 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Optimization of Machine Learning Prediction Queries
Paper and Code
May 31, 2022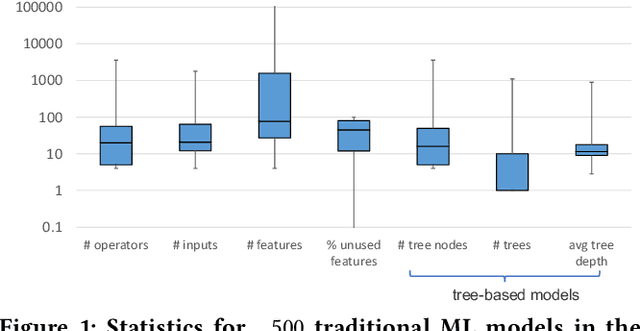
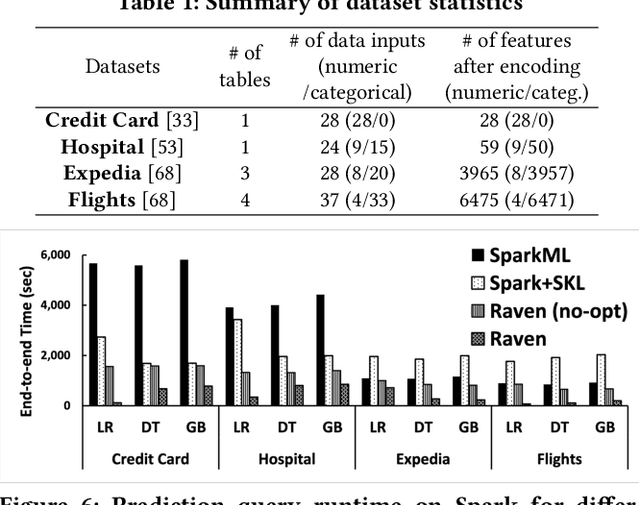
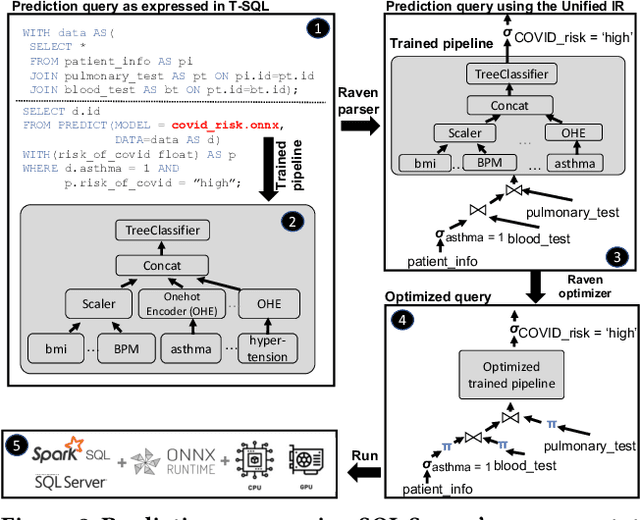
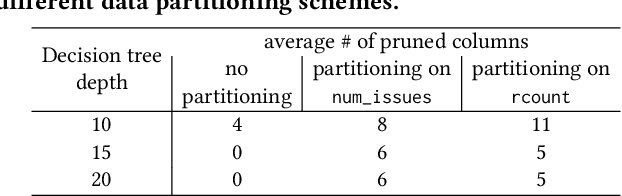
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.