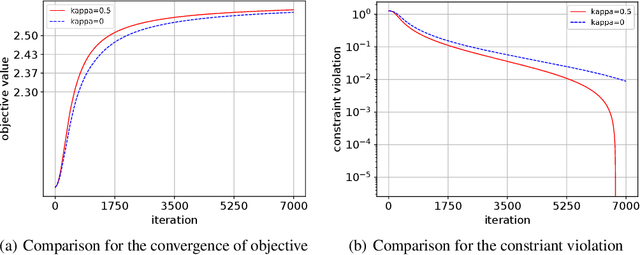
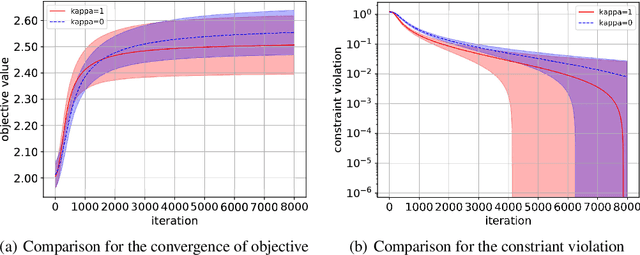
We consider the problem of constrained Markov decision process (CMDP) in continuous state-actions spaces where the goal is to maximize the expected cumulative reward subject to some constraints. We propose a novel Conservative Natural Policy Gradient Primal-Dual Algorithm (C-NPG-PD) to achieve zero constraint violation while achieving state of the art convergence results for the objective value function. For general policy parametrization, we prove convergence of value function to global optimal upto an approximation error due to restricted policy class. We even improve the sample complexity of existing constrained NPG-PD algorithm \cite{Ding2020} from $\mathcal{O}(1/\epsilon^6)$ to $\mathcal{O}(1/\epsilon^4)$. To the best of our knowledge, this is the first work to establish zero constraint violation with Natural policy gradient style algorithms for infinite horizon discounted CMDPs. We demonstrate the merits of proposed algorithm via experimental evaluations.