 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientViT: Enhanced Linear Attention for High-Resolution Low-Computation Visual Recognition
Paper and Code
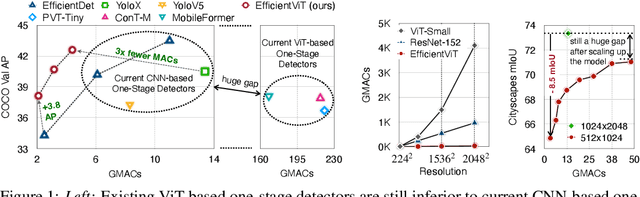
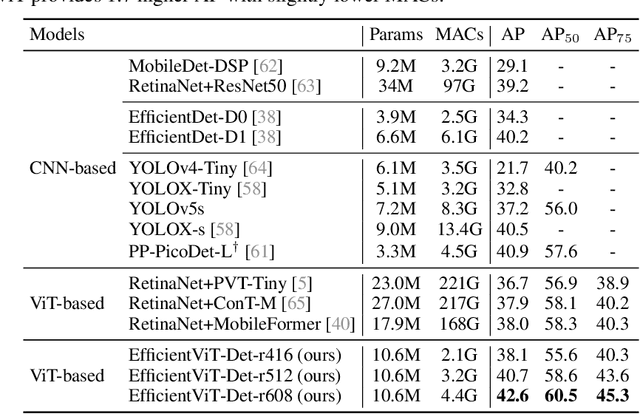
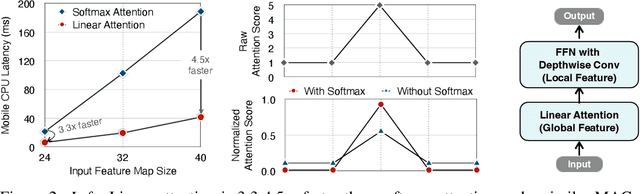
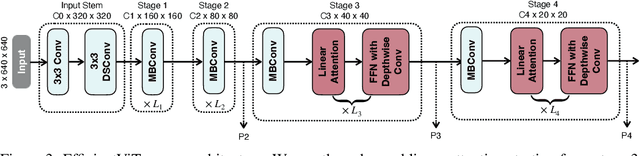
Vision Transformer (ViT) has achieved remarkable performance in many vision tasks. However, ViT is inferior to convolutional neural networks (CNNs) when targeting high-resolution mobile vision applications. The key computational bottleneck of ViT is the softmax attention module which has quadratic computational complexity with the input resolution. It is essential to reduce the cost of ViT to deploy it on edge devices. Existing methods (e.g., Swin, PVT) restrict the softmax attention within local windows or reduce the resolution of key/value tensors to reduce the cost, which sacrifices ViT's core advantages on global feature extractions. In this work, we present EfficientViT, an efficient ViT architecture for high-resolution low-computation visual recognition. Instead of restricting the softmax attention, we propose to replace softmax attention with linear attention while enhancing its local feature extraction ability with depthwise convolution. EfficientViT maintains global and local feature extraction capability while enjoying linear computational complexity. Extensive experiments on COCO object detection and Cityscapes semantic segmentation demonstrate the effectiveness of our method. On the COCO dataset, EfficientViT achieves 42.6 AP with 4.4G MACs, surpassing EfficientDet-D1 by 2.4 AP while having 27.9% fewer MACs. On Cityscapes, EfficientViT reaches 78.7 mIoU with 19.1G MACs, outperforming SegFormer by 2.5 mIoU while requiring less than 1/3 the computational cost. On Qualcomm Snapdragon 855 CPU, EfficientViT is 3x faster than EfficientNet while achieving higher ImageNet accuracy.